







该系列主要是听李宏毅老师的《深度强化学习》过程中记下的一些听课心得,除了李宏毅老师的强化学习课程之外,为保证内容的完整性,我还参考了一些其他的课程,包括周博磊老师的《强化学习纲要》、李科浇老师的《百度强化学习》以及多个强化学习的经典资料作为补充。
使用说明
- 笔记【4】到笔记【11】 为李宏毅《深度强化学习》的部分;
- 笔记 【1】和笔记 【2】 根据《强化学习纲要》整理而来;
- 笔记 【3】 和笔记 【12】根据《百度强化学习》 整理而来。
一、强化学习基本知识
(1)基本概念
强化学习关注的是智能体在未知环境中如何获得最大的奖励。
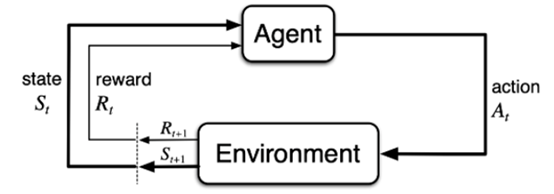
图1.强化学习过程示意图
如图1所示,强化学习中重要的两个主体为Agent和Environment。其中Agent即智能体(也就是你所写的算法),比如在游戏中Agent指玩家;Environment即外部环境,比如在游戏中指游戏环境。强化学习的过程就是不断通过Agent和Environment这两者的交互来获得最大奖励值,具体过程为:智能体Agent根据当前环境Environment的状态state,从而输出一个动作action,该动作执行之后就会对环境产生影响,从而使得环境的状态发生变化,并且获得对应的奖励reward,根据变化后的状态,智能体又做出下一个动作,进而作用于环境……在这个过程中Agent的目的就是尽可能多的从环境中获得奖励。
(2)强化学习vs监督学习
监督学习就是把人为标注好的数据输入网络,网络通过这些数据进行学习。其中这些数据之间满足独立同分布,也就是说他们共同满足某种分布并且互不关联。在学习过程中,如果网络输出了错误的预测结果,那么这些带标注的数据马上就能告诉它:你预测错误了,正确的答案应该是…,并且将这一次的预测偏差算入损失函数,之后一步步减小这个损失函数,从而训练出网络。
举个例子,要利用监督学习训练一个识别飞机和汽车的网络。首先对各种飞机和汽车图片进行人工标注,之后将该标注完成的数据集输入网络,在训练过程中,当网络将一张飞机图片预测成汽车时,图片上的标注会告诉它:错误,正确答案应该是飞机。此时网络就会根据此反馈调整自己的参数,从而一步步使得结果更加准确。
根据上述例子可知,(1)监督学习中的反馈是非常及时的,可以在网络产生结果之后马上反馈,(2)反馈结果不但会给出预测正误的判断,并且会直接给出正确答案,(3)训练数据之间独立同分布,也即没有关联。
强化学习的训练过程则比较像一个玩游戏的过程,从第一步开始采取一个动作,改变环境状态之后再采取下一个动作,所以训练数据之间具有时间上的强关联性,是一个序列,而不是独立同分布的;并且执行了一个动作之后,不会有标签来告诉你该动作执行的对不对、正确的应该是怎么做;此外,强化学习的奖励往往有延迟,比如对于游戏而言,只有等到游戏结束,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









