







本文主要完成如下目标:
1.ELK日志平台搭建
2.冷热数据分离
3.索引生命周期管理
4.filebeat、logstash等字段拆解配置
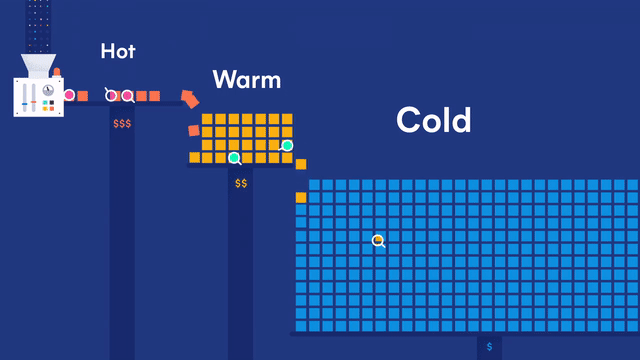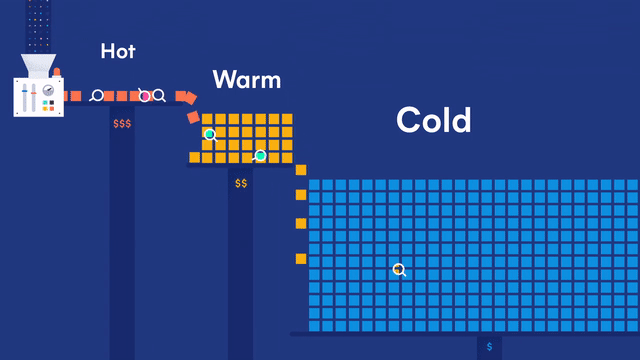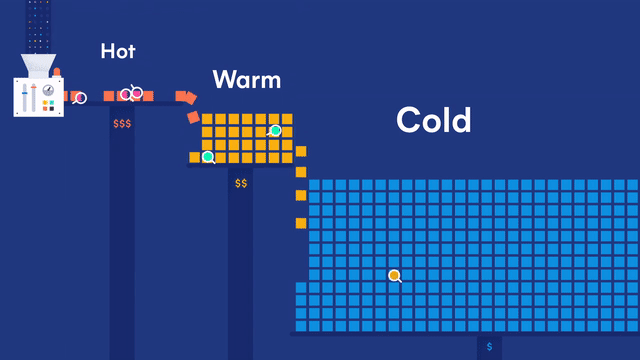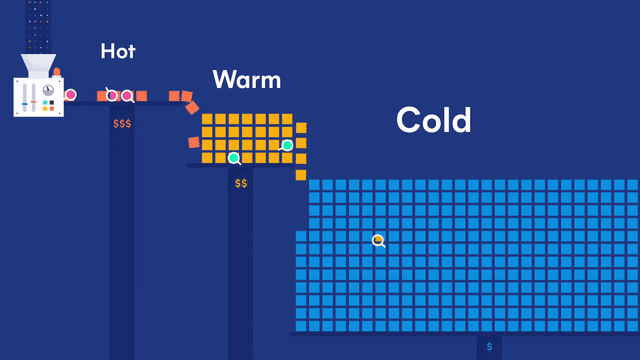
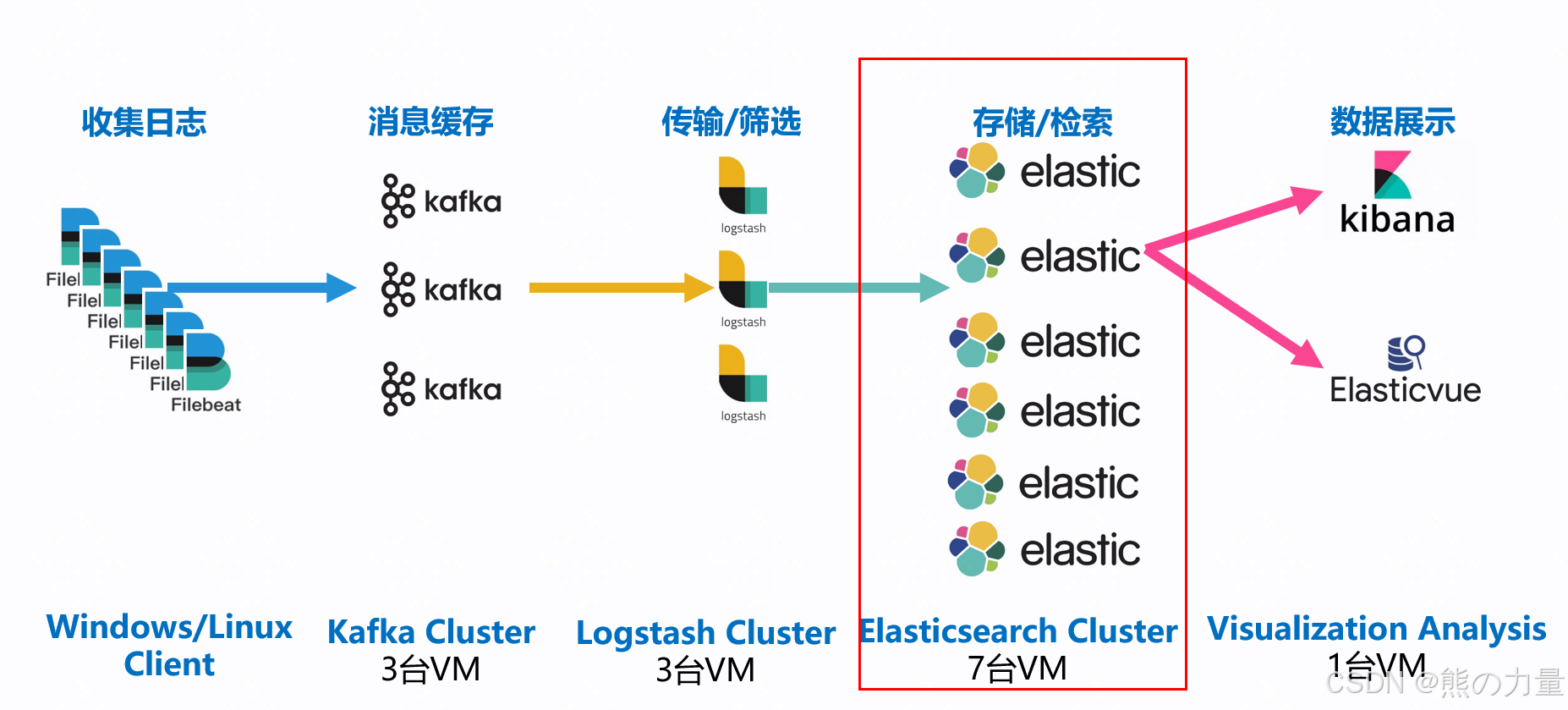
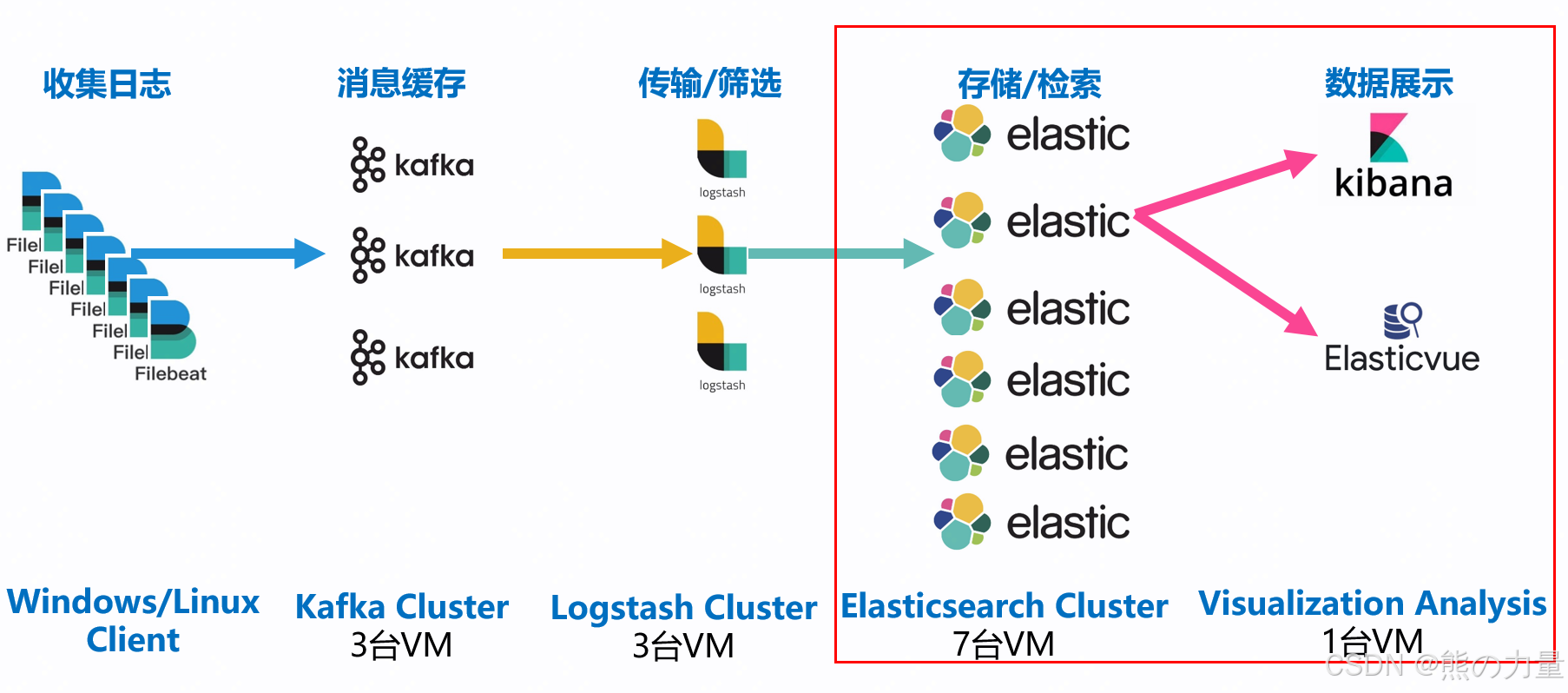
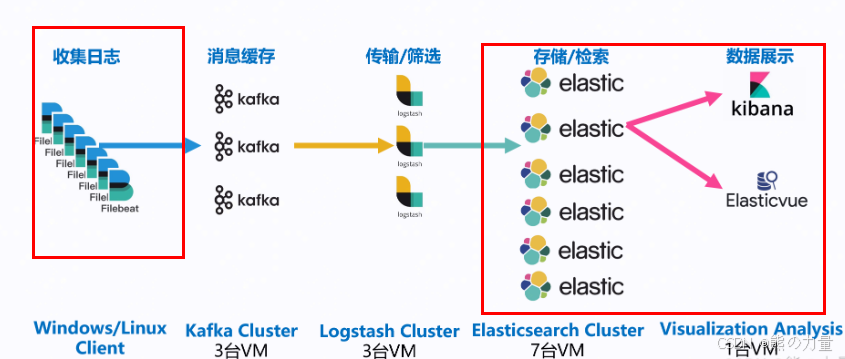
第一部分:ELK日志平台搭建
架构如下:
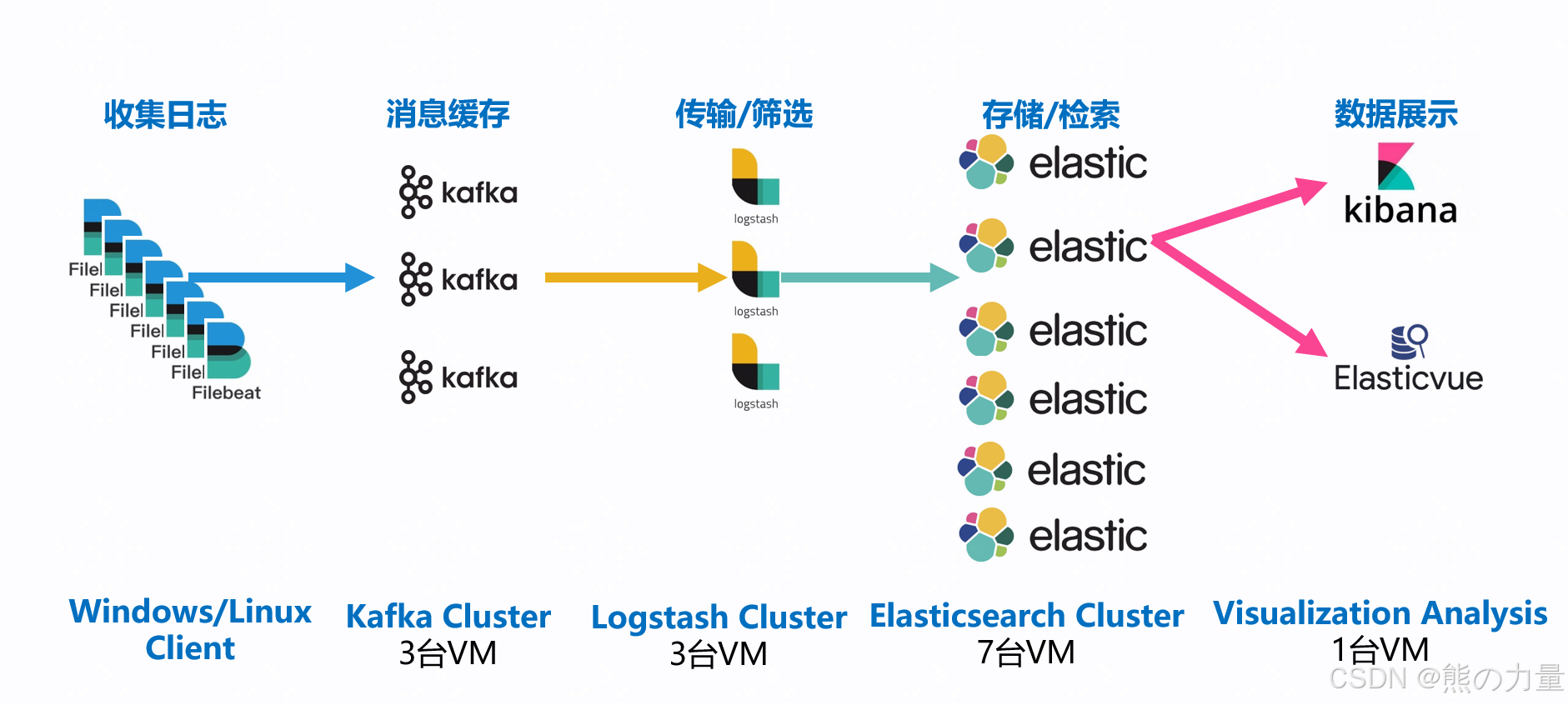
安装elasticsearch集群
准备3台redhat/centos的机器。(这种有手就行的活我就不写了),有条件的把集群整大点,哥们条件比较好,搞7台机器玩。
| 主机名 | IP地址 | 冷热节点 |
|---|---|---|
| elastic01 | 10.10.16.146 | hot |
| elastic02 | 10.10.16.147 | hot |
| elastic03 | 10.10.16.148 | hot |
| elastic04 | 10.10.16.149 | hot |
| elastic05 | 10.10.16.150 | hot |
| elastic06 | 10.10.16.152 | cold |
| elastic07 | 10.10.16.143 | cold |
修改下每台主机的主机名以及长短域名解析
hostnamectl set-hostname elastic01
echo "10.10.16.146 elastic01" >> /etc/hosts
#...其他省略,自己补充下就行
修改下内核参数,所有机器都修改
vim /etc/sysctl.conf #编辑文件
#文件内添加如下两行
fs.file-max=65536
vm.max_map_count=262144
##保存后立即生效
sysctl -p
修改单用户可以打开最大文件描述符数量,所有机器都修改
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536官网下载安装包 elasticsearch-8.14.1-x86_64.rpm,每台机器都安装运行一下,部署elasticsearch
yum install -y elasticsearch-8.14.1-x86_64.rpm每台机器添加1块磁盘,将磁盘挂载至/data目录,后面日志存/data目录下,做个磁盘挂载,目录赋权。
lsblk
vgcreate datavg /dev/sdb
lvcreate -l 100%free -n datalv datavg
lsblk
mkfs.xfs /dev/mapper/datavg-datalv
vim /etc/fstab
/dev/mapper/datavg-datalv /data xfs defaults 0 0
mount -a
[root@elastic01 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 3.8G 0 3.8G 0% /dev
tmpfs 3.9G 4.0K 3.9G 1% /dev/shm
tmpfs 3.9G 172M 3.7G 5% /run
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
/dev/mapper/centos-root 46G 3.6G 42G 8% /
/dev/sda1 1014M 151M 864M 15% /boot
/dev/mapper/datavg-datalv 200G 23G 177G 12% /data
tmpfs 781M 0 781M 0% /run/user/0
mkdir -p /data/elasticsearch
chown -R elasticsearch:elasticsearch /data/elasticsearch/
至此为止,只配置操作elastic01,不配置操作elastic02~elastic05!!!
至此为止,只配置操作elastic01,不配置操作elastic02~elastic05!!!
至此为止,只配置操作elastic01,不配置操作elastic02~elastic05!!
备份配置文件
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml_bak -a
cat /etc/elasticsearch/elasticsearch.yml | grep -Ev "^$|#" > /etc/elasticsearch/elasticsearch.yml_bak1
重要的话说三遍,编辑修改/etc/elasticsearch/elasticsearch.yml配置,node.roles和node.attr.node_type定义节点标签都可以,之前机器难得重启一次,我怕测试都不成功,两种方式都用了。
如下配置是添加了ssl证书的
[root@elastic01 ~]# cat /etc/elasticsearch/elasticsearch.yml
cluster.name: OA-ELK
node.name: elastic01
path.data: /data/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 10.10.16.146
