









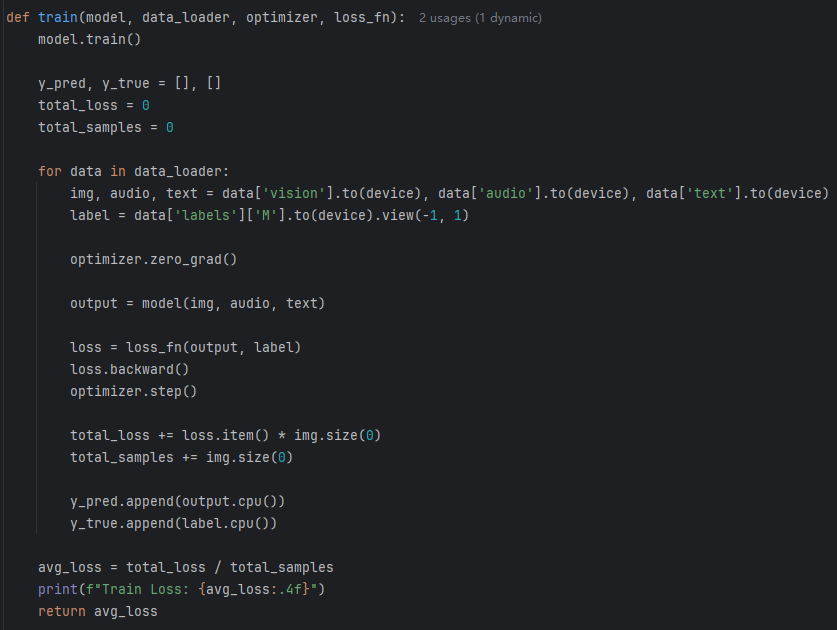
1、方法简介
在本设计中,首先采用了Transformer模块分别对文本、音频和图像特征进行特征编码,然后将通过文本在多个尺度上的特征对图像、音频进行自适应注意力交互,最后将通过交叉注意力进行特征融合。
特征编码模块:分别使用BERT、Librosa和OpenFace提取文本,音频和图像的初始特征。然后将每个模态特征进行编码。有效的减少了与情感不相关的冗余信息,并且降低了参数量。
多尺度自适应注意力模块:通过多尺度语言特征指导超模态学习,确保视觉和音频信息能有效补充语言特征,提高 MSA 的鲁棒性和准确性。自适应注意力机制使视觉和音频模态的信息能更好地适应语言模态,从而减少无关或冲突的信息。
交叉注意力融合模块:通过交叉注意力对模态特征进行融合,将高尺度特征作为Q向量,将经过多尺度自适应注意力模块的特征作为K和V向量。
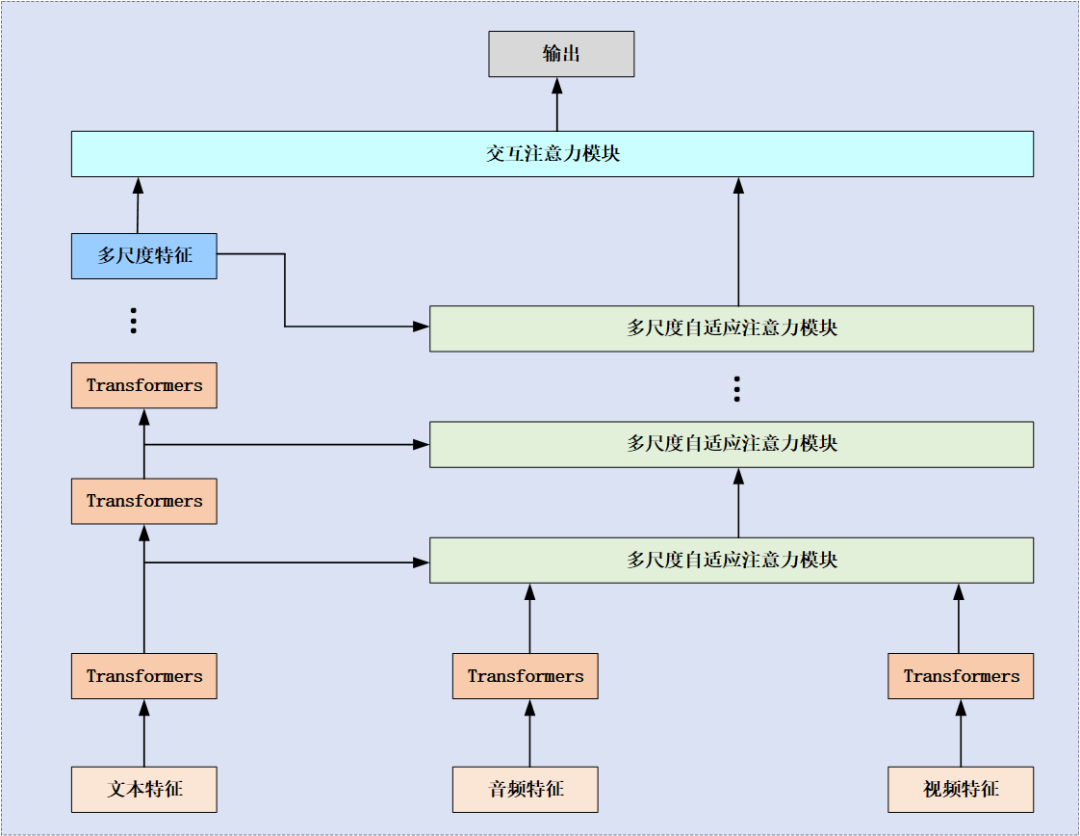
(1)特征编码模块
