







 该博客介绍如何利用OpenCV的dnn模块进行超过400种行为的识别。通过加载预训练的ResNet-34_Kinetics模型,对输入视频进行处理,识别出每一帧的人类活动。代码示例展示了从视频中读取帧,创建帧队列,对帧进行预处理,并用模型进行预测。最后将识别结果保存到视频文件中。
该博客介绍如何利用OpenCV的dnn模块进行超过400种行为的识别。通过加载预训练的ResNet-34_Kinetics模型,对输入视频进行处理,识别出每一帧的人类活动。代码示例展示了从视频中读取帧,创建帧队列,对帧进行预处理,并用模型进行预测。最后将识别结果保存到视频文件中。
版本:

注意:如果是opencv-python 3.3会报错,cv2.dnn 找不到 readNet()
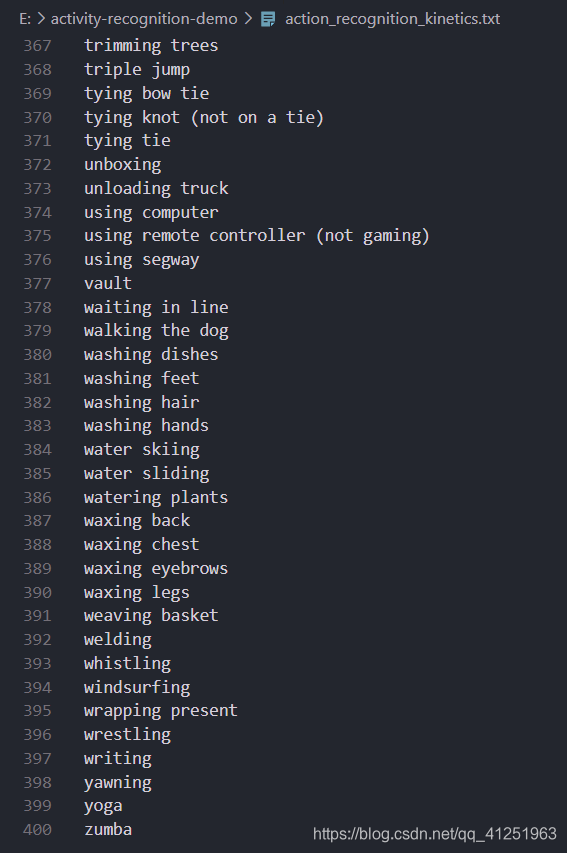
对于识别的行为超过400种:
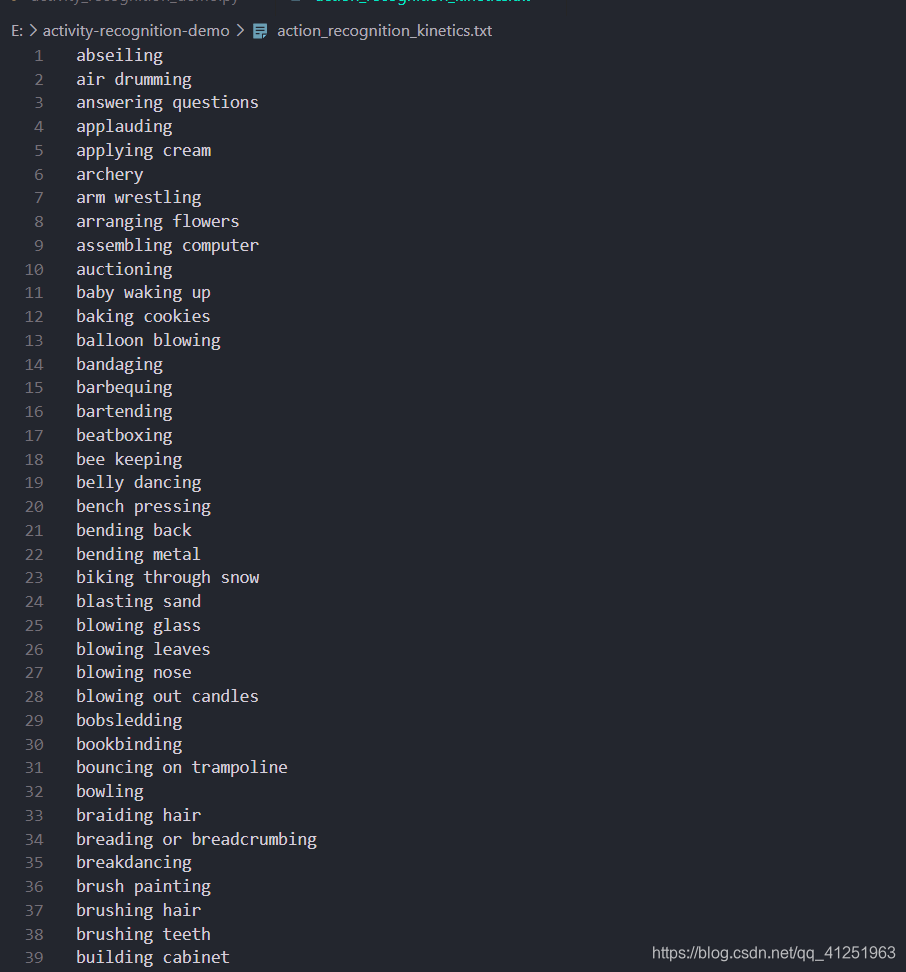
OpenCV官方示例的样本类别:
https://github.com/opencv/opencv/blob/master/samples/data/dnn/action_recongnition_kinetics.txt
示例代码:https://github.com/opencv/opencv/blob/master/samples/dnn/action_recognition.py
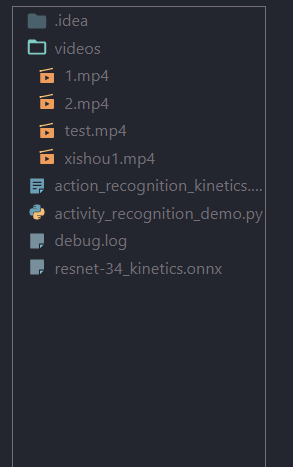
项目目录结构:
完整代码:
# 执行以下命令:
# python activity_recognition_demo.py --model resnet-34_kinetics.onnx --classes action_recognition_kinetics.txt --input videos/activities.mp4
from collections import deque
import numpy as np
import argparse
import imutils
import cv2
# 构造参数
ap = argparse.ArgumentParser()
ap.add_argument(
"-m",
"--model",
required=True,
help="path to trained human activity recognition model")
ap.add_argument(
"-c", "--classes", required=True, help="path to class labels file")
ap.add_argument(
"-i", "--input", type=str, default="", help="optional path to video file")
args = vars(ap.parse_args())
# 类别,样本持续时间(帧数),样本大小(空间尺寸)
CLASSES = open(args["classes"]).read().strip().split("\n")
SAMPLE_DURATION = 16
SAMPLE_SIZE = 112
print("处理中...")
