







论文背景
机器学习研究近年的发展非常迅速,监督学习是其中很重要的一种方法,监督学习的目标是从训练样本中学习一个从样本到标签的有效映射,使其能够预测未知样本的标签,不足之处是需要大量的标记数据,针对这一不足,提出无监督学习,无监督学习仅根据测试样本在特征空间的分布情况标记样本,准确性差。半监督学习结合了两者的长处,有少量未标记的样本,学习机以从训练样本中获得的知识为基础,结合测试样本的分布情况进一步修正已有知识,并判断测试样本的类别。由于现实中很难得到大量标记样本,人为标记样本代价昂贵,半监督学习很好的弥补这一缺陷,它只需一小部分带标记的数据和一大部分未标识的数据。随着半监督学习的流行,数据安全成为了一个问题,毒害半监督学习中的未标识数据,很有可能改变模型的分类,本文基于这一背景研究。
论文工作
本文研究的是针对未标记数据的投毒研究,通过毒害未标记的数据集,导致学习的模型对目标例子进行错误分类;针对这种攻击提出防御方法。
①引入第一次半监督中毒攻击,只需要控制0.1%的未标记数据
②发现模型的准确性和中毒易感性之间存在直接关系:更准确的技术更容易被攻击
③开发一种防御机制,通过监测训练动态,完美地将中毒的例子与干净的例子分开
攻击原理
为了验证毒害半监督学习中的未标记数据能影响模型训练结果,我们设置一个攻击过程进行验证。
- 正常半监督学习
首先展示正常情况下的半监督学习过程:(设置两种已标识的样本,分别为o(红色)和x(蓝色),还有一个未标记样本,记为⊗)
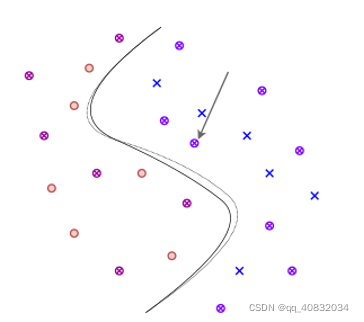
正常情况下,模型对已经标识的样本提取特征进行训练,上图是正确的决策边界。此时有一个未标记的样本⊗(它的正确标识为蓝色,但是我们想让它被分类为红色),因为他在被分类为蓝色的样本x周围,模型在训练的时候会将其正确归类为蓝色,没有实现我们想让它被分类为红色的目的。
