







1、数据集介绍
数据集源于论文Chinese NER using Lattice LSTM,从新浪财经上爬取,包括中国股市上市公司高级管理人员的简历。CoNLL 格式(首选 BIOES 标签方案),每个字符的标签为一行。句子用 null 行分割。链接及格式如下:
https://github.com/jiesutd/LatticeLSTM

2、Bi-LSTM-CRF模型
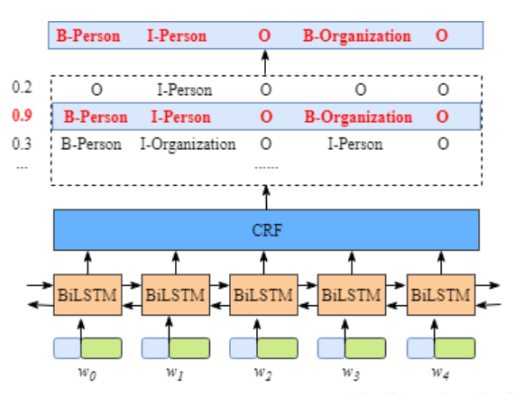
本文模型
LSTM(Long_short_term_memory),使用LSTM模型可以更好的捕捉到较长距离的依赖关系,通过训练可以学到记忆那些信息和遗忘那些信息, 能解决梯度爆炸和梯度弥散问题,可以处理更长的文本数据。
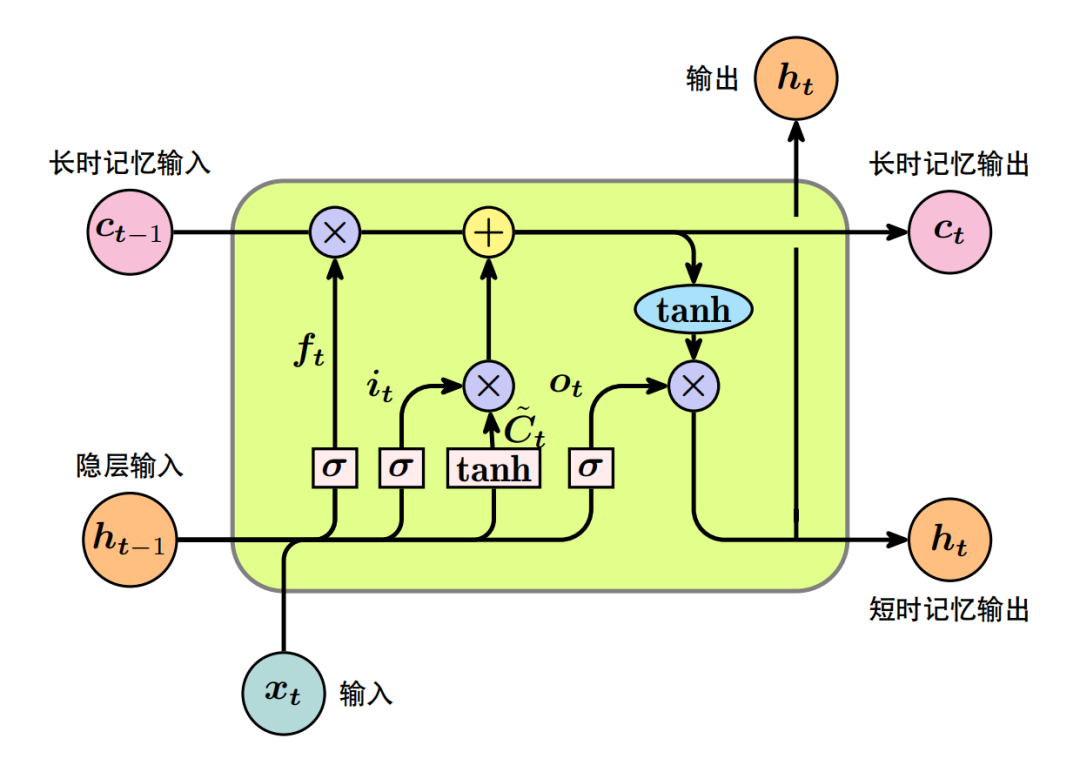
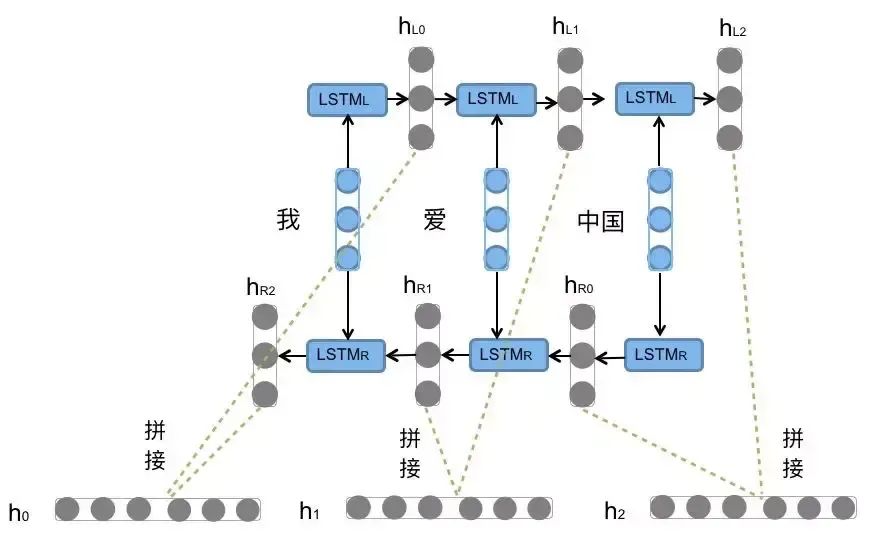
