






 本文介绍了AI+权重衰退,特别是L2正则化在机器学习中的应用,通过惩罚大权重防止过拟合。同时提到了丢弃法作为深度学习的正则化手段,帮助提升模型泛化能力。
本文介绍了AI+权重衰退,特别是L2正则化在机器学习中的应用,通过惩罚大权重防止过拟合。同时提到了丢弃法作为深度学习的正则化手段,帮助提升模型泛化能力。
1权重衰退
AI+权重衰退是指在人工智能(AI)领域中的一种技术或方法,用于训练机器学习模型时对权重进行惩罚或调整,以避免过拟合现象的发生。
在机器学习中,过拟合是指模型在训练数据上表现很好,但在未见过的测试数据上表现不佳的情况。为了防止过拟合,一种常用的方法是引入权重衰退(Weight Decay),也称为L2正则化。权重衰退通过向模型的损失函数添加一个正则化项,惩罚模型中较大的权重值,使得模型倾向于学习到更简单的模式,从而提高泛化能力。
具体而言,权重衰退通过在损失函数中添加一个项来实现,该项是权重的平方和与一个调整参数的乘积,通常表示为λ∥w∥²,其中w表示模型的权重,λ是一个调整参数,用于控制正则化的强度。当λ较大时,正则化的影响会增强,从而导致模型更加倾向于选择较小的权重值,从而减少过拟合的风险。
