







arxiv: https://arxiv.org/abs/2310.06117
背景
LLM在生成COT的推理中可能会出现过程错误。为了减少错误,本文引入了Step-Back Prompting来增强模型的推理能力。
本文方法
(1)思想动机
- 抽象的目的不是为了模糊,而是为了创造一个新的语义层次,在这个层次上可以绝对精确。
- 许多任务可能会包含大量细节信息,受到大量信息的干扰,LLM可能很难检索到相关事实来处理该任务。因此,以“退一步”的方式先去抽象出问题中的核心部分,减少其他细节等不相关的信息干扰。将推理建立在这样的抽象之上,有助于避免中间步骤中的推理错误。然后,再去针对核心问题进行进行回答,再进一步解答原始问题。
(2)方法步骤
- 抽象:提示LLM针对问题,提出一个更高层次概念或准则的一般性回退问题,并且检索与更高层次概念或准者相关的事实信息。
- 推理:根据更高层次概念或准则的相关事实,对原始的问题进行推理。这一步也被称为“基于抽象的推理”。
实验设置
(1)数据集
- STEM:MMLU中的高中物理和化学部分。
- Knowledge QA:TimeQA(包含负责的查询,需要具有对时间敏感的知识)、SituatedQA(开放检索QA数据集,需要模型回答给定事件或地理背景的问题)。
- Multi-Hop Reasoning:MuSiQue(通过可组合的单跳问题创建的一个困难多跳推理数据集)、StrategyQA(需要一些策略的开放领域数据集)
(2)基座模型
