










 该博客介绍使用Python爬取网易云音乐某个分类下的歌单信息,包括详细页地址、标题、播放量等,并保存到CSV文件。用到requests、time、BeautifulSoup模块,发现不同类别和页码的URL规律,以流行类为例展示拼接网址和查找歌单元素位置的方法。
该博客介绍使用Python爬取网易云音乐某个分类下的歌单信息,包括详细页地址、标题、播放量等,并保存到CSV文件。用到requests、time、BeautifulSoup模块,发现不同类别和页码的URL规律,以流行类为例展示拼接网址和查找歌单元素位置的方法。
获取网易云音乐的某个分类下的歌单的详细页地址、歌单标题、歌单播放量、歌单贡献者、歌单索引信息等。并保存到csv文件中去。
用到的模块:requests、time、BeautifulSoup
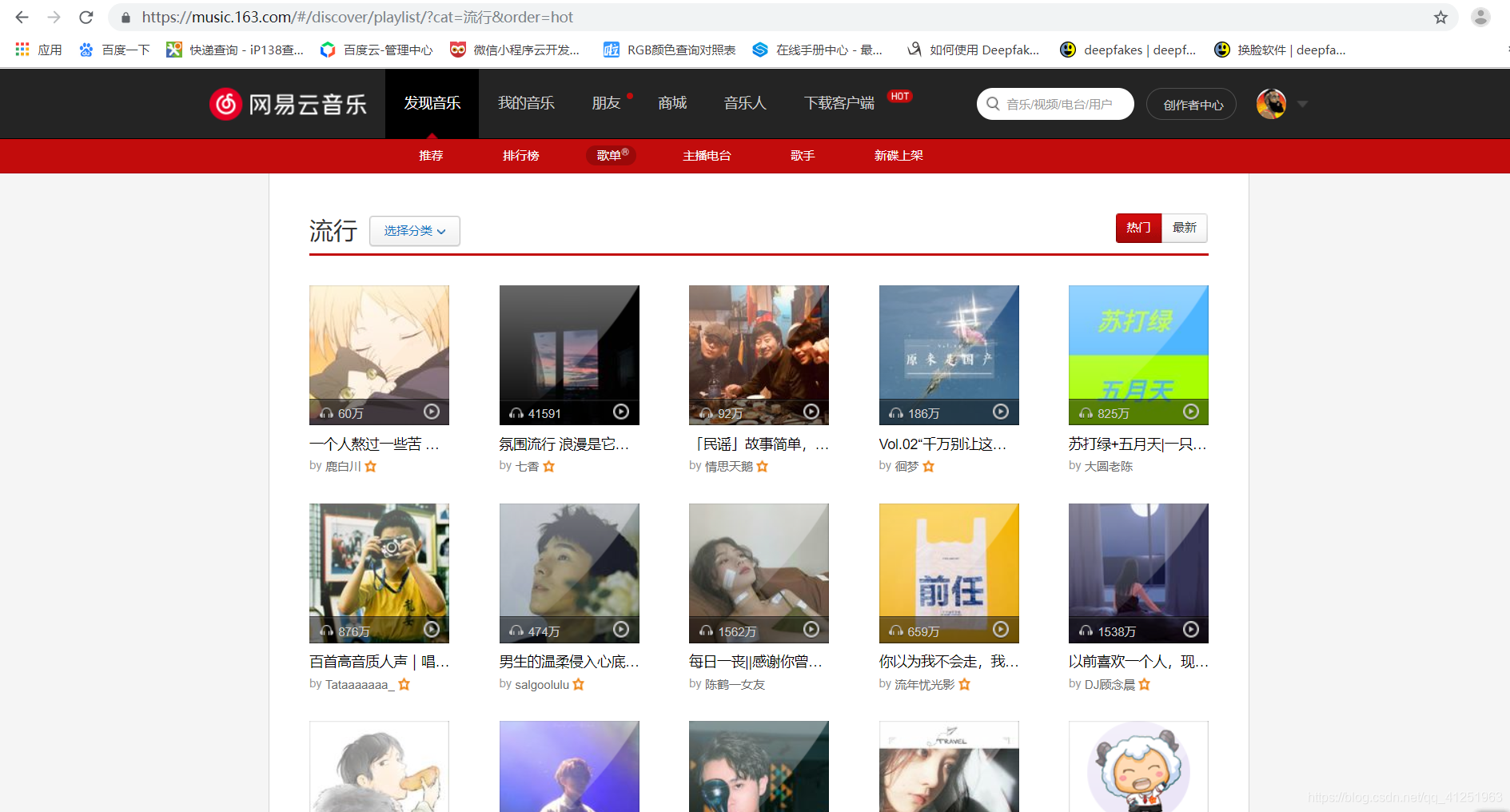
选择不同类别的歌曲,我们发现只是url中cat位置发生变化,因此想要爬取其他分类,只需更改url即可。
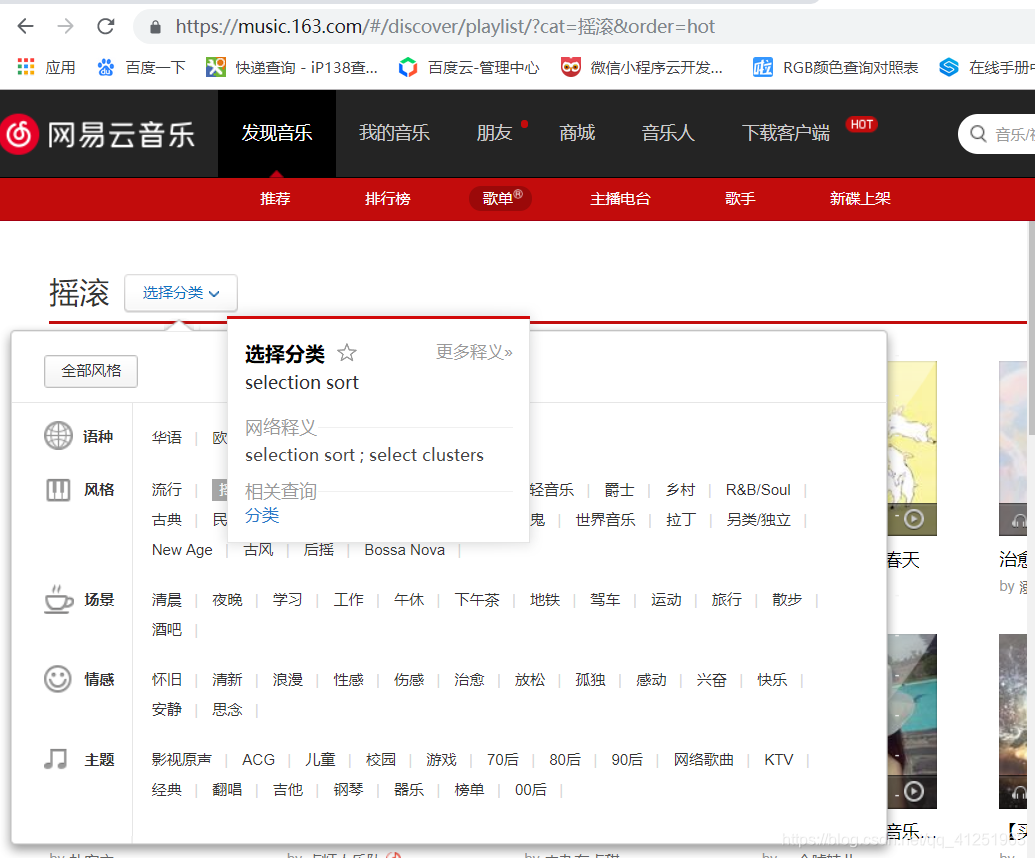
这里以爬取流行类为例:
