







HiveSQL 的原理:我们都知道 HiveSQL 会被翻译成 MapReduce 任务执行,那么一条 SQL 是如何翻译成MapReduce 的?
详细! 需要多看几遍才能看懂
https://www.aboutyun.com/thread-20461-1-1.html
Hive 和普通关系型数据库有什么区别?
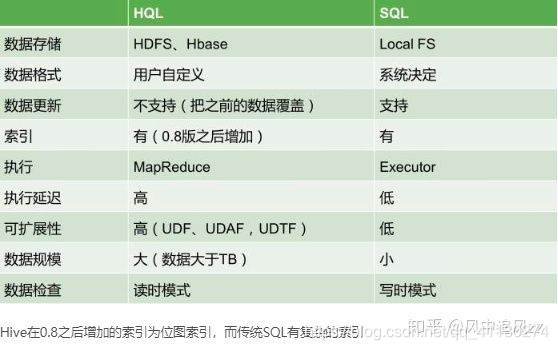
1.查询语言不同:hive是hql语言,mysql是sql语句;
2.数据存储位置不同:hive是把数据存储在hdfs上,而mysql数据是存储在自己的系统中;
3.数据格式:hive数据格式可以用户自定义,mysql有自己的系统定义格式;
4.数据更新:hive不支持数据更新,只可以读,不可以写,而sql支持数据更新;
5.索引:hive没有索引,因此查询数据的时候是通过mapreduce很暴力的把数据都查询一遍,也造成了hive查询数据速度很慢的原因,而mysql有索引;
6.延迟性:hive延迟性高,原因就是上边一点所说的,而mysql延迟性低;
7.数据规模:hive存储的数据量超级大,而mysql只是存储一些少量的业务数据;
8.底层执行原理:hive底层是用的mapreduce,而mysql是excutor执行器;
————————————————
版权声明:本文为优快云博主「老子天下最美」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/Sunshine_2211468152/article/details/83031356
HQL 和 SQL 有哪些常见的区别
Hive 支持哪些数据格式
Hive支持原始数据类型和复杂类型,原始类型包括数值型,Boolean,字符串,时间戳。复杂类型包括array,map,struct,union。
原始数据类型:
| 类型名称 | 大小 | 备注 |
|---|---|---|
| TINYINT | 1字节整数 | 45Y |
| SMALLINT | 2字节整数 | 12S |
| INT | 4字节整数 | 10 |
| BIGINT | 8字节整数 | 244L |
| FLOAT | 4字节单精度浮点数 | 1.0 |
| DOUBLE | 8字节双精度浮点数 | 1.0 |
| DECIMAL | 任意精度带符号小数 | DECIMAL(4, 2)范围:-99.99到99.99 |
| BOOLEAN | true/false | TRUE |
| STRING | 字符串,长度不定 | “a”, ‘b’ |
| VARCHAR | 字符串,长度不定,有上限 | 0.12.0版本引入 |
| CHAR | 字符串,固定长度 | “a”, ‘b’ |
| BINARY | 存储变长的二进制数据 | |
| TIMESTAMP | 时间戳,纳秒精度 | 122327493795 |
| DATE | 日期 | ‘2016-07-03’ |
复杂类型:
| 类型名称 | 大小 | 示例 |
|---|---|---|
| ARRAY | 存储同类型数据 | ARRAY< data_type> |
| MAP | key-value,key必须为原始类型,value可以是任意类型 | MAP< primitive_type, data_type> |
| STRUCT | 类型可以不同 | STRUCT< col_name : data_type [COMMENT col_comment], …> |
| UNION | 在有限取值范围内的一个值 | UNIONTYPE< data_type, data_type, …> |
Hive 在底层是如何存储 NULL 的
HIVE表中默认将NULL存为\N,可查看表的源文件(hadoop fs -cat或者hadoop fs -text),文件中存储大量\N, 这样造成浪费大量空间。而且用java、python直接进入路径操作源数据时,解析也要注意。另外,hive表的源文件中,默认列分隔符为\001(SOH),行分隔符为\n(目前只支持\n,别的不能用,所以定义时不需要显示声明)。元素间分隔符\002,map中key和value的分隔符为\003。
举例,如源文件中一条记录为:
10000042SOH77SOH435SOH16SOH22SOH1156120000SOH\NSOH\NSOH\NSOH\NSOH\NSOH\NSOH\NSOHyoukuSOH85133.0SOH111
可以看出存储NULL的\N 浪费了大量空间。**但hive的NULL有时候是必须的:1)hive中insert语句必须列数匹配,不支持不写入,没有值的列必须使用null占位。2)hive表的数据文件中按分隔符区分各个列。**空列会保存NULL(\n)来保留列位置。但外部表加载某些数据时如果列不够,
如表13列,文件数据只有2列,则在表查询时表中的末尾剩余列无数据对应,自动显示为NULL。所以,NULL转化为空字符串,可以节省磁盘空间,实现方法有几种
1)建表时直接指定(两种方式)
a、用语句ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe’