node.roles: ["master","data","data_hot","data_content","ingest","ml","remote_cluster_client","transform"] #定义节点角色
node.attr.node_type: hot #冷热节点标签
discovery.seed_hosts: ["10.10.16.146","10.10.16.147","10.10.16.148","10.10.16.149","10.10.16.150"]
xpack.security.enabled: true
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:
enabled: true
keystore.path: certs/http.p12
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: certs/transport.p12
truststore.path: certs/transport.p12
cluster.initial_master_nodes: ["elastic01"]
#cluster.initial_master_nodes: ["elastic01","elastic02","elastic03"]
http.host: 0.0.0.0
transport.host: 0.0.0.0
cluster.routing.allocation.same_shard.host: true #禁止把副本分配到同一台物理机器上(相同ip地址认为是同一台机器)
cluster.routing.allocation.disk.watermark.low: "85%" #意味着 Elasticsearch 不会将分片分配给磁盘使用率超过 85% 的节点
cluster.routing.allocation.disk.watermark.high: "90%" #意味着 Elasticsearch 将尝试将分片从磁盘使用率高于 90% 的节点,开始挪分片去其他节点。
cluster.routing.allocation.disk.watermark.flood_stage: "95%" #节点上分配了一个或多个分片并且至少有一个磁盘超过洪水阶段的每个索引强制执行只读索引块
cluster.info.update.interval: "30s" #多久检查一次集群中每个节点的磁盘使用情况。
#cluster.routing.allocation.disk.include_relocations: true #计算磁盘使用率时是否考虑当前分配的分片。
cluster.routing.allocation.disk.threshold_enabled: true #这启用和禁用磁盘分配决策程序。
http.max_content_length: "500mb"
http.max_initial_line_length: "100kb"
http.max_header_size: "40kb"
启动elasticsearch服务,并且设置开机自启动
systemctl restart elasticsearch.service
systemctl enable elasticsearch.service
检查下集群状态
systemctl status elasticsearch.service
修改ES账号和密码,并且创建其他ES节点加入集群的token。
默认安装好的ES集群会给elastic账户一个高度复杂的随机密码,密码在安装日志里,想去看的自己查,我也没查过,直接重置就好。进入/usr/share/elasticsearch/bin/目录
cd /usr/share/elasticsearch/bin/
./elasticsearch-reset-password -u elastic -i
#弹框 y
#连续输入两次密码
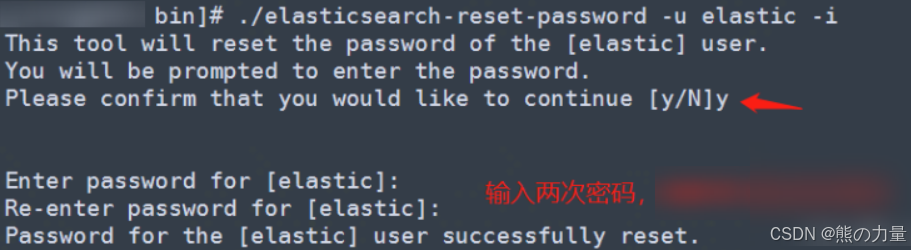
#目录下
在elastic01上创建其他节点加入ES集群的token
[root@elastic01 ~]#/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node
eyJ2ZXIiOiI4LjE0LjAiLCJhZHIiOlsiMTAuMTAuMTYuMTQ2OjkyMDAiXSwiZmdyIjoiYWM1NmQ5ZjBiYmEzZTI0ZTExZDRkNGZmOGI0MjExNTYyYWQ0NGRmMWE5ODU3YTk4YTE2ZmVmMTYyM2
MyMTRlZiIsImtleSI6InB2ekliSkFCTl9oUm02d1ZWMVZWOkh6SEZRbXRxUlpDVGhOZmNOYTVTb2cifQ==在其他节点上导入刚才elastic01上生成的token,命令后带着token,这一串token不要有任何回车或者中断,在其他节点导入,导入过程输入"y"
/usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token eyJ2ZXIiOiI4LjE0LjAiLCJhZHIiOlsiMTAuMTAuMTYuMTQ2OjkyMDAiXSwiZmdyIjoiYWM1NmQ5ZjBiYmEzZTI0ZTExZDRkNGZmOGI0MjExNTYyYWQ0NGRmMWE5ODU3YTk4YTE2ZmVmMTYyM2
MyMTRlZiIsImtleSI6InB2ekliSkFCTl9oUm02d1ZWMVZWOkh6SEZRbXRxUlpDVGhOZmNOYTVTb2cifQ==
修改完elastic02~05的配置,启动ES
[root@a-oa-elk-elastic-prod02 ~]# cat /etc/elasticsearch/elasticsearch.yml