观察各个页码对应的url。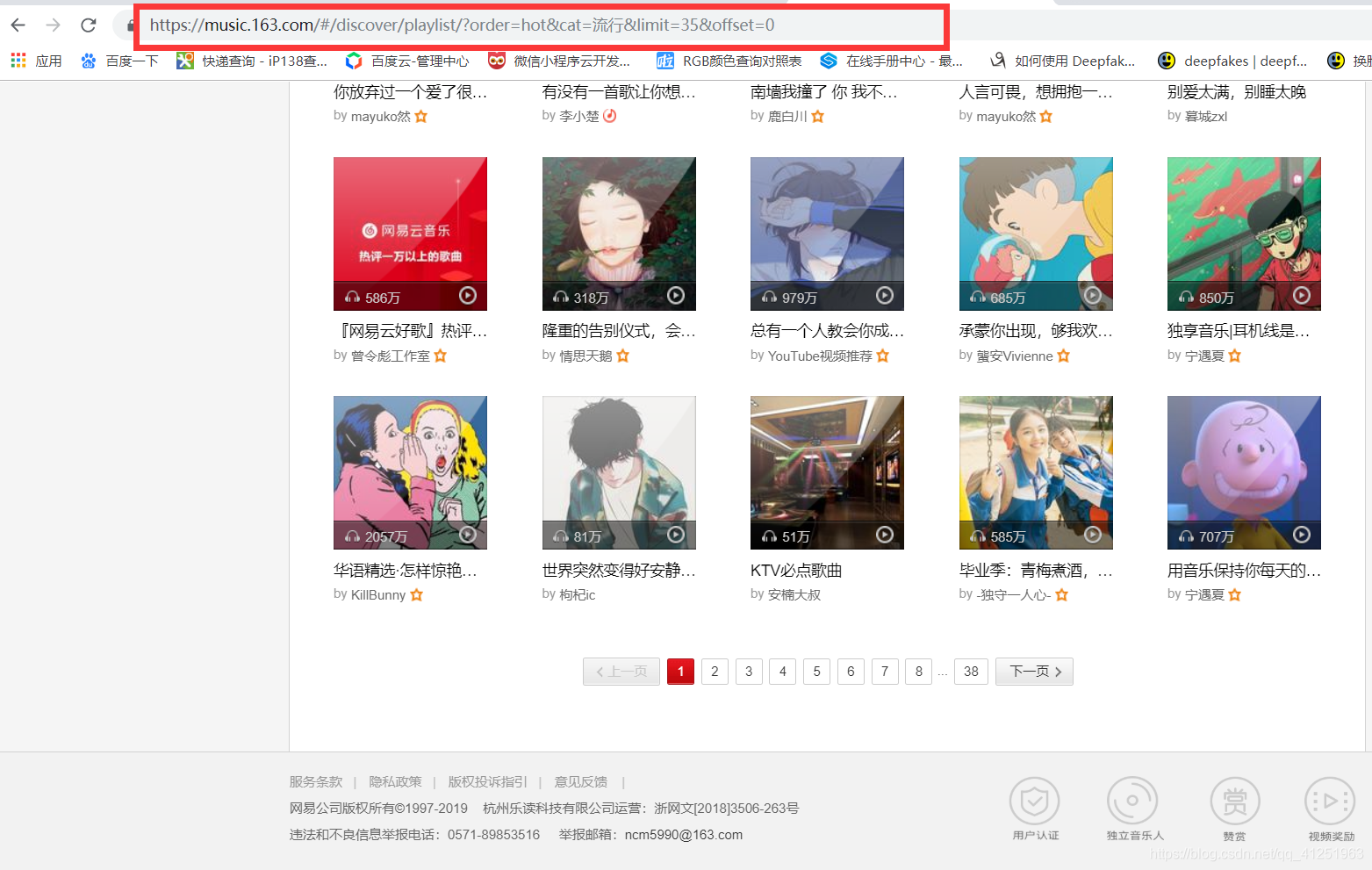
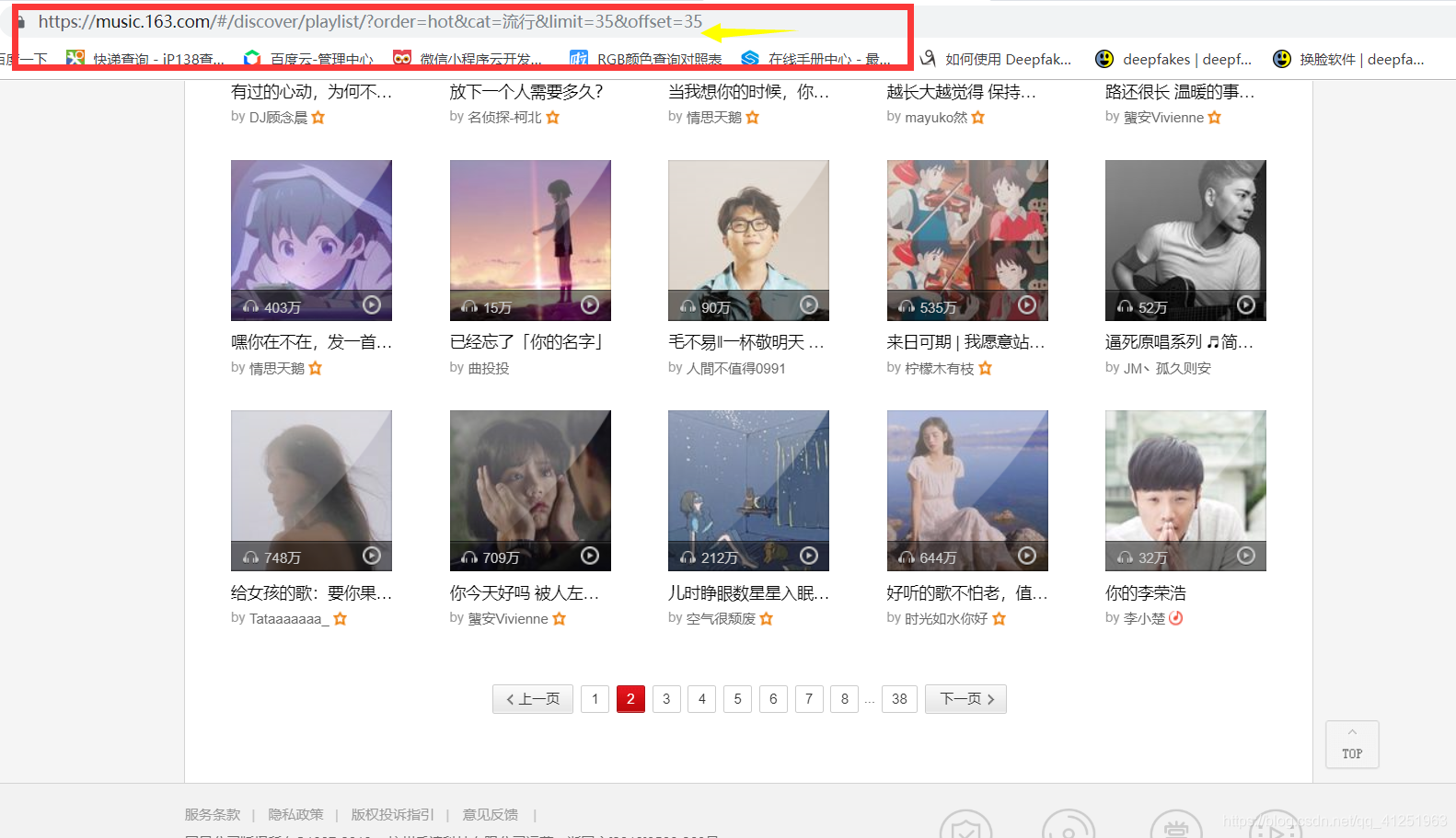 我们可以发现一些规律,每翻到下一页,url中offset增加35,我们在看最后一页:
我们可以发现一些规律,每翻到下一页,url中offset增加35,我们在看最后一页:
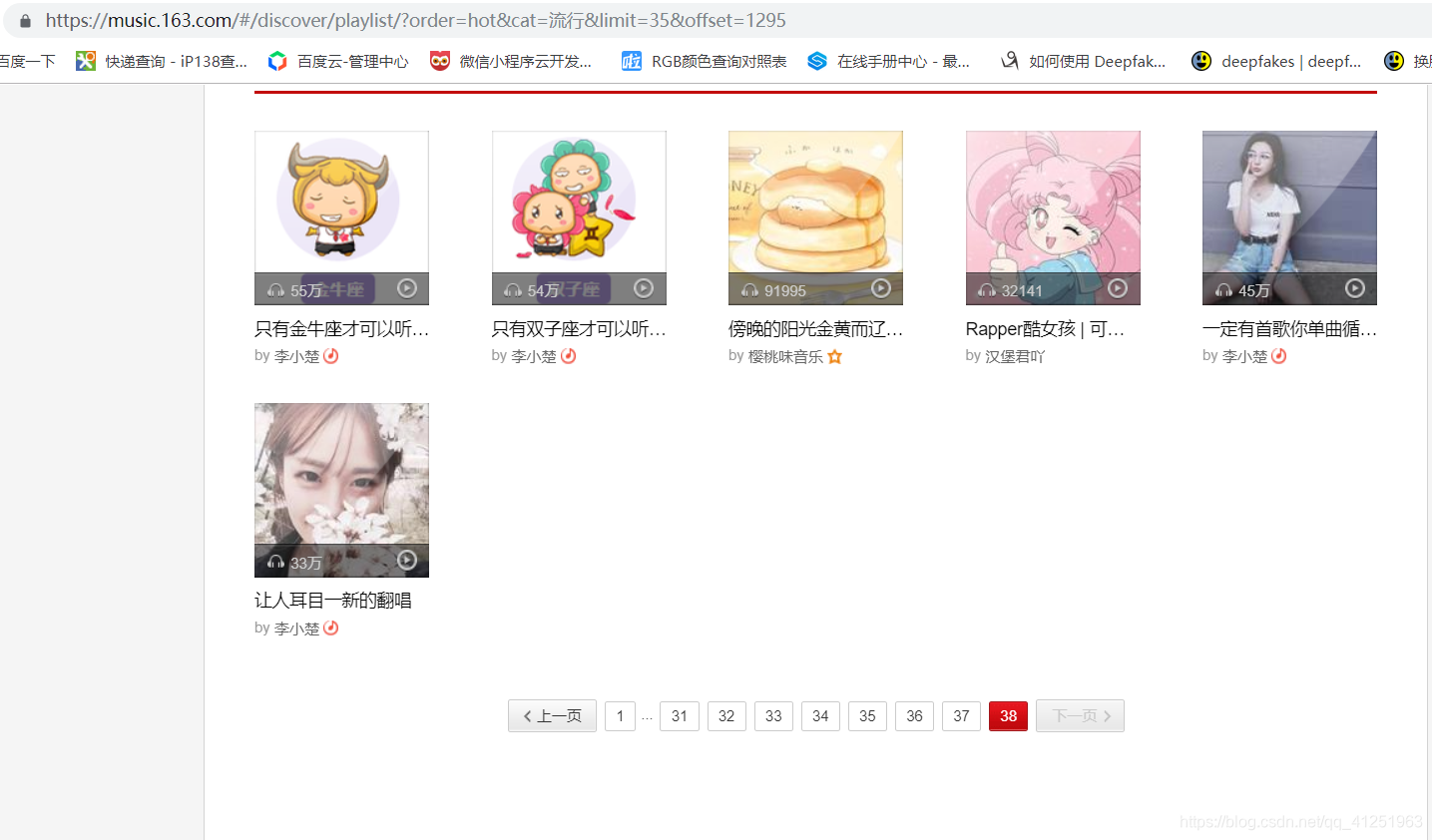
这样我们就可以成功的拼接每一页的网址了:
for i in range(0,1295,35):