对于未对齐的模态特征,经过线性映射,得到相同维度的特征,然后通过Transformers编码器进行特征增强。Transformer编码器是模型的第一部分,负责从输入序列中提取全局特征。其核心是自注意力机制和前馈网络。Transformer通过自注意力机制捕获序列中每个位置的全局依赖关系。核心公式如下:注意力机制核心公式如下:
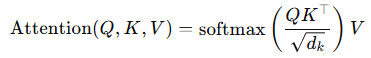
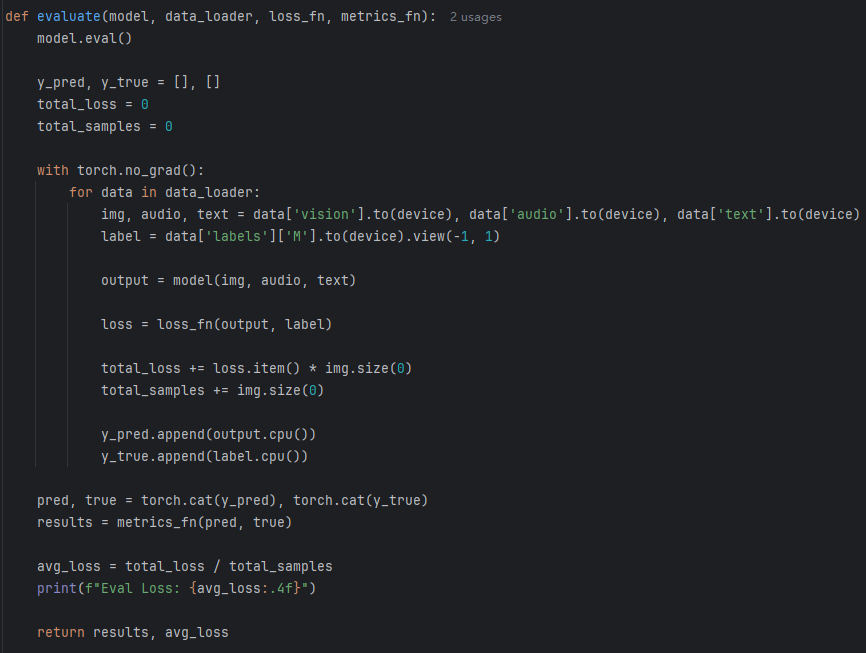
(2)多尺度自适应注意力模块
将经过编码的文本模态数据进行拼接得到低尺度语言特征。然后经过两个Transformer编码层提取得到中、高尺度语言特征。在获取不同尺度的语言特征后,通过自适应注意力机制学习模态特征表示。
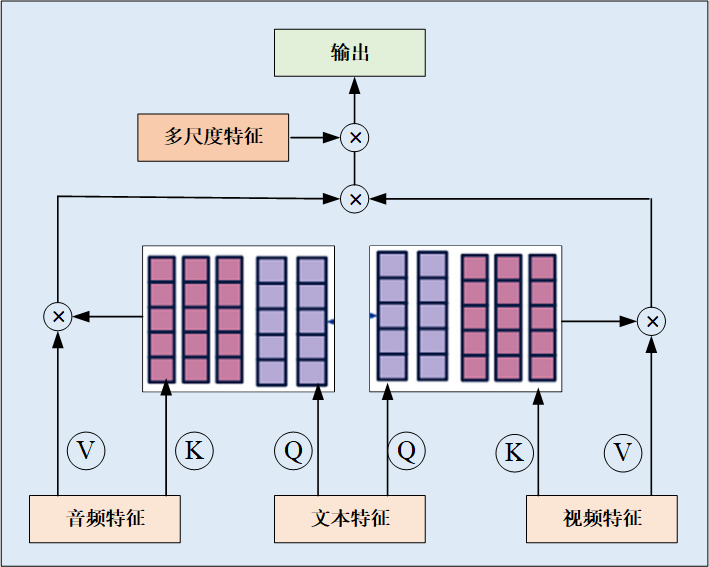
(3)多模态特征融合
使用了交叉注意力机制来实现特征交互。
![[2025/3/18]scaled_dot_product_attention(SDPA)简介](https://i-blog.csdnimg.cn/img_convert/caacebc1d3407af9e53f4fd8642ce6e2.png)