cluster.name: OA-ELK
node.name: elastic02
path.data: /data/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 10.10.16.147
node.roles: ["master","data","data_hot","data_content","ingest","ml","remote_cluster_client","transform"]
node.attr.node_type: hot
discovery.seed_hosts: ["10.10.16.146","10.10.16.147","10.10.16.148","10.10.16.149","10.10.16.150"]
cluster.initial_master_nodes: ["elastic01"]
#cluster.initial_master_nodes: ["elastic01","elastic02","elastic03"]
xpack.security.enabled: true
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:
enabled: true
keystore.path: certs/http.p12
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: certs/transport.p12
truststore.path: certs/transport.p12
http.host: 0.0.0.0
transport.host: 0.0.0.0
cluster.routing.allocation.same_shard.host: true #禁止把副本分配到同一台物理机器上(相同ip地址认为是同一台机器)
cluster.routing.allocation.disk.watermark.low: "85%" #意味着 Elasticsearch 不会将分片分配给磁盘使用率超过 85% 的节点
cluster.routing.allocation.disk.watermark.high: "90%" #意味着 Elasticsearch 将尝试将分片从磁盘使用率高于 90% 的节点,开始挪分片去其他节点。
cluster.routing.allocation.disk.watermark.flood_stage: "95%" #节点上分配了一个或多个分片并且至少有一个磁盘超过洪水阶段的每个索引强制执行只读索引块
cluster.info.update.interval: "30s" #多久检查一次集群中每个节点的磁盘使用情况。
#cluster.routing.allocation.disk.include_relocations: true #计算磁盘使用率时是否考虑当前分配的分片。
cluster.routing.allocation.disk.threshold_enabled: true #这启用和禁用磁盘分配决策程序。
http.max_content_length: "500mb"
http.max_initial_line_length: "100kb"
http.max_header_size: "40kb"
systemctl restart elasticsearch.service
systemctl enable elasticsearch.service
systemctl status elasticsearch.service浏览器访问集群内任何一个节点9200端口,输入elastic和刚才重置的密码
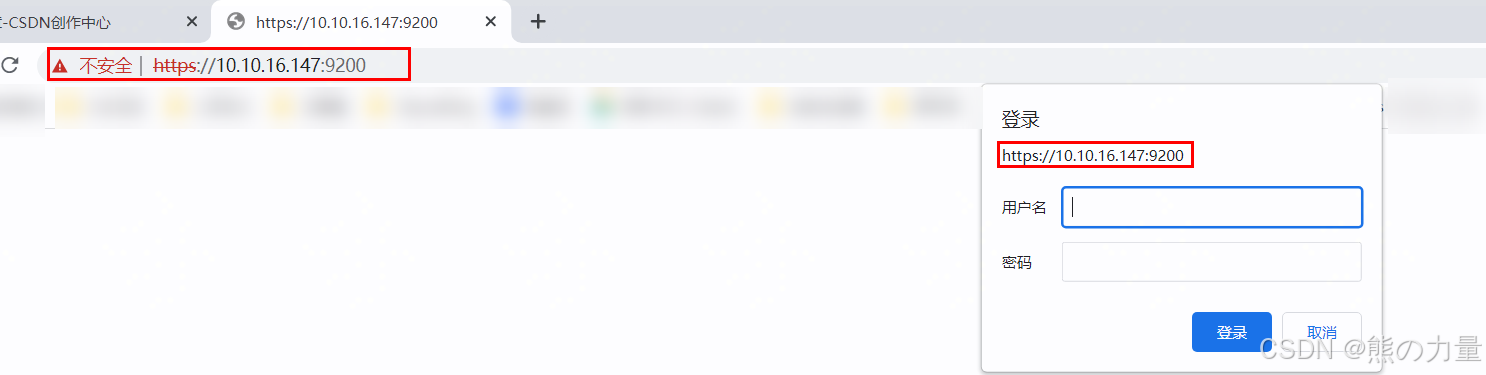
输入后下图:
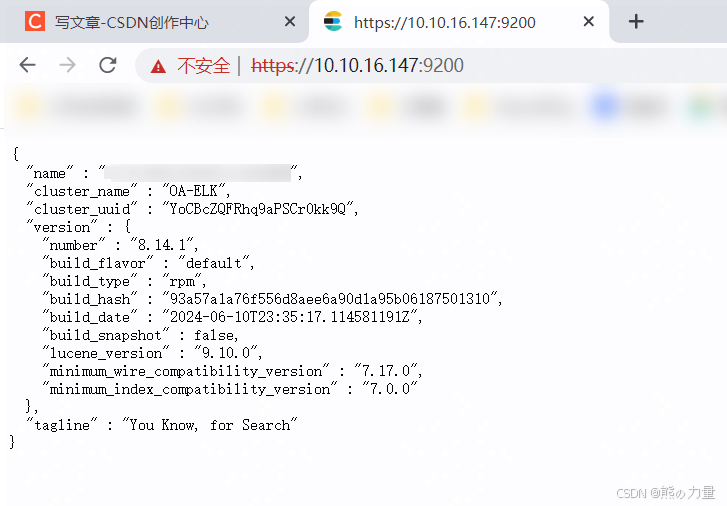
ES集群管理可以使用浏览器扩展插件ES-head,但是公司不让随意下载安装东西,一言难尽。
自己查查行了,简单的一
至此,完成如下部分:
安装kibana
打开kibana的机器 kibana01
yum install kibana-8.14.1-x86_64.rpm修改kibana配置文件,然后启动kibana
[root@kibana01 ~]# cat /etc/kibana/kibana.yml
server.port: 5601
server.host: "10.10.16.151"
server.publicBaseUrl: "https://10.10.16.151:5601"
server.ssl.enabled: true
server.ssl.certificate: /etc/kibana/gongsi.crt #使用的公司泛域名证书,自签证书配置后续补充
server.ssl.key: /etc/kibana/gongsi.key #使用的公司泛域名证书,自签证书配置后续补充
logging:
appenders:
file:
type: file
fileName: /var/log/kibana/kibana.log
layout:
type: json
root:
appenders:
- default
- file
pid.file: /run/kibana/kibana.pid
i18n.locale: "zh-CN"启动kibana服务
systemctl start kibana
systemctl status kibana
systemctl enable kibana
netstat -tlunp | grep 5601 #检查端口启动状态登录elastic01机器
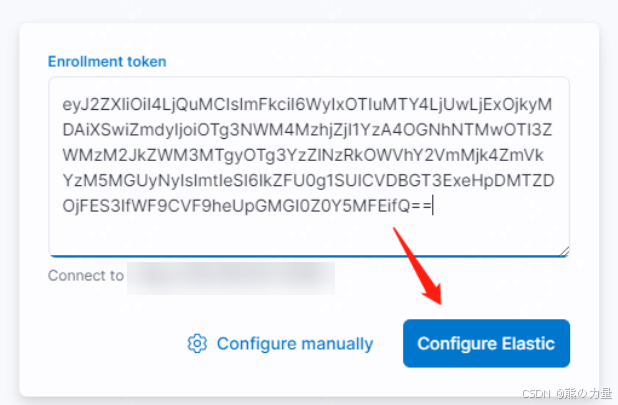