前向的LSTM与后向的LSTM结合成BiLSTM。比如,我们对“我爱中国”这句话进行编码。前向的LSTML,依次输入“我”,“爱”,“中国”得到三个向量{hL0,hL1,hL2}。后向的LSTMR依次输入“中国”,“爱”,“我”得到三个向量{hR0,hR1,hR2}。最后将前向和后向的隐向量进行拼接得到{[hL0,hR2],[hL1,hR1],[hL2,hR0]},即{h0, h1, h2}。
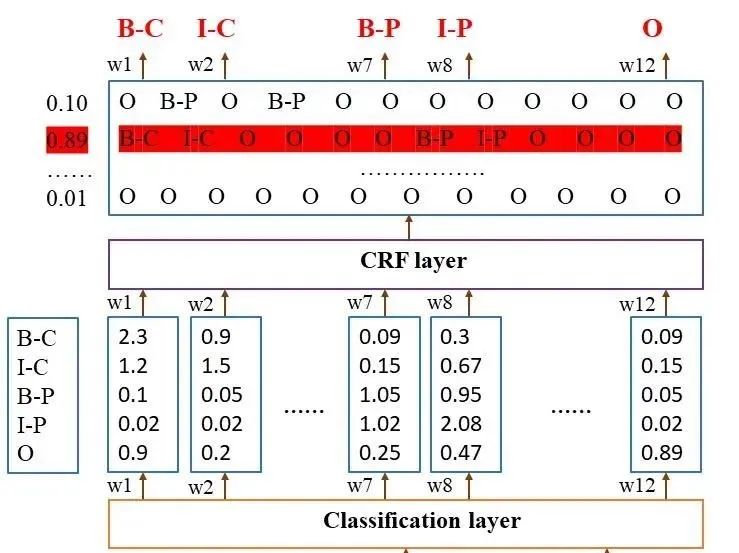
CRF层将BiLSTM的Emission_score作为输入,输出符合标注转移约束条件的、最大可能的预测标注序列。
3、代码实现
文末免费获取数据集和源码压缩包。
进入下面公众号聊天窗口回复“Bi-LSTM-CRF实体识别”即可获取完整源码。
最后:
小编会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!



















 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