with serdeproperties(‘serialization.null.format’ = ‘’)
实现,注意两者必须一起使用,如
CREATETABLE hive_tb (idint,name STRING)
PARTITIONED BY (day string,type tinyint COMMENT’0 as bid, 1 as win, 2 as ck’,hour tinyint)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe’
WITH SERDEPROPERTIES (‘field.delim’=’/t’,‘escape.delim’=’//’,serialization.null.format’=’’ )
STORED AS TEXTFILE;
b、或者通过ROW FORMAT DELIMITED NULL DEFINED AS ‘‘如
CREATETABLE hive_tb (idint,name STRING)
PARTITIONED BY (day string,type tinyint COMMENT’0 as bid, 1 as win, 2 as ck’,hour tinyint)
ROW FORMAT DELIMITED
NULL DEFINEDAS’’
STORED AS TEXTFILE;
2)修改已存在的表
alter table hive_tb set serdeproperties(‘serialization.null.format’ = ‘’);
HiveSQL 支持的几种排序各代表什么意思(Sort By/Order By/Cluster By/Distrbute By)
这个写的差不多了
https://blog.youkuaiyun.com/lzm1340458776/article/details/43306115?depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1&utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1
原博主应该是加了℃ 所以排序有点问题
去掉就正常了
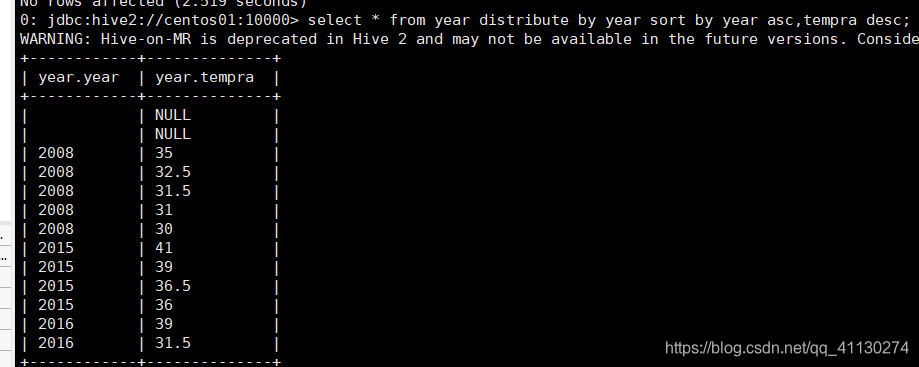
cluster by =
cluster by的功能就是distribute by和sort by相结合
Hive 的动态分区
往hive分区表中插入数据时,如果需要创建的分区很多,比如以表中某个字段进行分区存储,则需要复制粘贴修改很多sql去执行,效率低。因为hive是批处理系统,所以hive提供了一个动态分区功能,其可以基于查询参数的位置去推断分区的名称,从而建立分区。
1.创建一个单一字段分区表
1 hive>
2 create table dpartition(id int ,name string )
3 partitioned by(ct string );
2.往表里装载数据,并且动态建立分区,以city建立动态分区
hive>
hive.exec.dynamici.partition=true; #开启动态分区,默认是false
set hive.exec.dynamic.partition.mode=nonstrict; #开启允许所有分区都是动态的,否则必须要有静态分区才能使用。
insert overwrite table dpartition
partition(ct)
select id ,name,city from mytest_tmp2_p;
要点:因为dpartition表中只有两个字段,所以当我们查询了三个字段时(多了city字段),所以系统默认以最后一个字段city为分区名,因为分区表的
分区字段默认也是该表中的字段,且依次排在表中字段的最后面。所以分区需要分区的字段只能放在后面,不能把顺序弄错。如果我们查询了四个字段的话,则会报
错,因为该表加上分区字段也才三个。要注意系统是根据查询字段的位置推断分区名的,而不是字段名称。
hive>--查看可知,hive已经完成了以city字段为分区字段,实现了动态分区。
hive (fdm_sor)> show partitions dpartition;
partition
ct=beijing
ct=beijing1
注意:使用,insert…select 往表中导入数据时,查询的字段个数必须和目标的字段个数相同,不能多,也不能少,否则会报错。但是如果字段的类型不一致的话,则会使用null值填充,不会报错。而使用load data形式往hive表中装载数据时,则不会检查。如果字段多了则会丢弃,少了则会null值填充。同样如果字段类型不一致,也是使用null值填充。
3.多个分区字段时,实现半自动分区(部分字段静态分区,注意静态分区字段要在动态前面)
1 1.创建一个只有一个字段,两个分区字段的分区表
2 hive (fdm_sor)> create table ds_parttion(id int )
3 > partitioned by (state string ,ct string );
4 2.往该分区表半动态分区插入数据
5 hive>
6 set hive.exec.dynamici.partition=true;