在实际应用中,当训练数据规模较小、特征空间较大、或者存在噪声和异常值时,使用权重衰退可以帮助提高模型的泛化能力。它在各种机器学习任务中都有广泛的应用,包括回归、分类、聚类等。
总的来说,权重衰退是机器学习中的一个重要技术之一,尤其在处理高维数据和防止过拟合问题时,被广泛采用和应用。
总而言之,AI+权重衰退是一种用于减少过拟合风险的常见技术,通过在损失函数中引入正则化项来惩罚模型中较大的权重值,使模型更具有泛化能力


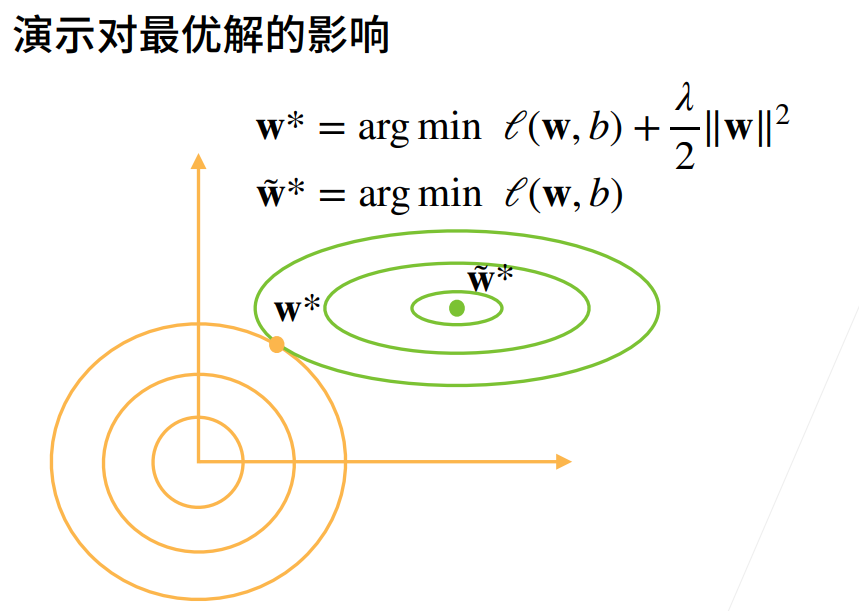


理解权重衰退需要对机器学习和深度学习的基本概念有一定的了解,并且对过拟合问题有所认识。具体来说,需要理解以下内容:
-
机器学习和深度学习基础:了解机器学习和深度学习的基本原理、常用算法和模型结构,例如线性回归、逻辑回归、神经网络等。
-
过拟合问题:理解过拟合是指模型在训练数据上表现很好,但在未见过的测试数据上表现不佳的情况。需要了解过拟合产生的原因,以及如何通过降低模型复杂度、增加训练数据量或者使用正则化等方法来解决过拟合问题。
