







今天在优化模型时,发现激活函数对计算量影响还是蛮大的,特地分析下LU系列常用的激活函数之间的区别
在深度学习领域,激活函数是神经网络中不可或缺的组成部分。它们为模型引入非线性特性,使得神经网络能够学习和模拟复杂的函数映射。
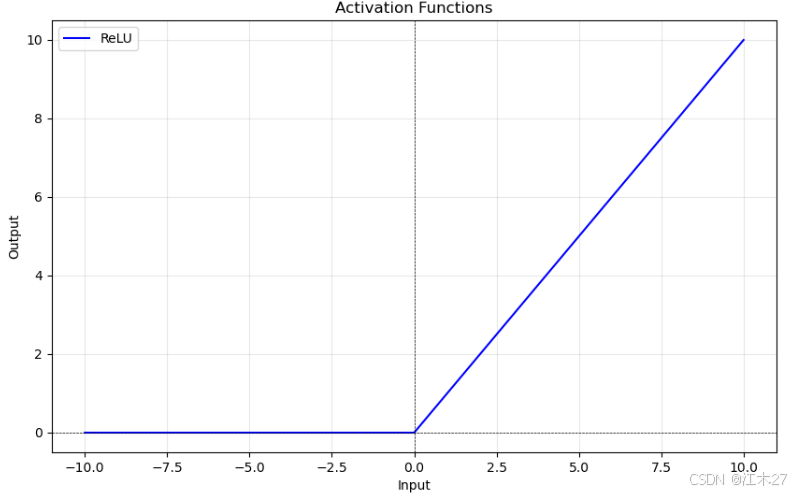
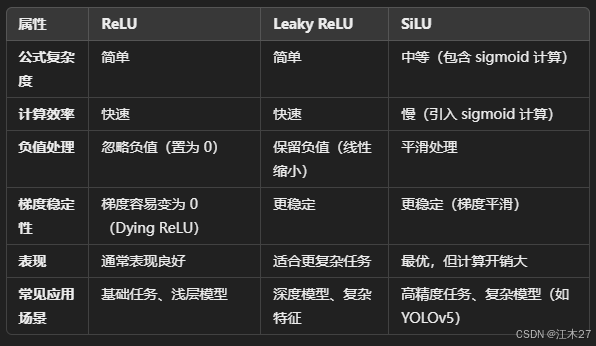
ReLU
- ReLU(Rectified Linear Unit)因其计算简单、ReLU 在很多情况下表现较好,但它可能会导致“神经元死亡”(即 ReLU 激活后的输出恒为0),特别是在初始化不当或学习率过大的情况下
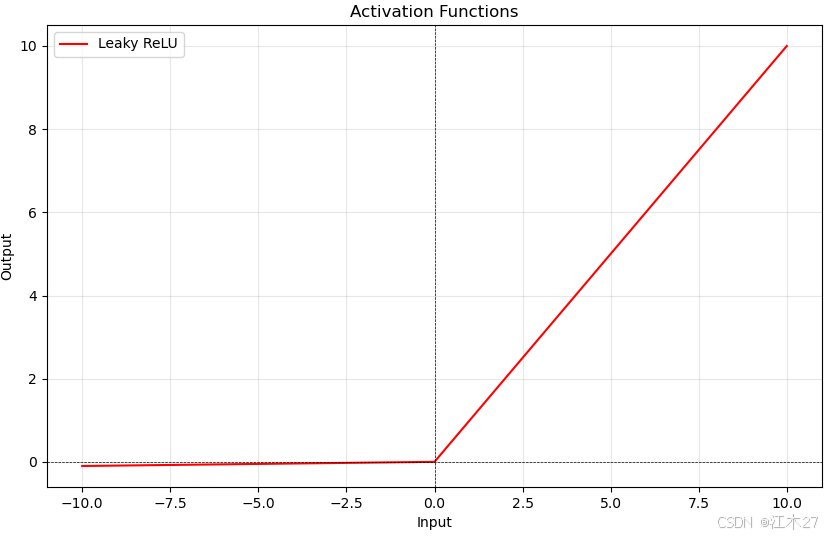
Leaky ReLU
- Leaky ReLU可以缓解 ReLU 的一些问题,通过允许负值部分避免神经元完全“死掉”。通常取值为0.01
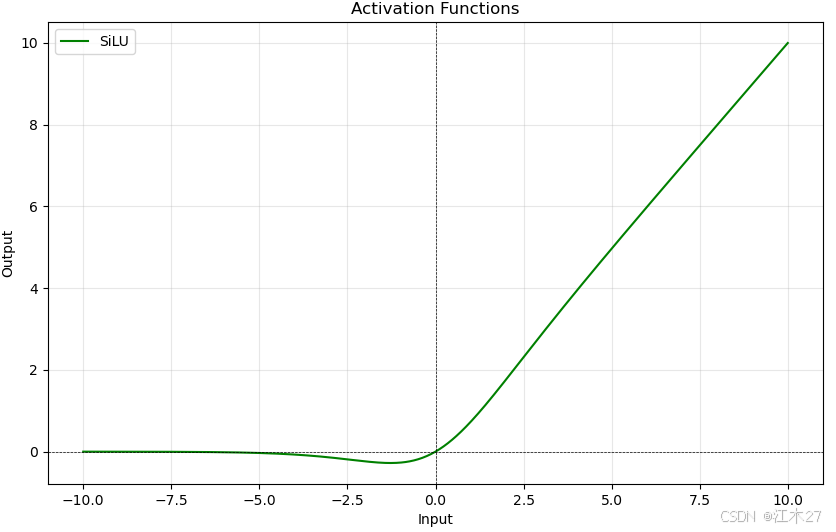
SiLU
- SiLU(Sigmoid Linear Unit)近年来提出的激活函数,表现出在一些任务中相较于ReLU更好的性能,尤其在深层网络中更为有效
- 适用于网络较深、任务较复杂时使用
相同层不同激活函数对比(MACs、Memory)
- Relu
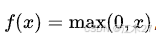

- SiLU


- Leaky ReLU
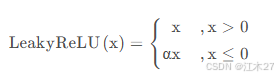
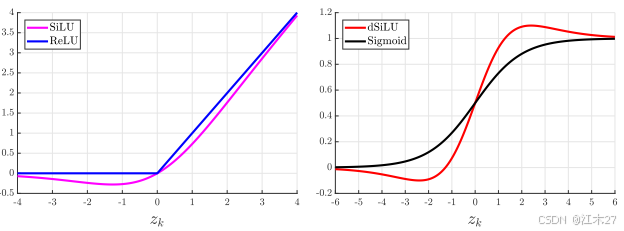
- 论文中SiLU和ReLU曲线对比和其导数
总结
可以看到激活函数在计算量上影响还是很大的,因为每一次卷积都会跟随一次激活函数,多次使用对整体的计算量、内存都会提升。具体如何选择我认为还是要通过实验来衡量速度与精度。
- ReLU缺点:当权重更新导致节点输出始终小于0时,该节点的梯度为零,不会再更新,导致网络部分神经元失效,所有负输入直接被置为 0,可能丢失一些重要信息
- Leaky ReLU缺点:引入了超参数 𝛼,需要手动调整其值(默认一般是 0.01),可能导致不稳定性。计算复杂度略高:相比 ReLU,多了一些系数乘法操作,但仍然较高效
- SiLU缺点:引入了 sigmoid 函数,导致计算复杂度较高。由于公式的复杂性和非单调性,不容易直观理解其输出对学习的影响。

















 6284
6284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