url = 'https://music.163.com/discover/playlist/?cat=流行&order=hot&limit=35&offset=' + str(i)
查找歌单元素的位置:在id=“m-pl-container”的li标签下
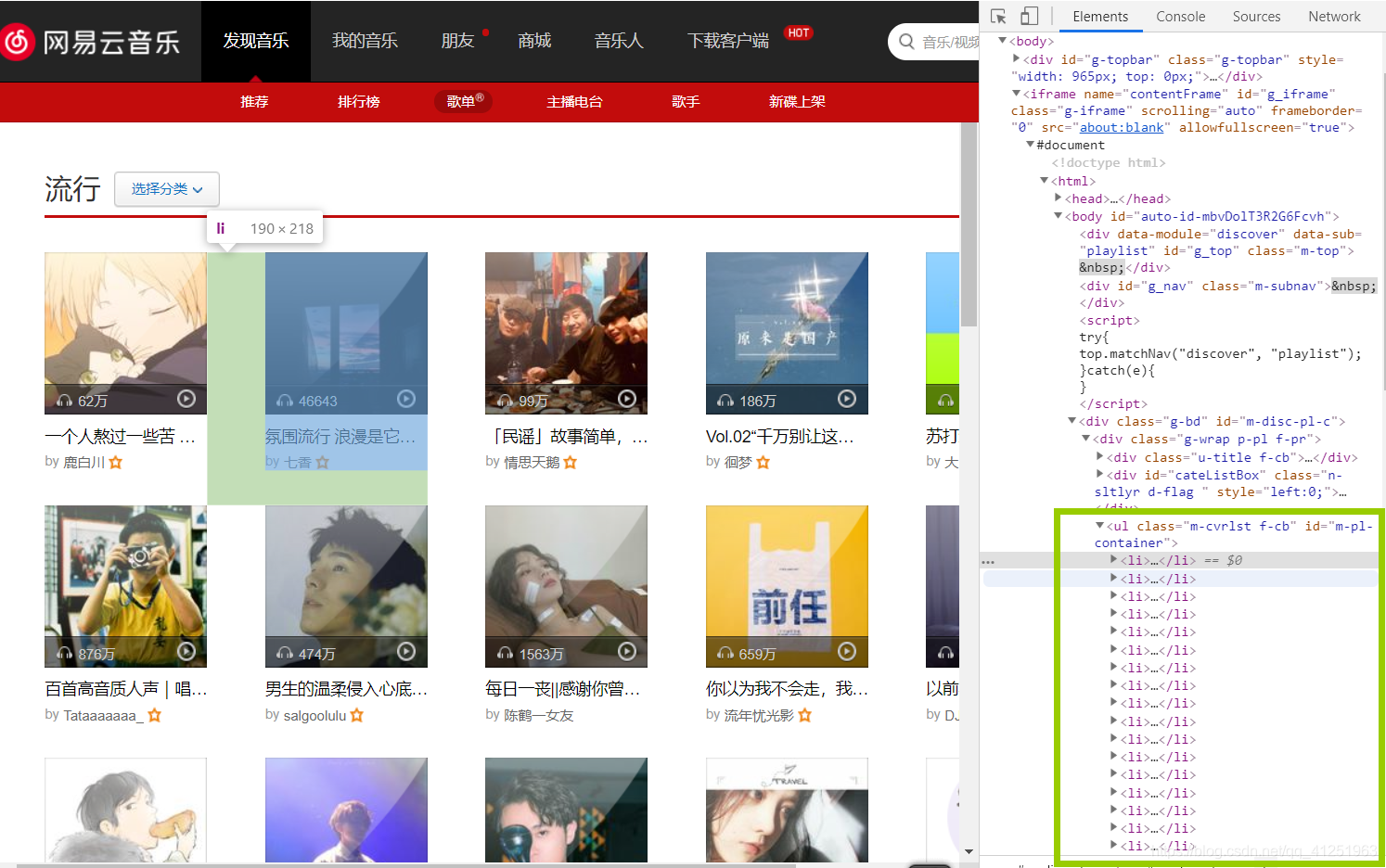
每个li标签下有我们想要的信息:
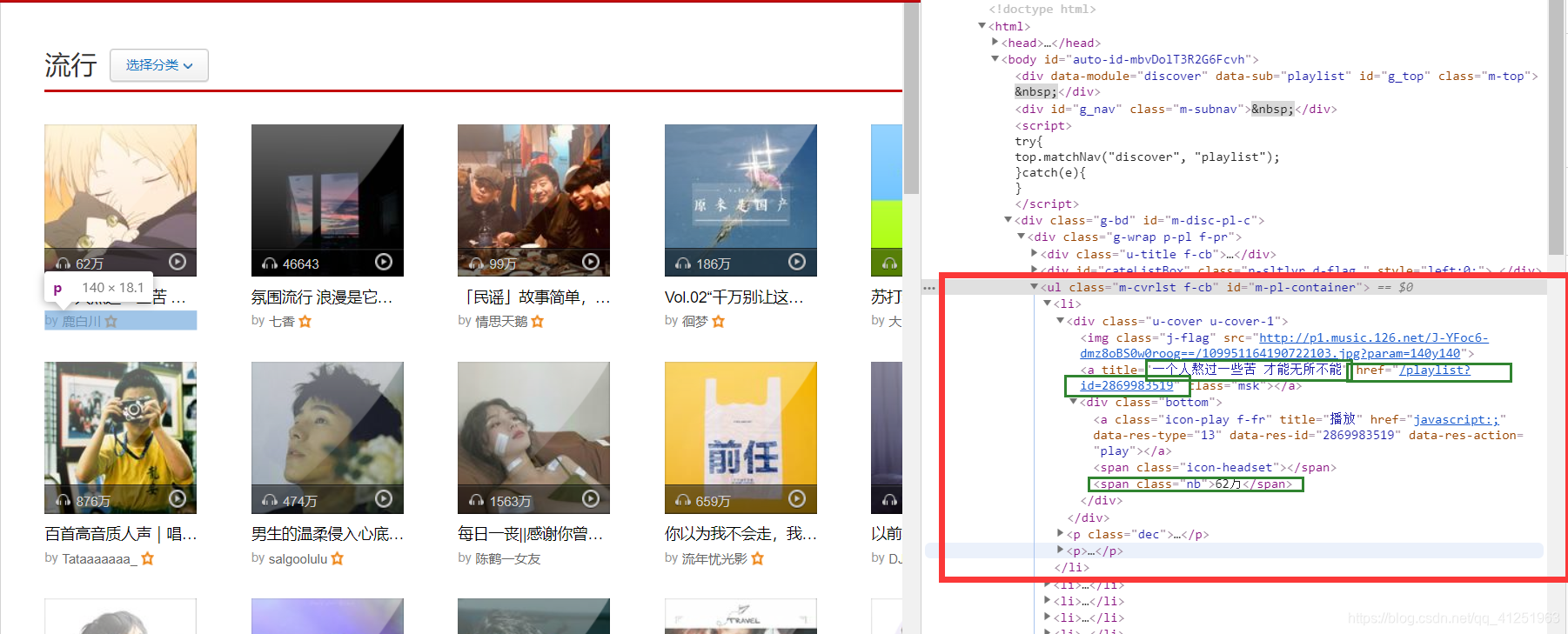
代码:
import requests