/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana
eyJ2ZXIiOiI4LjQuMCIsImFkciI6WyIxOTIuMTY4LjUwLjExOjkyMDAiXSwiZmdyIjoiOTg3NWM4MzhjZjI
1YzA4OGNhNTMwOTI3ZWMzM2JkZWM3MTgyOTg3YzZlNzRkOWVhY2VmMjk4ZmVkYzM5MGUyNyIsImtleSI6IkZFU0
g1SUlCVDBGT3ExeHpDMTZDOjFES3lfWF9CVF9heUpGMGI0Z0Y5MFEifQ==登录https://10.10.16.151:5601
将elastic01刚刚生成的token粘贴进去
提示输入验证码,验证码需要在 kibana 服务上生成(有些远程 ssh 工具执行命令验证码可能会 显示不出来,可以直接在系统命令界面去执行命令就可以看见验证码了)。
[root@kibana kibana]# cd /usr/share/kibana/bin/
[root@kibana bin]# ls
[root@kibana bin]# ./kibana-verification-code
Your verification code is: 974 086输入生成的验证码连接。
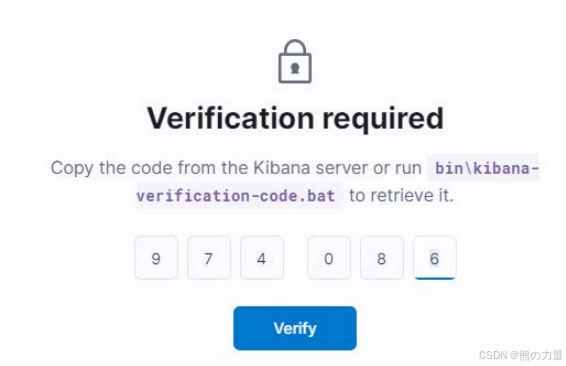
输入验证码后,就会跳转到登录窗口可以登录使用了。用户可以用 ES 上的账户 elastic,密 码就是前面 ES 重置的
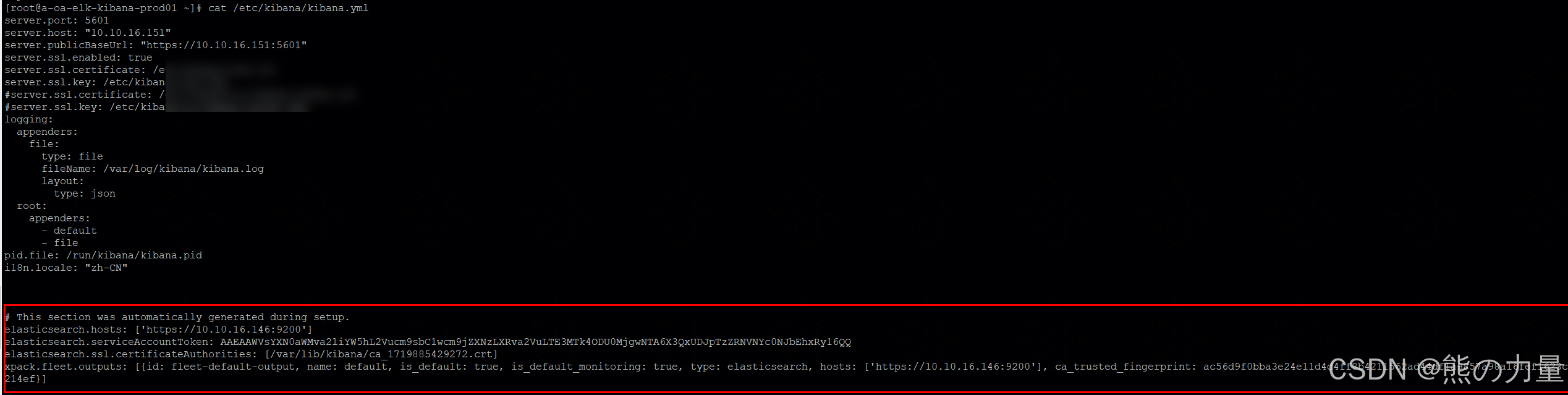
后续查看下面自动生成的配置文件,不用管
至此,完成如下部分:
接下来先部署filebeat吧,这样可以从日志源头一边配置一边排错印证。
安装filebeat
yum install filebeat-8.14.1-x86_64.rpm -y配置filebeat文件
[root@oa-email-nginx-prod01 filebeat]# cat /etc/filebeat/filebeat.yml
filebeat.config:
inputs:
enabled: true
path: inputs.d/*.yml #/etc/filebeat目录下创建inputs.d目录,以.yml结尾的文件可以匹配,方便对同一台机器上不通业务日志进行收集管理
reload.enabled: true
reload.period: 30s
modules:
enabled: true
path: ${path.config}/modules.d/*.yml
reload.enabled: true
reload.period: 30s
logging.metrics.enabled: false
setup.template.enabled: true
logging.level: info
logging.to_files: true
logging.files:
path: /var/log/filebeat
name: filebeat
keepfiles: 7
permissions: 0600
output.kafka:
hosts: ["10.10.16.140:9092","10.10.16.141:9092","10.10.16.142:9092"] #kafka的地址和端口
topic: "%{[app]}"
sasl.mechanism: "PLAIN"
在/etc/filebeat目录下创建inputs.d目录
mkdir /etc/filebeat/inputs.d在/etc/filebeat/inputs.d目录下创建nginx应用的日志收集文件oa_email_nginx.yml
[root@nginx01 inputs.d]# cat /etc/filebeat/inputs.d/oa_email_nginx.yml
- type: log
paths:
- /var/log/nginx/proxy.log #nignx日志路径
ignore_older: 24h
multiline.type: pattern
multiline.pattern: '^(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})' #匹配nginx日志匹配行首字符,完成日志换行,防止多行日志出现在elk一条日志中
multiline.negate: true
multiline.match: after
fields_under_root: true
fields:
app: oa_email_proxy_prd #自定定义一个app标签名,该名称就是kafka上的topic名称
app_alias: oa_eml_prd #定义日志别名
- type: log
paths:
- /var/log/nginx/error.log
ignore_older: 24h
multiline.type: pattern
multiline.pattern: '^\d{4}'
multiline.negate: true
multiline.match: after
fields_under_root: true
fields:
app: oa_email_error_prd
app_alias: oa_eml_prd
观察下图为/var/log/nginx/proxy.log的日志
192.168.156.112 54535 - [11/Feb/2025:13:55:34 +0800] 200 TCP "192.168.17.3:25" "14850" "0.000"