-
正则化:理解正则化是一种用于减少模型复杂度和防止过拟合的技术,其中包括L1正则化和L2正则化。权重衰退就是一种L2正则化的方法,它通过向损失函数添加一个惩罚项来限制模型的权重大小。
-
损失函数:了解损失函数是用来衡量模型预测值与真实值之间差异的指标,而权重衰退是通过向损失函数添加正则化项来实现的。
-
超参数调优:权重衰退中的正则化参数(通常表示为λ)是一个需要调优的超参数,需要了解如何通过交叉验证或者其他方法来选择合适的正则化参数值。
理解到以上程度,就可以比较深入地理解权重衰退的原理和作用,并能够在实际应用中进行合理的使用和调优。
L1正则化和L2正则化是两种常用的正则化技术,它们在惩罚模型中较大的权重值方面有一些区别:
-
惩罚项的形式:
- L1正则化的惩罚项是权重的绝对值之和:[ \lambda \sum_{i=1}^{N} |w_i| ]
- L2正则化的惩罚项是权重的平方和:[ \lambda \sum_{i=1}^{N} w_i^2 ]
-
特征选择:
- L1正则化的一个显著特点是能够实现特征选择,因为它会将一些不重要的特征对应的权重压缩为0,从而简化了模型。
- L2正则化对权重进行平滑惩罚,不会将权重压缩为0,但会使权重趋向于较小的值。
-
鲁棒性:
- L1正则化对于噪声或异常值的鲁棒性相对较好,因为它可以将不重要特征的权重压缩为0。
- L2正则化的惩罚项是权重的平方和,对异常值相对敏感。
-
计算复杂度:
- 在某些情况下,L1正则化可以产生稀疏解,即模型中的大部分权重都是0。这种情况下,L1正则化可以通过稀疏矩阵运算来加速计算。
- L2正则化的惩罚项是权重的平方和,计算比较简单,但通常不会产生稀疏解。
总的来说,L1正则化和L2正则化各有其优点和适用场景。在实际应用中,可以根据数据的特点和模型的需求选择合适的正则化方法。
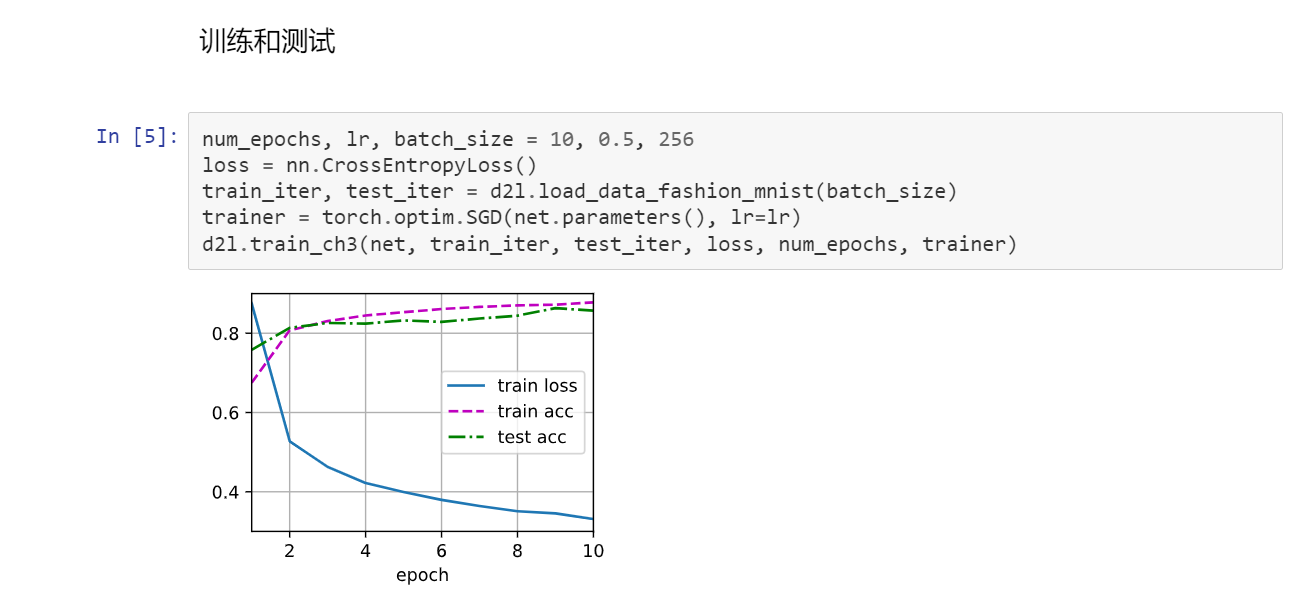
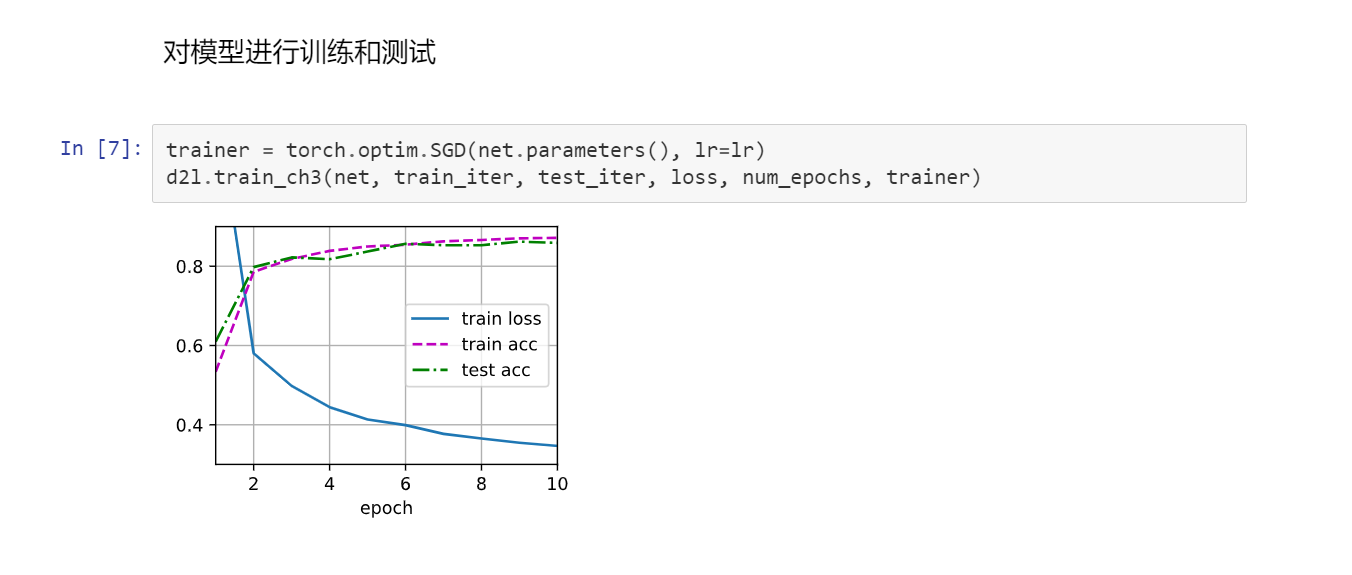
2代码实现
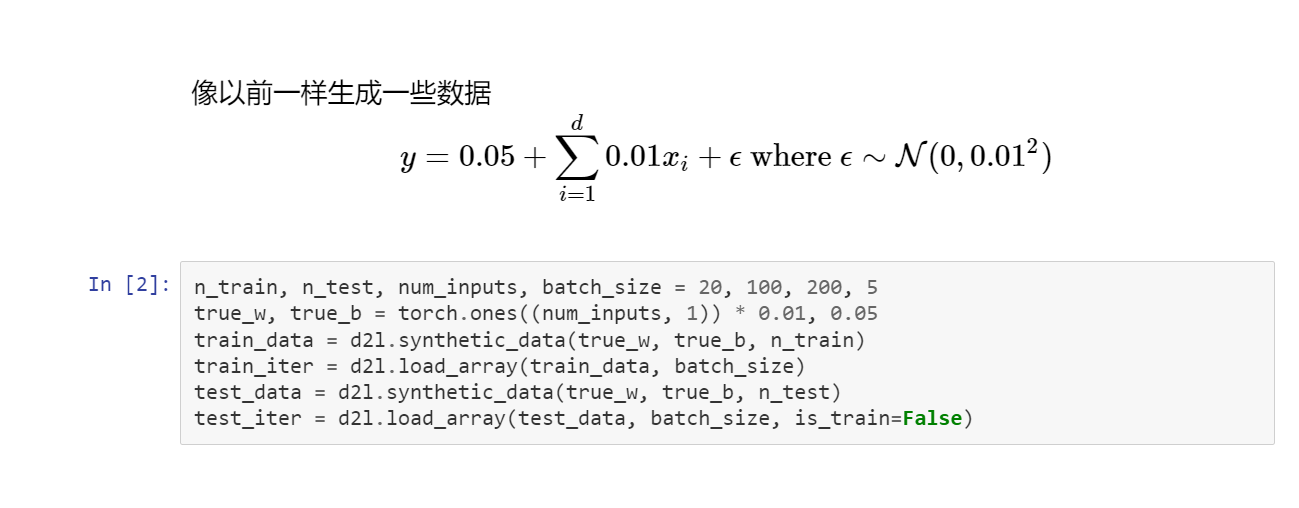
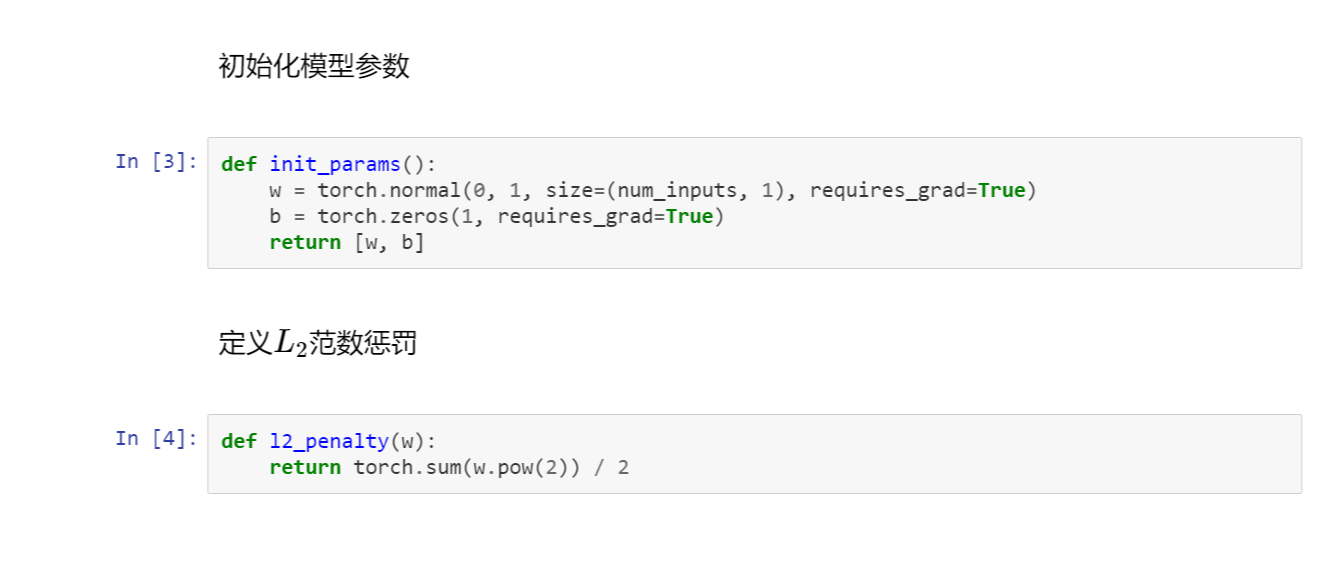