PaLM-2L、GPT-4
(3)评估方式
few-shot的PaLM2-L,评判正确答案和预测答案是否等效。“Yes”或“No”是返回值。
(4)基线方法
- PaLM-2L、PaLM-2L 1-shot
- PaLM-2L+COT、PaLM-2L+COT 1-shot
- COT:Let’s think step by step.
- PaLM-2L+TDB
- TDB:Take a deep breath and work on this problem step-by-step.
- PaLM-2L+RAG
- GPT-4
实验情况
(1)STEM
- Prompt设置
- 文中首先教LLM以概念和第一原理的形式进行抽象。例如,牛顿第一定律、多普勒效应」、吉布斯自由能等。这里牵扯到的一个隐含问题是“解决这个问题的所涉及的物理或化学院里和概念是什么?”
- 提供示例,教模型从自己的知识中背诵解决任务的相关原则。

-
few-shot

-
实验结果
- 对比基线结果
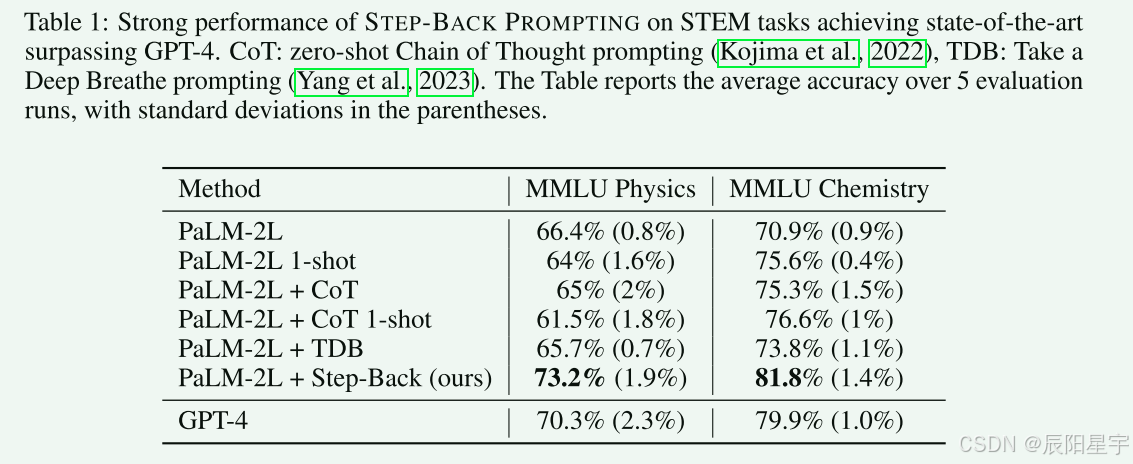
可以发现Step-Back提升效果明显
- 消融实验结果
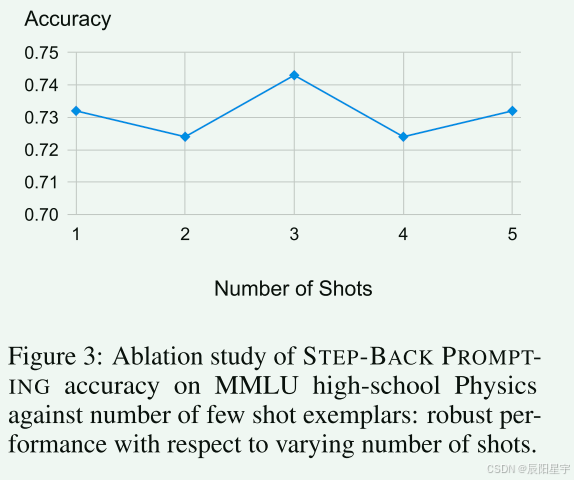
示例的变化,对于性能提升影响不大。因此,1-shot就够了。
- 错误分析
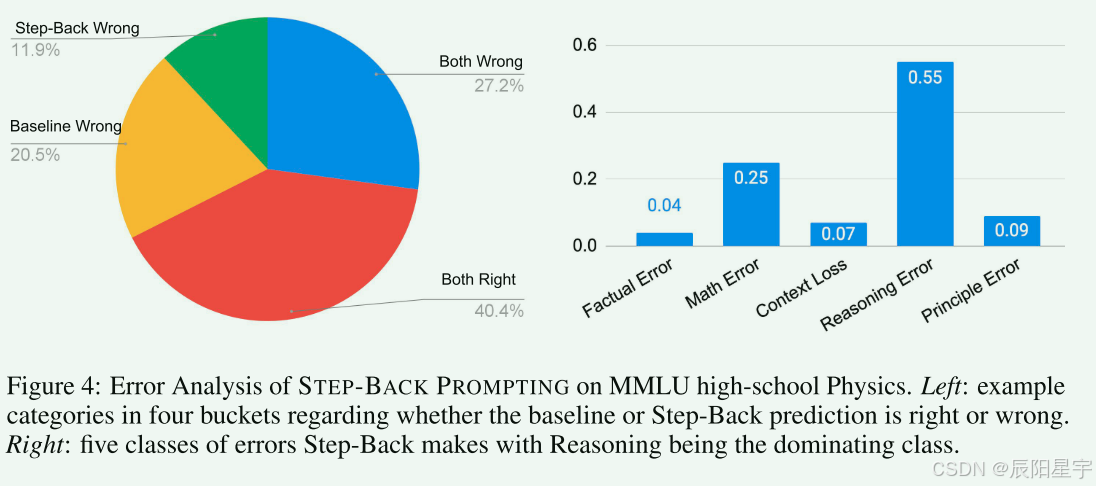
分为五类错误:
* 准则错误:抽象步骤时出错,生成的准则错误或不完整。