192.168.156.112 54536 - [11/Feb/2025:13:55:34 +0800] 200 TCP "192.168.17.1:25" "14850" "0.000"所以filebeat中日志换行的配置为 multiline.pattern: '^(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})' ,
其实上述配置为 0.0.0.0~999.999.999.999 ,不过匹配IP地址的目的是区分日志行,够用就行。
观察下图为/var/log/nginx/error.log的日志
2025/02/08 22:08:36 [error] 124009#124009: *65028291 upstream timed out (110: Connection timed out) while connecting to upstream, client: 192.168.148.5, server: 0.0.0.0:25, upstream: "192.168.17.5:25", bytes from/to client:0/0, bytes from/to upstream:0/0
2025/02/08 23:05:00 [error] 124009#124009: *65044866 upstream timed out (110: Connection timed out) while connecting to upstream, client: 192.168.156.113, server: 0.0.0.0:25, upstream: "192.168.17.5:25", bytes from/to client:0/0, bytes from/to upstream:0/0
所以filebeat中error日志的行首匹配为 multiline.pattern: '^\d{4}'
启动filebeat服务,设置开机自启动
systemctl restart filebeat
systemctl status filebeat
systemctl enable filebeat下图红框部分配置完成
######这部分为其他业务系统的一些配置,纯粹记录
[root@app01 inputs.d]# cat ebs_cm_prod.yml
- type: log
paths:
- /var/log/eblogs/info.log
ignore_older: 24h
multiline.type: pattern
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}' #匹配日期
multiline.negate: true
multiline.match: after
fields_under_root: true
fields:
app: ebs_cm_info_prod
app_alias: ebs_cm_prod
- type: log
paths:
- /var/log/logs/eberror.log
ignore_older: 24h
multiline.type: pattern
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}' #匹配日期
multiline.negate: true
multiline.match: after
fields_under_root: true
fields:
app: ebs_cm_error_prod
app_alias: ebs_cm_prod
[root@ebs-oa-new-test01 inputs.d]# cat ebs_oa_test.yml
- type: log
paths:
- /usr/weaver/Resin4/log/stdout.log
encoding: gbk #系统ELK日志中文部分全部为乱码,encoding调整
ignore_older: 24h
multiline.type: pattern
multiline.pattern: '^\[' #匹配[开头的
multiline.negate: true
multiline.match: after
fields_under_root: true
fields:
app: ebs_oa_info_test
app_alias: ebs_oa_test
日志
[2025.02.12 15:45:56.422]2025-02-12 15:45:56,422 INFO A2 - [null] resin-port-80-365-365[com.engine.workflow.biz.requestForm.RequestFormBiz:211] - jym-------------��ֶתkeyʱ0######上面部分为一些记录
部署KAFKA作为日志消息缓存
再一些日志量大的业务系统,应用繁多、日志量大,如果filebeat或者logstash的日志直接发给es,es集群会有一定压力,避免日志接收问题,引入消息队列作为缓存。
kafka在2.8.0版本以后移除zookeeper,使用的kraft协议
tar zxf kafka_2.13-3.7.0.tgz -C /opt/
ln -s /opt/kafka_2.13-3.7.0/ /opt/kafka
mkdir /data/kafka/logs -p
cd /opt/kafka/config/kraft/
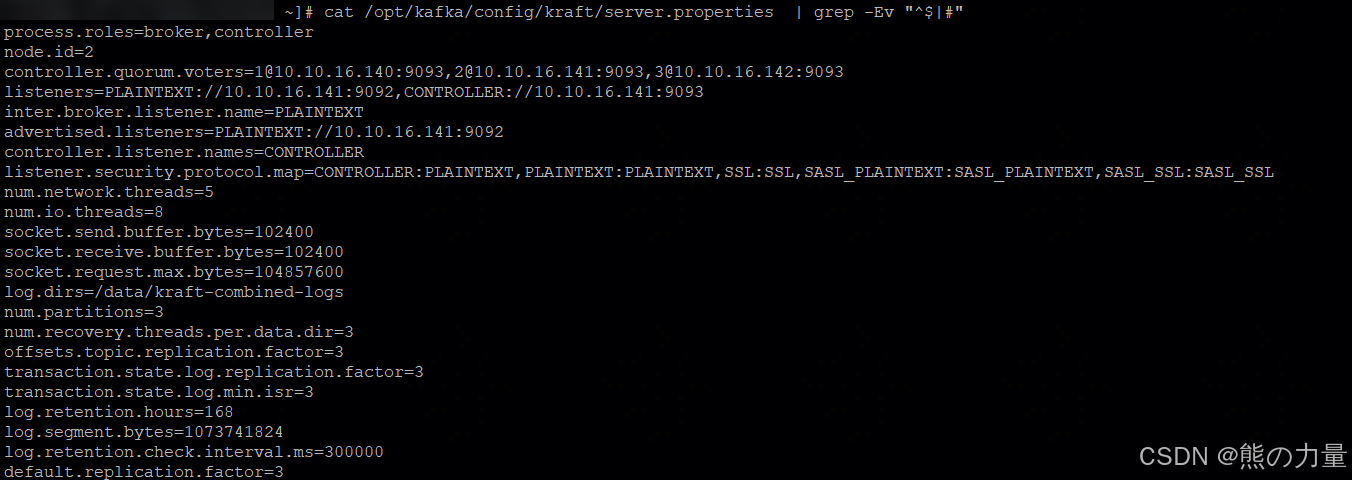
[root@kafka-prod01 ~]# cat /opt/kafka/config/kraft/server.properties | grep -Ev "^$|#"
process.roles=broker,controller
node.id=1 #KAFKA的broker节点ID
controller.quorum.voters=1@10.10.16.140:9093,2@10.10.16.141:9093,3@10.10.16.142:9093 #kafka controller投票者配置