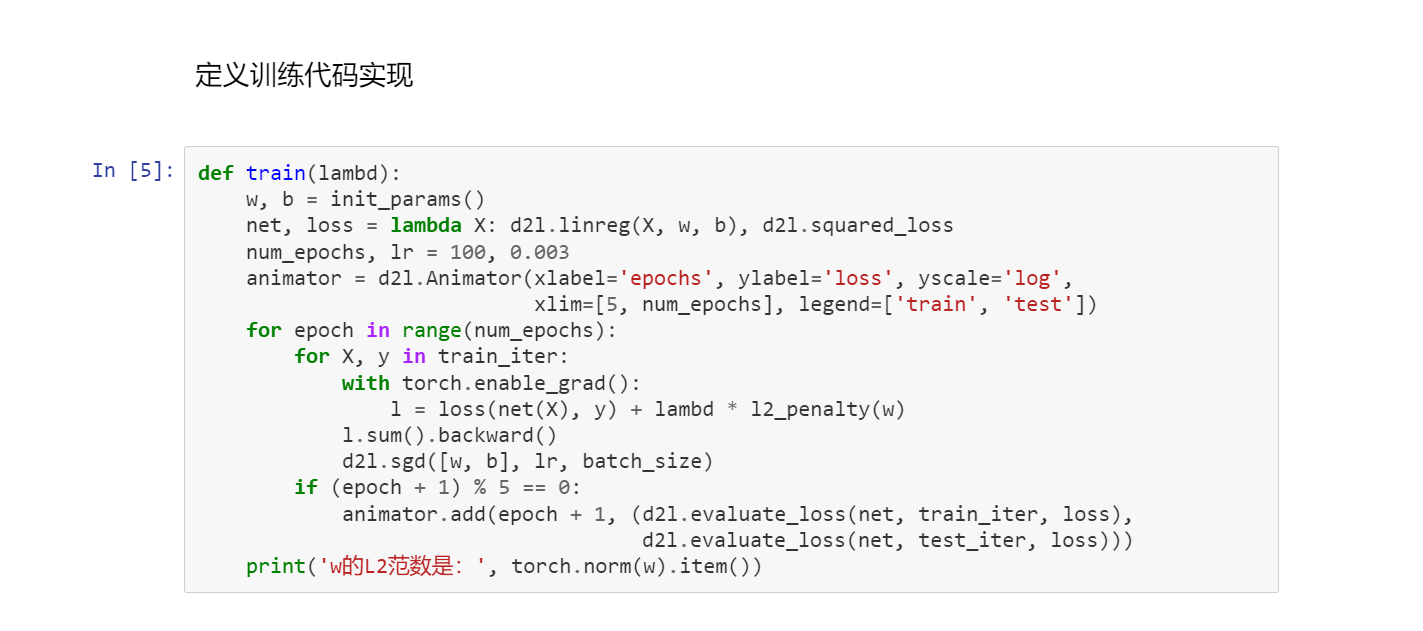

2丢弃法
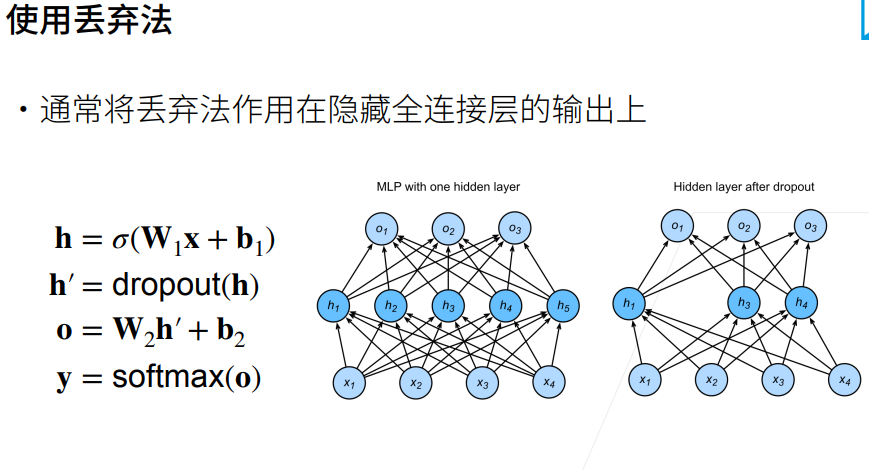
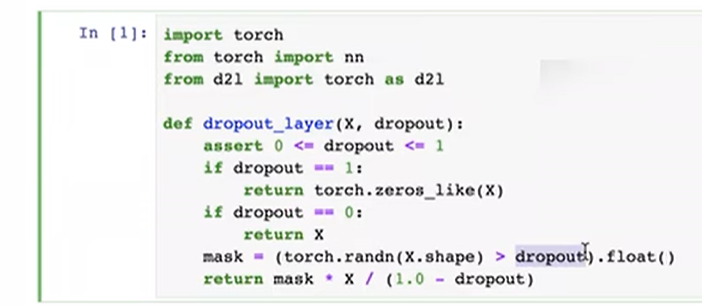
"丢弃法"是指在深度学习中的一种正则化技术,用于减少神经网络的过拟合。在训练神经网络时,丢弃法随机地在每次迭代中将一部分神经元的输出设置为零。这样可以强制网络在训练过程中学习到更加健壮的特征表示,从而提高模型的泛化能力。
丢弃法的核心思想是通过随机丢弃一些神经元来防止神经网络过度依赖于某些特定的神经元,从而降低了神经网络的复杂度,减少了过拟合的风险。通常情况下,丢弃法只在训练阶段使用,在测试阶段则不使用丢弃法,而是利用所有神经元进行推断。
丢弃法是深度学习中常用的正则化技术之一,可以有效提高模型的泛化能力,从而在实际应用中取得更好的性能。
























 1085
1085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