* 事实错误:当模型背诵自己的事实知识时,至少有一个事实错误。
* 数学错误:在推到最终答案的中间步骤中,至少有一个数学错误。
* 上下文丢失:当模型响应时丢失了问题的上下文,并和要解决的原始问题发生偏离。
* 推理错误:生成最终答案过程中,中间推力步骤出现错误。
(2)Knowledge QA
- prompt设置
- 此部分将RAG和Step-Back Prompting结合使用,Step-Back Prompting用于检索相关事实,作为附加上下文。


- 实验结果
-
对比基线
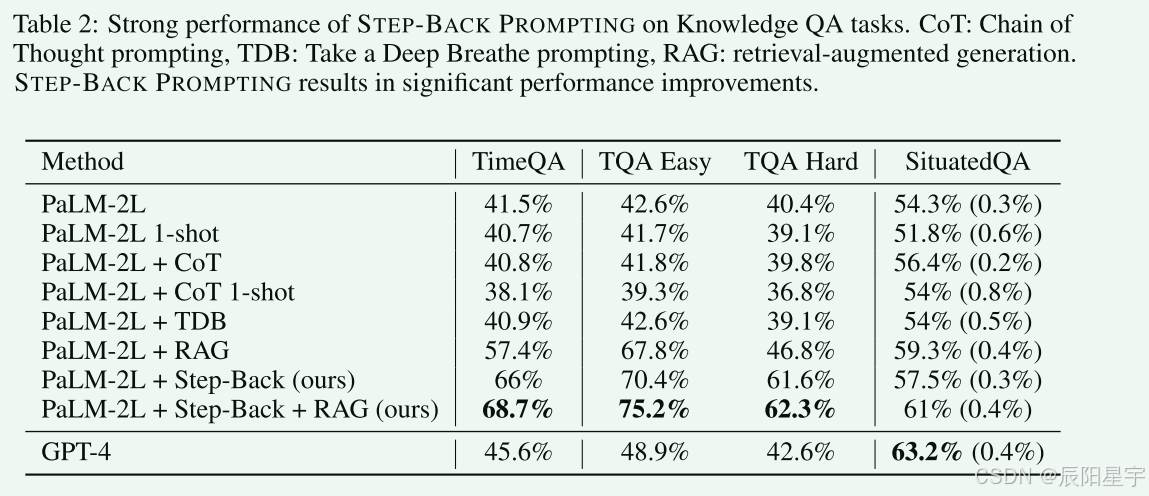
-
消融实验
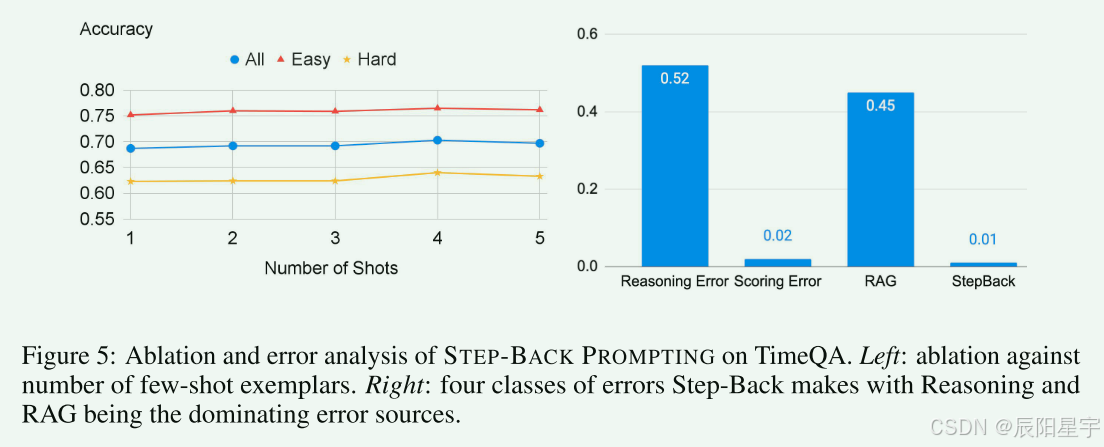
-
同上,增加示例提升不大。
- 错误分析
- 四类错误类型:
- 回退错误:回退的问题对解决问题没有帮助。
- RAG错误:尽管会对问题和目标相关,但是RAG不能检索到相关信息。
- 打分错误:裁判模型打分出错。
- 推理错误:检索到相关信息,但是生成最终答案时,推理步骤出错。
- 对于开放域回答的知识类型场景,可以看出回退问题大部分都是正确的,主要问题出现在推理过程和RAG检索方面。
(3)Multi-Hop Reasoning
- 四类错误类型:
- Prompt 设置
- 设置同上
- 实验结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