listeners=PLAINTEXT://10.10.16.140:9092,CONTROLLER://10.10.16.140:9093 #kafka broker监听端口
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://10.10.16.140:9092 #节点自己的监听地址
controller.listener.names=CONTROLLER
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
num.network.threads=5
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kraft-combined-logs #日志存储位置
num.partitions=3
num.recovery.threads.per.data.dir=3
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
default.replication.factor=3同理配置kafka-02、kafka03节点
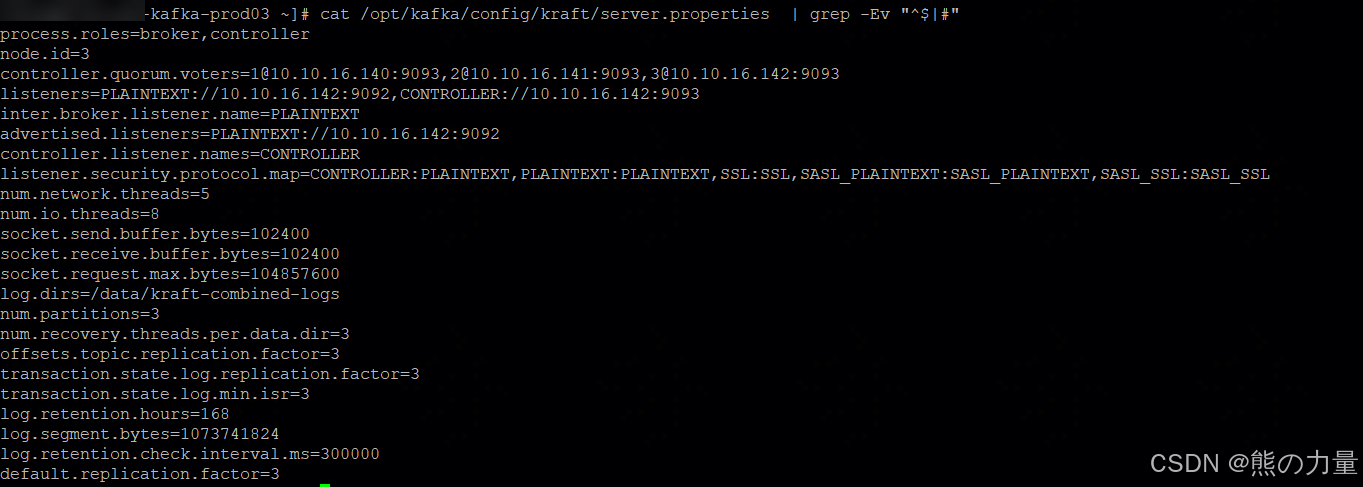
创建kraft集群,执行生成集群id命令,生成随机生成的字符串
[root@a-oa-elk-kafka-prod03 ~]# ll /opt/kafka/bin/kafka-storage.sh
-rwxr-xr-x 1 root root 860 Feb 9 2024 /opt/kafka/bin/kafka-storage.sh
[root@a-oa-elk-kafka-prod03 ~]# /opt/kafka/bin/kafka-storage.sh random-uuid
kDyxWJx7SoCOnv26k8zvXw然后分别在三台机器上执行如下命令,分别在几台服务器上面使用集群ID格式化目录:
cd /opt/kafka
bin/kafka-storage.sh format -t kDyxWJx7SoCOnv26k8zvXw -c config/kraft/server.properties上面命令执行完成后,配置的数据目录将会生成两个文件,其中 bootstrap.checkpoint 是一个二进制文件,meta.properties 是元数据文件:


然后执行如下命令,经验是最好同时运行,我之前时间间隔长一些,创建出的集群存在异常。
#后台启动:
/opt/kafka/bin/kafka-server-stop.sh -daemon /opt/kafka/config/kraft/server.propertie
# 前台启动:
/opt/kafka/bin/kafka-server-stop.sh /opt/kafka/config/kraft/server.propertie添加开机自启动
echo "/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/kraft/server.properties" >>/etc/rc.local一些KAFKA命令,测试使用的时候修改下地址
# 以下所有命令都是以test-topic主题为示例,test-group消费者组为示例
# 1. 创建主题:(test-topic 主题名;replication-factor 副本数量,副本是包含leader的,如果某个topic有副本,该值至少要配置为2)
$ ./bin/kafka-topics.sh --bootstrap-server 192.168.56.101:9092 --create --topic test-topic --partitions 3 --replication-factor 2
# 2. 查看主题:
$ ./bin/kafka-topics.sh --bootstrap-server 192.168.56.101:9092 --describe --topic test-topic
# 3. 删除主题:
$ ./bin/kafka-topics.sh --bootstrap-server 192.168.56.101:9092 --delete --topic test-topic
# 4. 列出主题列表
$ ./bin/kafka-topics.sh --bootstrap-server 192.168.56.101:9092 --list
# 5. 调整分区数量
$ ./bin/kafka-topics.sh --bootstrap-server 192.168.56.101:9092 -alter --partitions 4 --topic test-topic
# 6. 查看消费者组信息
$ ./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.56.101:9092 --list
# 7. 查看某个消费者组消费情况
$ ./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.56.101:9092 --group test-group --describe
# 8. 在控制台向某个主题写入数据:
$ ./bin/kafka-console-producer.sh --broker-list 192.168.56.101:9092,192.168.56.102:9092,192.168.56.103:9092 --topic test-topic
# 9. 在控制台消费某个主题数据
$ ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.56.101:9092,192.168.56.102:9092,192.168.56.103:9092 --topic test-topic
