







故事过程:
公司本来有个A业务有两台logstash,之前按CPU利用率一直在40~50%左右吧,属于另一个小伙子Z一直跟进,忽然有一天CPU就开始报警,然后他也不清楚咋解决,就来找我一起处理。
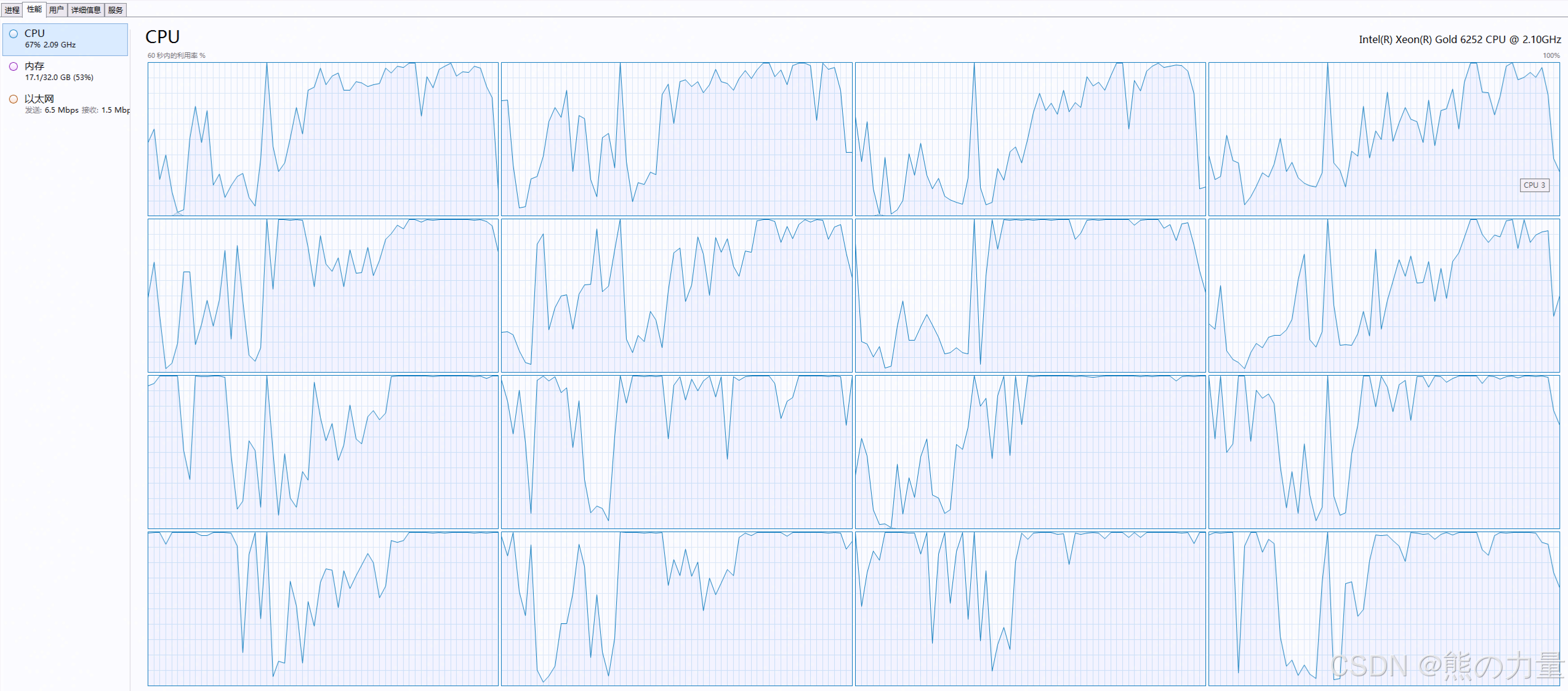
现象:logstash的CPU利用率突然增多,一直持续在100%,而且还存在日志延后问题,扩增CPU资源用处不大,后面新增了两个logstash节点,日志不延后了,但是CPU利用率还是很高。。。
排查过程:
1.观察索引的日志量,其实观察下来,日志缺失增多了,有两个多的增多了30%~50%,有一部分索引是正常的,所以,我们最开始觉得扩增CPU核数就OK,那就干!!!扩增完以后,果然有效果!嘿嘿,还有扩资源解决不了的事???不可能/傲娇,结果到了晚上,CPU接着跑满了,慌了慌了。

2.计划重启logstash服务,解决CPU利用率高的问题。毕竟是生产,这种事还是要悄咪咪的干,不过是高可用双节点,无所谓,莽就完了。冲冲冲!!!完球,哥们慌了,为啥logstash启动起来CPU就直接拉满,而且看运行日志全是报错,我问我另一个同事Z,他说问题不大,之前一直这样,这就对了!!!我一脸质疑,不过还是选择相信,毕竟老艺术家的从容与淡定。然后我俩就开始搞另一个节点,我去!!!另一个节点也一堆报错,慌了慌了。。。老艺术家也顶不住了啊。一顿慌乱,然后我们发现日志在我们重启的logstash的过程中出现了滞后问题,我俩就开始慌,一开始以为日志不传送了,后面决定让他运行一会看看,搜嘎!!!原来能继续传输,只不过消息有积压,过一段时间就好了。。。拿捏~,其实理由我俩都想好了,Z说发现日志有滞后问题,过来找我解决,经过我来一顿操作猛如虎,最后日志同步中,CPU因为要处理日志积压问题就比较高。哈哈哈哈哈哈,说的有鼻子有眼的,我都信了,拿捏~,让我们拭目以待

3.害!!!服了我都,咋还报警啊,日志我前天看都同步好了,CPU咋还报警,真烦,关键还没思路啊,硬着头皮去看日志吧。还真发现了俩问题:
[2025-02-13T00:00:08,677][WARN ][logstash.filters.kv ][main][d56775fd1fcfbcec3a2c73fa866ae5246b1b4f0f25a71902554353148819ff6e] Timeout reached in KV filter with value entry too large; first 255 chars are `"HOST=[aaaa] TID=[11] TIME=[2025-02-12 23:59:35.384] Type=[I] REFFUN=[tmesis.http.server.doService(18)] Msg=[{\"S-_MODULE\":\"server\",\"S-_SERVICE\":\"Service\",\"S-_CLIENT\":\"DESKTOP-U4F8AND\",\"S-SERVICE_FROM\":\"COMC\",\"S-CALL_SERVI"`