import time
from bs4 import BeautifulSoup
headers={
"user-agent":"Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 75.0.3770.100Safari / 537.36"
}
for i in range(0,1295,35):
url = 'https://music.163.com/discover/playlist/?cat=流行&order=hot&limit=35&offset=' + str(i)
response = requests.get(url=url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 获取包含歌单详情页网址的标签
ids = soup.select('.dec a')
# 获取包含歌单索引页信息的标签
lis = soup.select('#m-pl-container li')
print(len(lis))
for j in range(len(lis)):
# 获取歌单详情页地址
url = ids[j]['href']
# 获取歌单标题,替换英文分割符
title = ids[j]['title'].replace(',', ',')
# 获取歌单播放量
play = lis[j].select('.nb')[0].get_text()
# 获取歌单贡献者名字
user = lis[j].select('p')[1].select('a')[0].get_text()
# 输出歌单索引页信息
print(url, title, play, user)
# 将信息写入CSV文件中
with open('playlist.csv', 'a+', encoding='utf-8') as f:
f.write(url + ',' + title + ',' + play + ',' + user + '\n')
time.sleep(2)
运行结果:

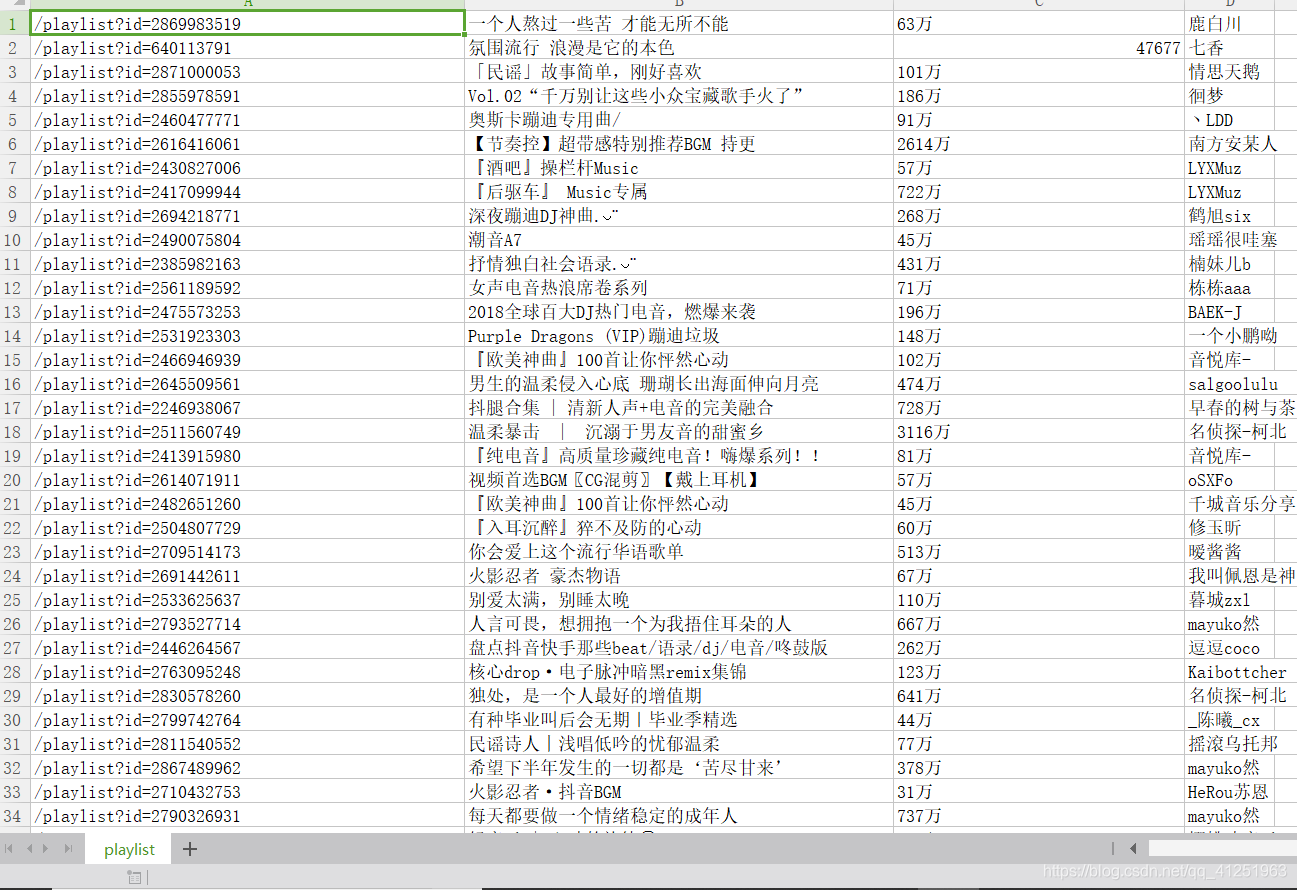


















 1553
1553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