# 10. 指定消费10条数据
$ ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.56.101:9092 --topic test-topic --max-messages 10
# 在控制台消费数据时还可以添加参数:
# 最早数据开始消费:--from beginning
# 删除offsets并重新开始消费:--delete-consumer-offsets --from beginning
# 指定消费者组相关信息:--consumer.config ./config/consumer.properties
------
# 下面这些是不怎么常用的命令,没有验证过作为记录供参考:
# 更改主题配置信息:
./bin/kafka-configs.sh --bootstrap-server 192.168.56.101:9092 --entity-type topics --entity-name test-topic --alter --add-config max.message.bytes=128000
# 查看主题配置信息:
./bin/kafka-configs.sh --bootstrap-server 192.168.56.101:9092 --entity-type topics --entity-name test-topic --describe
# 删除配置:
./bin/kafka-configs.sh --bootstrap-server 192.168.56.101:9092 --entity-type topics --entity-name test-topic --alter --delete-config max.message.bytes
# 将test topic的消费组的0分区的偏移量设置为最新
./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.56.101:9092,192.168.56.102:9092,192.168.56.103:9092 --group test-group --topic test-topic:0 --reset-offsets --to-earliest –execute
# 将test topic的消费组的0和1分区的偏移量设置为最旧
./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.56.101:9092,192.168.56.102:9092,192.168.56.103:9092 --group test-group --topic test-topic:0,1 --reset-offsets --to-latest –execute
# 将test topic的消费组的所有分区的偏移量设置为1000
./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.56.101:9092,192.168.56.102:9092,192.168.56.103:9092 --group test-group --topic test-topic --reset-offsets --to-offset 1 –execute
# --reset-offsets后可以跟的其他用法:--to-current:把位移调整到分区当前位移
# --reset-offsets后可以跟的其他用法:--shift-by N: 把位移调整到当前位移 + N处,注意N可以是负数,表示向前移动
# --reset-offsets后可以跟的其他用法:--to-datetime <datetime>:把位移调整到大于给定时间的最早位移处,datetime格式是yyyy-MM-ddTHH:mm:ss.xxx,比如2017-08-04T00:00:00.000
除上述一些命令外,还可以安装kafka-ui的服务用于方便管理,安装docker就不说了。
docker load < kafka-ui_v0.4.0.tar
docker ps
docker image ls
##看下docker-compose的配置
[root@a-oa-elk-kafka-prod01 ~]# cat docker-compose.yml
version: '3'
services:
kafkaui:
image: '10.13.164.50:80/public/provectuslabs/kafka-ui:v0.4.0'
container_name: kafkaui
network_mode: "bridge"
restart: always
ports:
- "8080:8080"
environment:
- KAFKA_CLUSTERS_0_NAME=F84NuqVqSFmncQmlHv1RQQ
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=10.10.16.140:9092,10.10.16.141:9092,10.10.16.142:9092
##
docker compose up -d检查端口并且用浏览器访问,点击topic可以看到filebeat中写的app名称的topic。
[root@kafka-prod01 ~]# netstat -tlunp | grep 8080
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 97368/docker-proxy
tcp6 0 0 :::8080 :::* LISTEN 97375/docker-proxy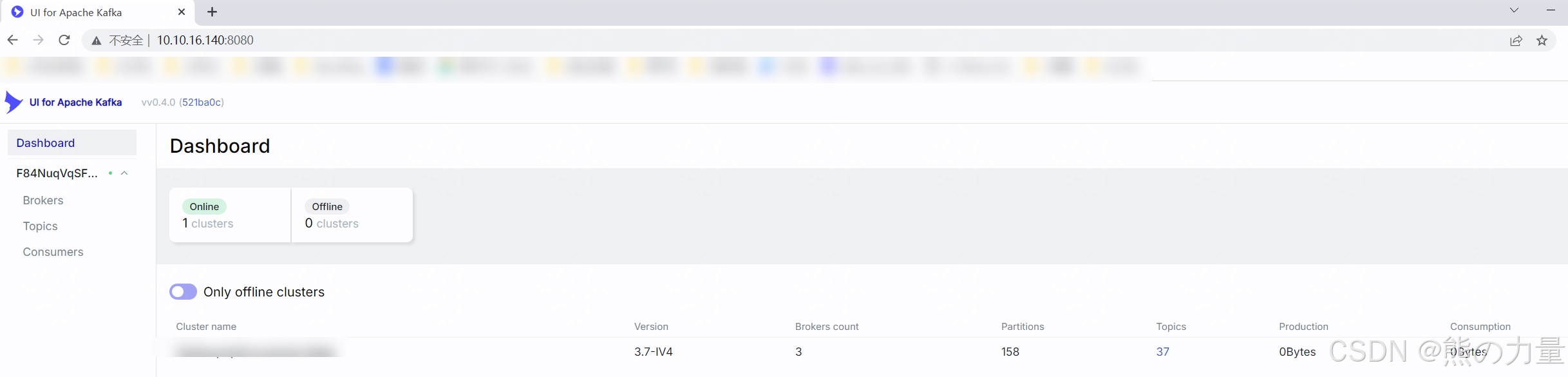