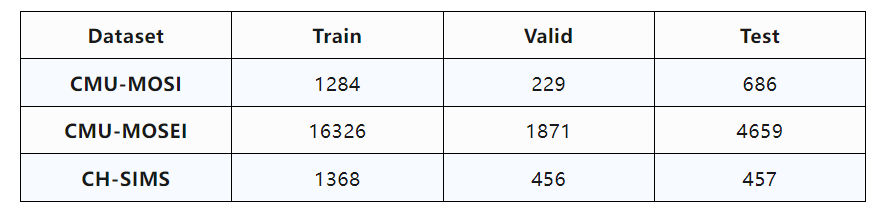
2、数据集介绍
(1)下载地址
https://multibench.readthedocs.io/en/latest/start/datadownload.html
https://gitee.com/vigosser/ch-sims
(2)模态介绍
CMU-MOSI、CMU-MOSEI和CH-SIMS数据集的模态有3种(语言,视觉,声音),数据集使用的是未对齐原始raw数据特征。
(3)标签介绍
CMU-MOSI和CMU-MOSEI:情感标注是对每句话的7分类的情感标注,作者还提供了了2/5/7分类的标注。情绪标注是包含高兴,悲伤,生气,恐惧,厌恶,惊讶六个方面的情绪标注。数据集是多标签特性,即每一个样本对应的情绪可能不止一种,对应情绪的强弱也不同,在[-3~3]之间。
CH-SIMS:情感标注是对每句话的5分类的情感标注,作者还提供了了2/3/5分类的标注。数据集是多标签特性,即每一个样本对应的情绪可能不止一种,对应情绪的强弱也不同,在[-1~1]之间。
(4)评价标准