# 创建帧队列
frames = deque(maxlen=SAMPLE_DURATION)
# 读取模型
net = cv2.dnn.readNet(args["model"])
# 待检测视频
vs = cv2.VideoCapture(args["input"] if args["input"] else 0)
writer = None
# 循环处理视频流
while True:
# 读取每帧
(grabbed, frame) = vs.read()
# 判断视频是否结束
if not grabbed:
print("无视频读取...")
break
# 调整大小,放入队列中
frame = imutils.resize(frame, width=640)
frames.append(frame)
# 判断是否填充到最大帧数
if len(frames) < SAMPLE_DURATION:
continue
# 队列填充满后继续处理
blob = cv2.dnn.blobFromImages(
frames,
1.0, (SAMPLE_SIZE, SAMPLE_SIZE), (114.7748, 107.7354, 99.4750),
swapRB=True,
crop=True)
blob = np.transpose(blob, (1, 0, 2, 3))
blob = np.expand_dims(blob, axis=0)
# 识别预测
net.setInput(blob)
outputs = net.forward()
label = CLASSES[np.argmax(outputs)]
# 绘制框
cv2.rectangle(frame, (0, 0), (300, 40), (255, 0, 0), -1)
cv2.putText(frame, label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2)
# cv2.imshow("Activity Recognition", frame)
# 检测是否保存
if writer is None:
# 初始化视频写入器
# fourcc = cv2.VideoWriter_fourcc(*"MJPG")
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
writer = cv2.VideoWriter(
"videos\\test.mp4",
fourcc, 30, (frame.shape[1], frame.shape[0]), True)
writer.write(frame)
# 按 q 键退出
# key = cv2.waitKey(1) & 0xFF
# if key == ord("q"):
# break
print("结束...")
writer.release()
vs.release()
可能与我找的视频有关,有些测试效果不是很好。
测试结果:

模型下载地址:
链接:https://pan.baidu.com/s/17mQvUr6jsUyd2k0RrbrXaA
提取码:irho



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