- 被毒害未标记数据后的半监督学习
通过毒害上图位置的未标记样本,我们想它让⊗被分类为红色标签,毒害过程如下:
首先确定毒害目标样本x,期待标签(即我们想让它被分类为)y,在标签为y的样本中随机选取原样本x’(为了证实攻击有效,保证x’的标签不是y),毒害过程如下设置:
①在x’和x中间插入n个有毒样本x1、x2、……xn,通过插入的样本连接x’与x
②半监督学习模型训练时,由于x1离原样本x’很近,他会被分类为x’的标签y
同理,x2离x1也很近,也会被打上y的标记……最后x被分类为y
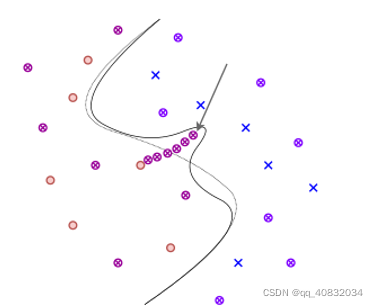
整个过程如上图所示,最终,未标记样本成功被分类为红色,攻击成功。(注意:上图插入样本nd的数量也就是毒害率)
数据集介绍
CIFAR-10是研究最多的半监督学习数据集,有10个类的50,000张图像
SVHN是一个更大的数据集,有604,388张门牌号码的图像,允许我们用更多的例子来评估我们攻击数据集的效果。
STL-10是一个为半监督学习设计的数据集。它只包含1000张带标签的图像(分辨率更高,为96 × 96),另外还有10万张来自类似(但不完全相同)分布的未带标签的图像,这使它成为我们最真实的数据集。
(因为CIFAR-10和SVHN最初是为完全监督训练设计的,所以他的数据都带有标签,半监督学习使用这些数据集时,除了少数示例(通常只有40或250个示例)外,会丢弃所有示例的标签。)
实验结果评估
跨源图像和目标图像进行评估
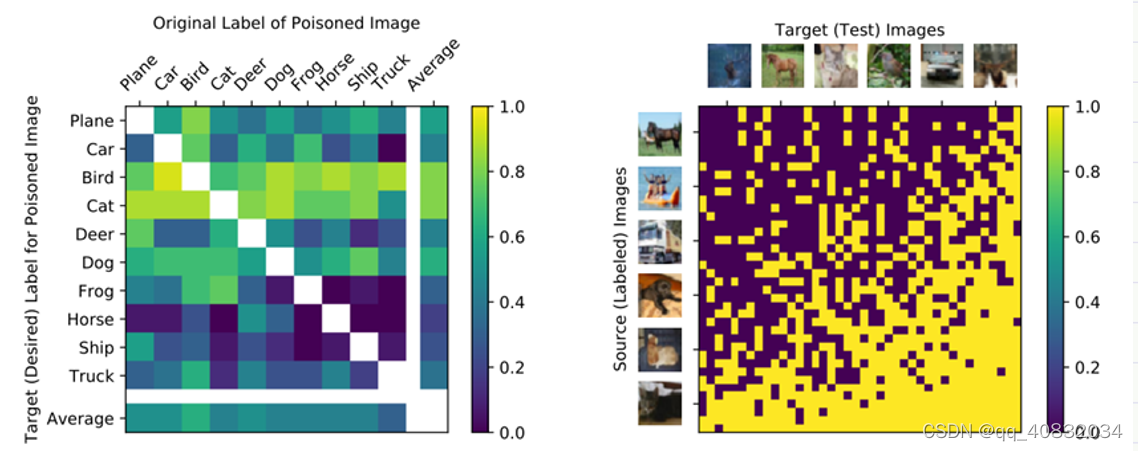
使用不同的原图像样本和目标图像攻击成功率不同,图二中黄色为攻击成功,紫色为攻击失败
跨训练技术(模型)评估