CMU-MOSI和CMU-MOSEI:均方误差(MSE)、平均绝对误差(MAE)、Pearson相关性(Corr)、二元精度(Acc-2)、F-Score(F1)和多级精度(Acc-7和Acc5)范围从-3到3。对于除MAE以外的所有指标,相对较高的值表示较好的任务性能。本质上,提出了两种不同的方法来测量Acc-2和F1。在第一种,负类的标注范围为[-3,0),而非负类的标注范围为[0,3]。第二种,负类和正类的范围分别为[-3,0)和(0,3]。CH-SIMS:MSE、MAE、Corr、F1、Acc2、Acc3和Acc5。
3、代码示例
4、运行结果
以CMU-MOSI、CMU-MOSEI和CH-SIMS为例,在测试集上的结果分别如下:
MOSI
Acc7:0.4504
Acc5:0.4971
Acc2:0.8134/0.830
F1:0.8138/0.8506
MAE:0.7571
Corr:0.7699
MOSEI
Acc7::0.5209
Acc5:0.536
Acc2:0.8197/0.8517
F1:0.8158/0.8525
MAE:0.5464
Corr:0.7051
SIMS
Acc5:0.4158
Acc3:0.6521
Acc2:0.7834
F1:0.7823
MAE:0.4251
Corr:0.5749
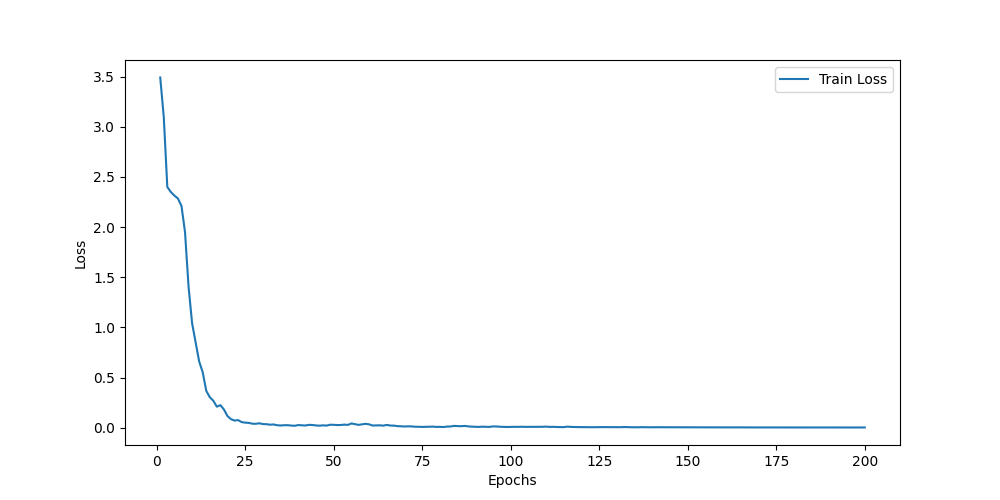
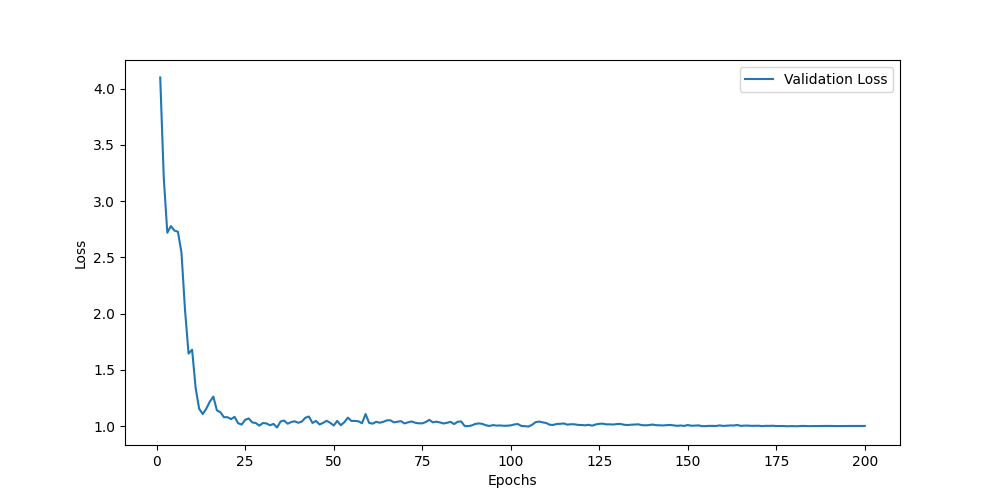

CMU-MOSI数据集
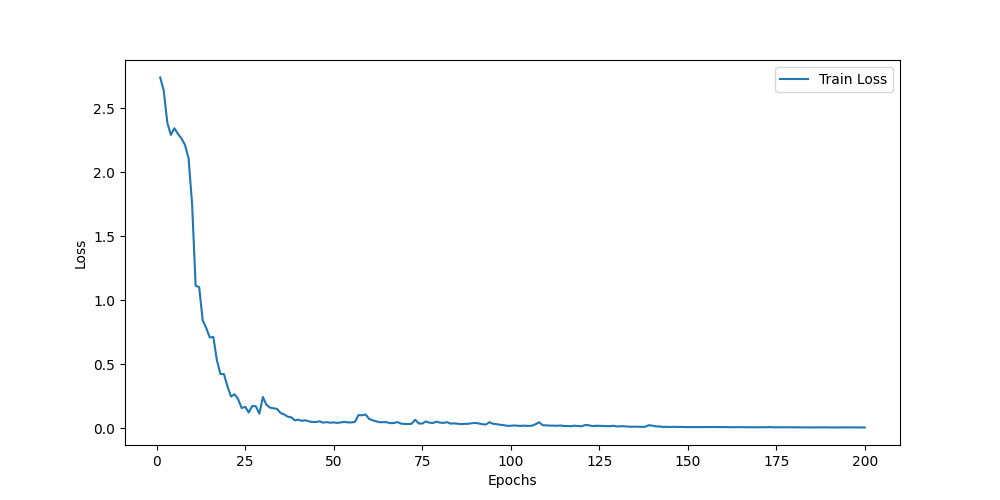
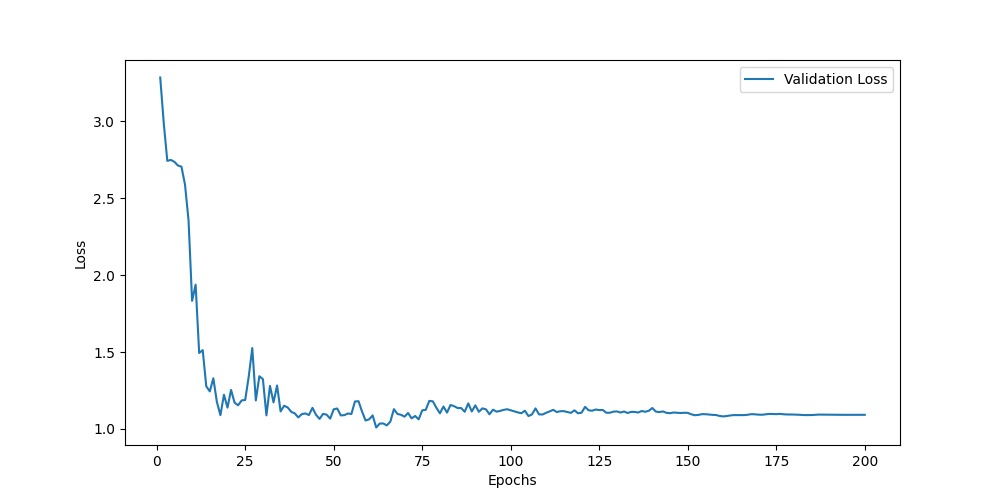

CMU-MOSEI数据集
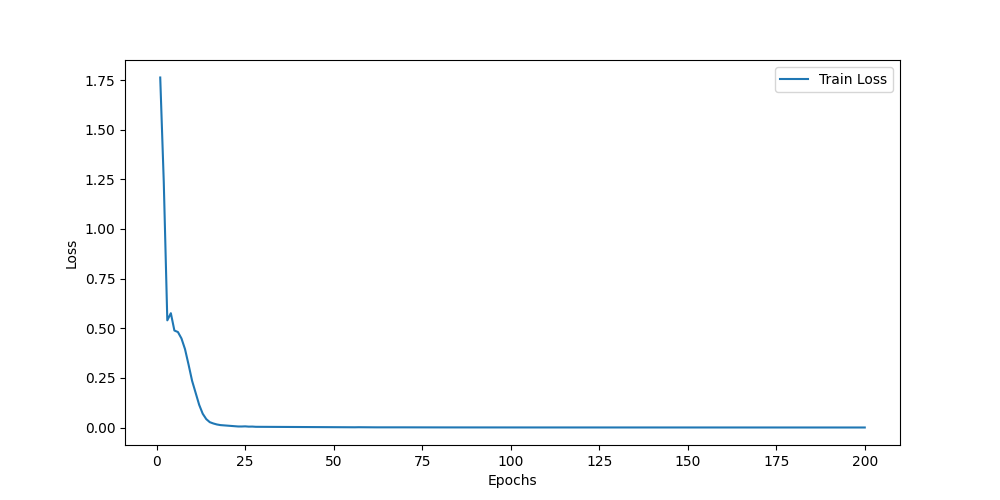
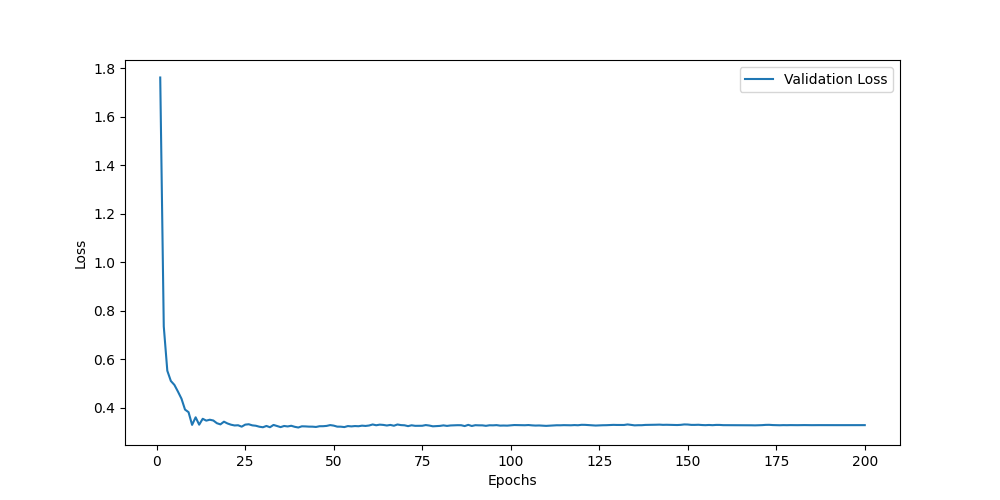
![]()
CH-SIMS数据集
最后:
小编会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!




















 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