[2025-02-13T00:00:11,441][WARN ][logstash.outputs.elasticsearch][main][fa3aff76f47ae58bbd1bd4d1453ae4f0a17e77151f4dc3ad86a69b512dbbf01e] Could not index event to Elasticsearch. {:status=>400, :action=>["create", {:_id=>nil, :_index=>"MMEESS-2025.02.12", :routing=>nil}, {"REFFUN"=>"tmesis.service.Service.run(205)", "CHANNEL"=>"/PRDA/Server", "Type"=>"I", "HOST"=>"PRDA01", "EQUIP"=>"AAA-09-151", "TIME"=>"2025-02-13 00:00:00.868", "fields"=>{"logtopic"=>"plan", "factory"=>"AAA8", "app"=>"AAA3"}, "log"=>{"file"=>{"path"=>"d:\\PlantU\\Server\\log\\log.log"}, "flags"=>["multiline"], "offset"=>45652}, "RID"=>"20251232135", "TID"=>"460", "@timestamp"=>2025-02-12T16:00:00.868Z, "BEGIN_END"=>"BEGIN", "message"=>"[SERVICE] HOST=[PRDA01] RID=[2025123123123123] TID=[123] CHANNEL=[/PRDA/Server] TIME=[2025-02-13 00:00:00.868] CLIENT=[] CLIENTVER=[] Type=[I] SVC=[E2MQueryCarrierInforForERack] BEGIN_END=[BEGIN] EQUIP=[AAA-09-151] REFFUN=[tmesis.service.Service.run(205)] \nPARAMETER=[{\n \"S-_FACTORY\": \"AAA\",\n \"S-_LANGUAGE\": \"EN\",\n \"S-_PASSPORT\": \"\",\n \"S-_PASSWORD\": \"\",\n \"S-_USERID\": \"AAA\",\n \"S-OPERATOR_ID\": \"AAA\",\n \"S-EQUIP_ID\": \"AAA-09-151\",\n \"LT-CARRIER_LIST\": [\n {\n \"S-CARRIER_ID\": \"AAA017\"\n }\n ],\n \"STEP\": \"P\",\n \"S-_SERVICE\": \"E2Mk\",\n \"S-_MODULE\": \"EISM\"\n}]\n\tRequest Begin\n", "info"=>"HOST=[PRDA01] RID=[2025021123123123 TID=[460] CHANNEL=[/PRDA/Server] TIME=[2025-02-13 00:00:00.868] CLIENT=[] CLIENTVER=[] Type=[I] SVC=[EorERack] BEGIN_END=[BEGIN] EQUIP=[AAA-09-151] REFFUN=[tmesis.service.Service.run(205)] \n", "SVC"=>"ASDADASDADA", "MOLD"=>"SERVICE"}], :response=>{"create"=>{"_index"=>"AAA-2025.02.12", "_type"=>"_doc", "_id"=>"ZPzj-pQBWASPWzZbqJy-", "status"=>400, "error"=>{"type"=>"mapper_parsing_exception", "reason"=>"failed to parse field [EQUIP] of type [date] in document with id 'ZPzj-pQBWASPWzZbqJy-'. Preview of field's value: 'AAA-09-151'", "caused_by"=>{"type"=>"illegal_argument_exception", "reason"=>"failed to parse date field [AAA-09-151] with format [strict_date_optional_time||epoch_millis]", "caused_by"=>{"type"=>"date_time_parse_exception", "reason"=>"date_time_parse_exception: Failed to parse with all enclosed parsers"}}}}}}待老夫细细看来:
1)字符串超出限制。按照百度啥的查了查,调完limit参数,根本logstash服务都起不来。
2)400的报错网上说是单个node节点最大分片数为1000,我查了查我们改过这个设置了,我们是10000,而且目前 分片才2000多,不可能是这个问题。
3)主机名格式错误、时间格式错误。好好好,原来应用把日志格式改动了

4.好像知道报错了,又好像不知道。于是,就找一条日志放入在线grok debug中生成匹配格式,补充一条到logstash的匹配规则里面,重启logstash,生效。
似乎现在的在线debug工具不能用了,难崩。
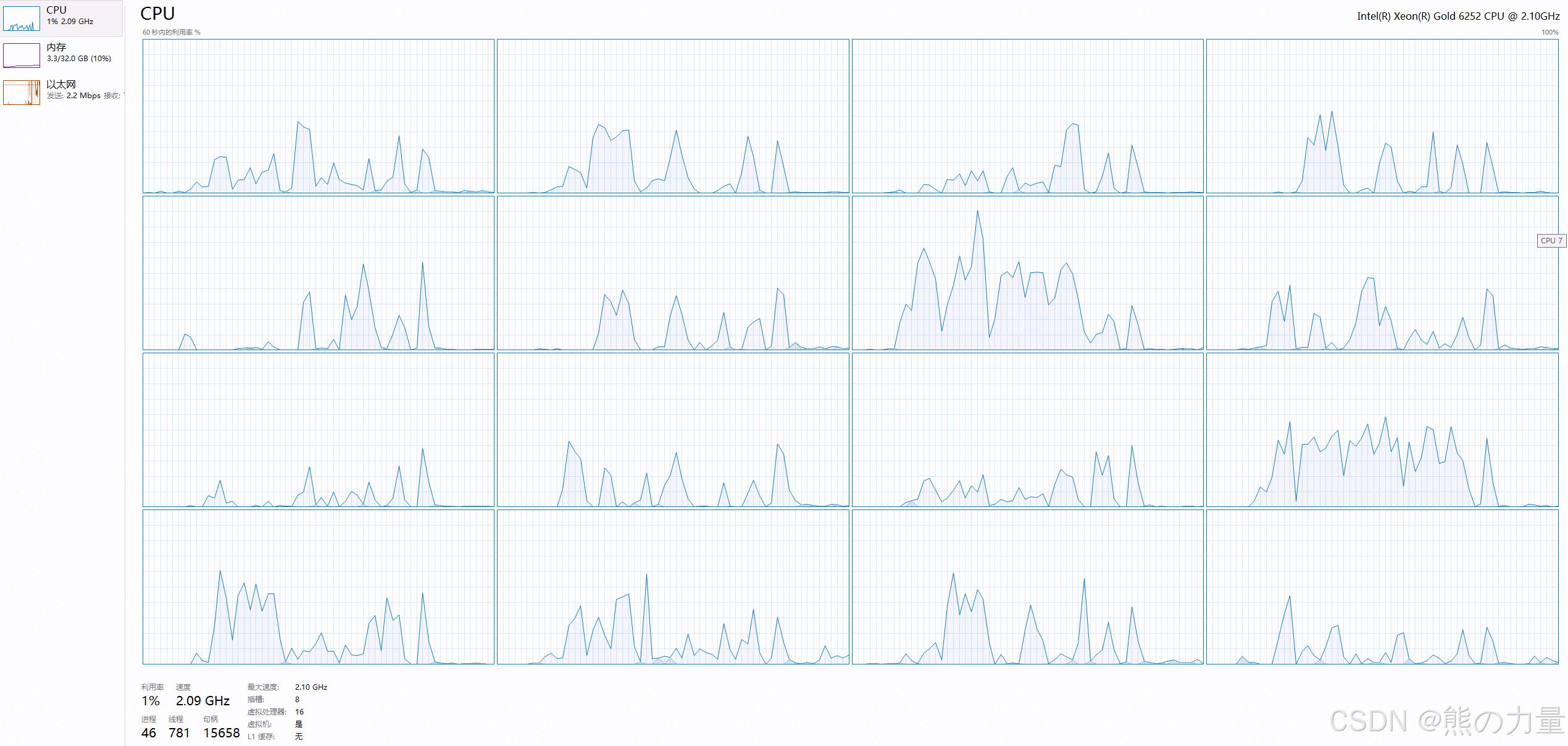