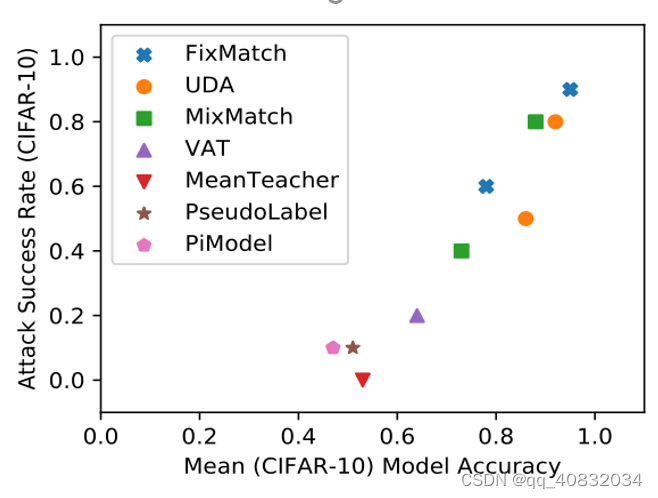
有七种半监督模型,其中FixMatch、UDA、MixMatch是较为先进的准确性较高的三种,其余四种是古老的准确率不高的训练方法。
可以发现,准确率越高,攻击成功率越大,猜测是更准确的模型可以更容易从数据中获得更多信息,从而让模型做错事情的能力越大。
跨数据集评估
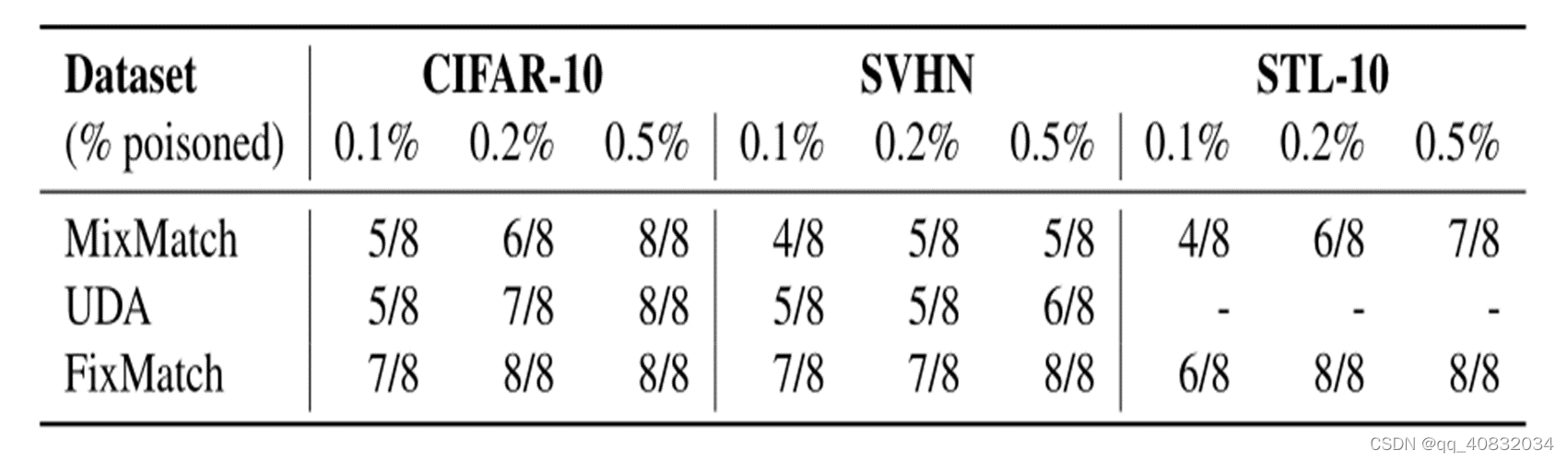
从中毒率评估
改变投毒率,分别放入40,250,400的插值数量。
插值越多,越容易攻击成功。
跨密度函数评估
密度函数,即不同位置插值的密度,发现最好的密度函数是p=1.5-x,使用这种密度函数可以让中毒过程成功传到目标样本。

除此之外,本文还证实了对无监督学习投毒成功行,就算不了解带标记数据也能成功攻击,同时,迁移学习更容易受到攻击,证实了这种攻击存在的广泛性。
防御措施
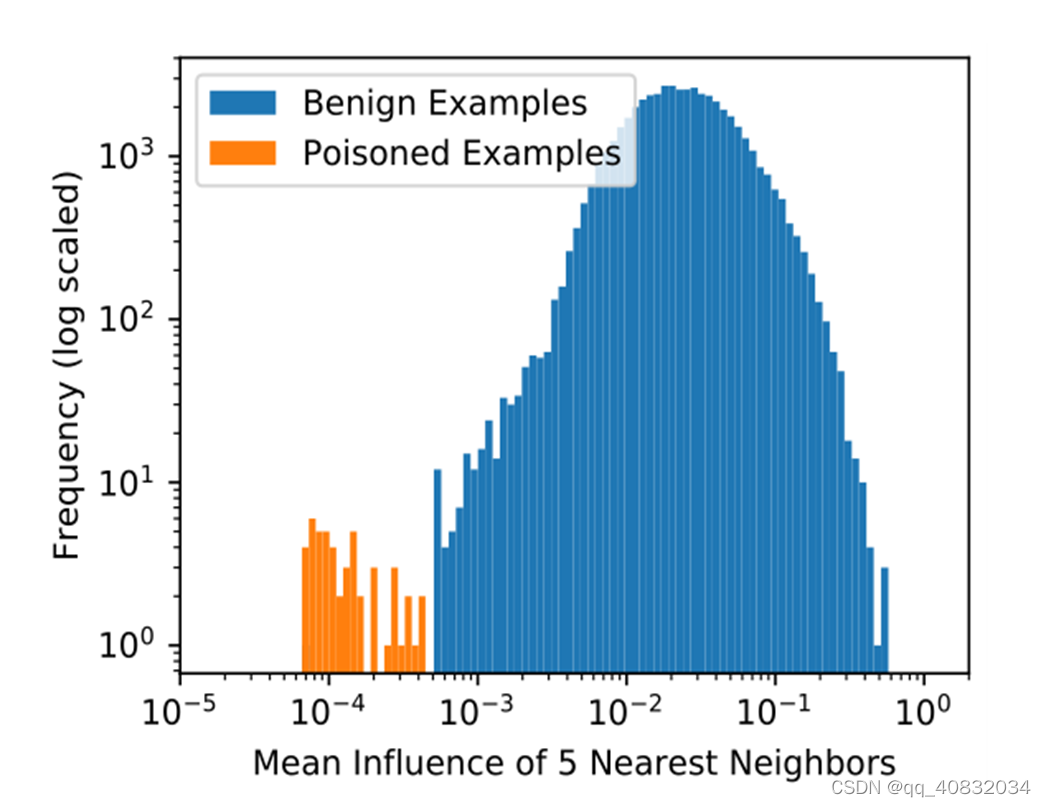
介于这种攻击的危害性,本文提出一种防御措施:监控训练动态,用于分离有毒样本和干净样本。
因为中毒的样本都是通过连接依次中毒的,所以有毒样本之间存在互相影响,而干净样本和干净样本以及干净样本和有毒样本之间则不存在影响关系。
定义影响的表达式,计算出每个样本受到的影响大小,成功分离有毒和干净标签。
总结
本文通过攻击半监督学习的未标记数据,证实了这种攻击对模型训练存在威胁,并且发现精确度更高的模型更容易被攻击,说明了单纯等待更精准的训练方法不能改善安全问题,需要更为有效的防御手段。最后,本文提出一种防御措施。


















 2634
2634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