7 set hive.exec.dynamic.partition.mode=nonstrict;
8 insert overwrite table ds_parttion
9 partition(state='china',ct) #state分区为静态,ct为动态分区,以查询的city字段为分区名
10 select id ,city from mytest_tmp2_p;
11
12 3.查询结果显示:
13 hive (fdm_sor)> select * from ds_parttion where state='china'
14 > ;
15 ds_parttion.id ds_parttion.state ds_parttion.ct
16 4 china beijing
17 3 china beijing
18 2 china beijing
19 1 china beijing
20 4 china beijing1
21 3 china beijing1
22 2 china beijing1
23 1 china beijing1
24
25 hive (fdm_sor)> select * from ds_parttion where state='china' and ct='beijing';
26 ds_parttion.id ds_parttion.state ds_parttion.ct
27 4 china beijing
28 3 china beijing
29 2 china beijing
30 1 china beijing
31
32 hive (fdm_sor)> select * from ds_parttion where state='china' and ct='beijing1';
33 ds_parttion.id ds_parttion.state ds_parttion.ct
34 4 china beijing1
35 3 china beijing1
36 2 china beijing1
37 1 china beijing1
38 Time taken: 0.072 seconds, Fetched: 4 row(s)
4.多个分区字段时,全部实现动态分区插入数据
1 set hive.exec.dynamici.partition=true;
2 set hive.exec.dynamic.partition.mode=nonstrict;
3 insert overwrite table ds_parttion
4 partition(state,ct)
5 select id ,country,city from mytest_tmp2_p;
6 注意:字段的个数和顺序不能弄错。
5.动态分区表的属性
使用动态分区表必须配置的参数 :
set hive.exec.dynamic.partition =true(默认false),表示开启动态分区功能
set hive.exec.dynamic.partition.mode = nonstrict(默认strict),表示允许所有分区都是动态的,否则必须有静态分区字段
动态分区相关的调优参数:
set hive.exec.max.dynamic.partitions.pernode=100 (默认100,一般可以设置大一点,比如1000)
表示每个maper或reducer可以允许创建的最大动态分区个数,默认是100,超出则会报错。
set hive.exec.max.dynamic.partitions =1000(默认值)
表示一个动态分区语句可以创建的最大动态分区个数,超出报错
set hive.exec.max.created.files =10000(默认) 全局可以创建的最大文件个数,超出报错。
Hive 中的内部表和外部表的区别
内部表和外部表在创建的时候稍微有一点区别:
1.默认情况下是内部表(managed table)
2.外部表(external table)创建的时候需要加上external关键字,并且需要指定位置
3.删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
4.内部表数据由Hive自身管理,外部表数据由HDFS管理
5.内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己指定;
6.对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
没明白“desc formated t1 ”是什么意思啊?查看该表当前的格式和详细信息
“desc t1”又是什么意思啊?查看该表的字段情况
————————————————
版权声明:本文为优快云博主「道法—自然」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/wyqwilliam/article/details/81061038
Hive 表进行关联查询如何解决长尾和数据倾斜问题
HiveSQL 的优化(系统参数调整、SQL 语句优化)
明日解决

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