添加的是第一行,因为日志格式不匹配,而且logstash无法解析msg这个消息,所以就把msg这部分丢弃了,至此,CPU利用率降下来了。
"message" , "(?m)^\[%{WORD:MOLD}\] (?<info>(.*?)(?= Msg=\[))",
"message" , "(?m)^\[%{WORD:MOLD}\] (?<info>(.*?\n))"
input {
kafka {
id => "kafka"
client_id => "kafka"
bootstrap_servers => '192.168.20.73:9092,192.168.20.74:9092,192.168.20.75:9092'
topics => ["aaaaaa"]
codec => json { charset => "UTF-8" }
group_id => "bbb"
consumer_threads => 3
auto_offset_reset => earliest
decorate_events => false
}
}
filter {
grok {
match => [
"message" , "(?m)^\[%{WORD:MOLD}\] (?<info>(.*?)(?= Msg=\[))",
"message" , "(?m)^\[%{WORD:MOLD}\] (?<info>(.*?\n))"
]
}
kv {
source => "info"
}
mutate {
convert => {"DurTime" => "float"}
remove_field => ["host", "agent", "ecs", "tag", "@version", "input"]
}
date {
match => ["TIME", "yyyy-MM-dd HH:mm:ss.SSS", "yyyy-MM-dd HH:mm:ss.SSS", "ISO8601"]
timezone => "Asia/Shanghai"
target => "@timestamp"
}
}
output {
#stdout { codec => rubydebug }
elasticsearch {
hosts => ["192.168.20.76:9200", "192.168.20.86:9200", "192.168.20.87:9200"]
manage_template => true
action => "create"
data_stream => "auto"
index => ["aaa-%{[fields][logtopic]}-%{[fields][factory]}-%{[fields][app]}-%{+YYYY.MM.dd}"]
}
}
下降后的CPU利用率如下:


















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