至此,下图中红框部分配置完成。
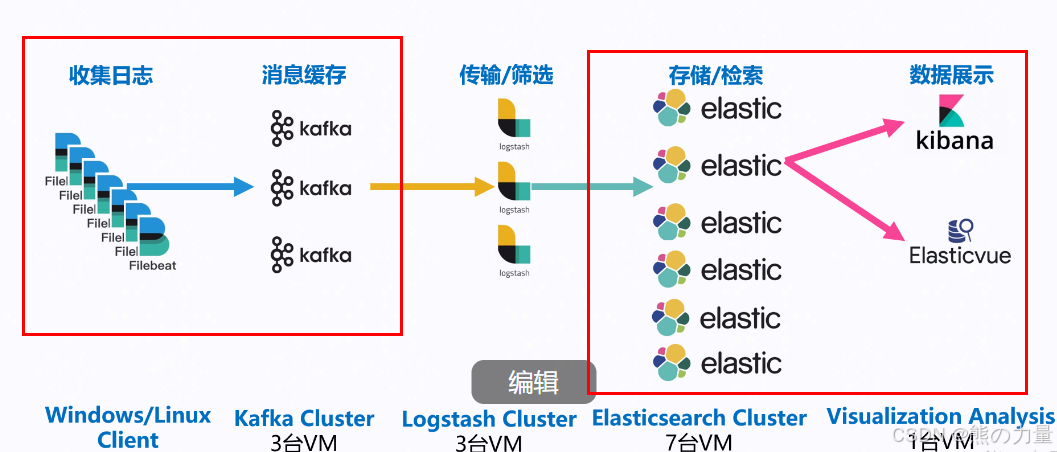
最后一步,安装logstash。
常规安装logstash
yum install /tmp/logstash-8.14.1-x86_64.rpm不过我使用systemctl restart logstash服务后,CPU就一直使用率100%,我也不知道咋回事,索性就直接使用进程直接跑,不用服务了。
mkdir /data/logstashconf在此目录下写/data/logstashconf配置文件
[root@logstash-prod01 logstashconf]# cat ebs_asset_prod.conf
input {
kafka {
bootstrap_servers => "10.10.16.140:9092,10.10.16.141:9092,10.10.16.142:9092"
topics => ["ebs_asset_info_prod","ebs_asset_error_prod"]
codec => json {
charset => "UTF-8"
}
}
}
filter{
grok{
#match => {"message" => "%{TIMESTAMP_ISO8601:timestamp}%{SPACE}\s\[%{DATA:thread}\s*\]%{SPACE}%{LOGLEVEL:level}%{SPACE}%{NOTSPACE:logger}%{SPACE}-%{SPACE}\s\[%{NOTSPACE:method}\s*\]%{SPACE}-%{SPACE}%{GREEDYDATA:msg}"}
match => {"message" => "%{EBSTIME:timestamp}%{SPACE}\s\[%{DATA:thread}\s*\]%{SPACE}%{LOGLEVEL:level}%{SPACE}%{NOTSPACE:logger}%{SPACE}-%{SPACE}\s\[%{NOTSPACE:method}\s*\]%{SPACE}-%{SPACE}%{GREEDYDATA:msg}"}
}
mutate {
remove_field => [ "[agent][id]","[agent][ephemeral_id]","[agent][type]","[agent][version]","[ecs][version]","[log][offset]","[input][type]","[event][original]" ]
}
date{
match => ["timestamp","yyyy-MM-dd HH:mm:ss.SSS"]
target => "@timestamp"
#tag_on_failure => ["_dateparsefailure"]
}
}
output {
elasticsearch {
hosts =>["https://10.10.16.146:9200","https://10.10.16.147:9200","https://10.10.16.148:9200","https://10.10.16.149:9200","https://10.10.16.150:9200"]
index => "ebs_asset_prod-%{+YYYY.MM.dd}"
user => "elastic"
password => "aaaaa"
ssl => "true"
cacert => "/etc/logstash/certs/http_ca.crt"
}
}
上文中EBSTIME为个人定义,因为我没找到相关的时间格式。。。因此在/usr/share/logstash/vendor/bundle/jruby/3.1.0/gems/logstash-patterns-core-4.3.4/patterns/ecs-v1/grok-patterns目录下自己写了3个,太痛苦了当时!!!
HTTPDATE %{MONTHDAY}/%{MONTH}/%{YEAR}:%{TIME} %{INT}
EVENTTIME %{YEAR}/%{MONTHNUM}/%{MONTHDAY} %{TIME}
EBSTIME %{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{TIME}
[root@a-oa-elk-logstash-prod01 logstashconf]# cat nginx.conf
input {
kafka {
bootstrap_servers => "10.10.16.140:9092,10.10.16.141:9092,10.10.16.142:9092"
topics => ["test_nginx_accesslog"]
codec => json {
charset => "UTF-8"
}
}
}
filter{
grok{
match => {"message" => "%{COMBINEDAPACHELOG}" }
}
}
output {
elasticsearch {
hosts =>["https://10.10.16.146:9200","https://10.10.16.147:9200","https://10.10.16.148:9200","https://10.10.16.149:9200","https://10.10.16.150:9200"]
index => "test_nginx_accesslog-%{+YYYY.MM}"
user => "elastic"
password => "aaaaa"
ssl => "true"
cacert => "/etc/logstash/certs/http_ca.crt"
}
}
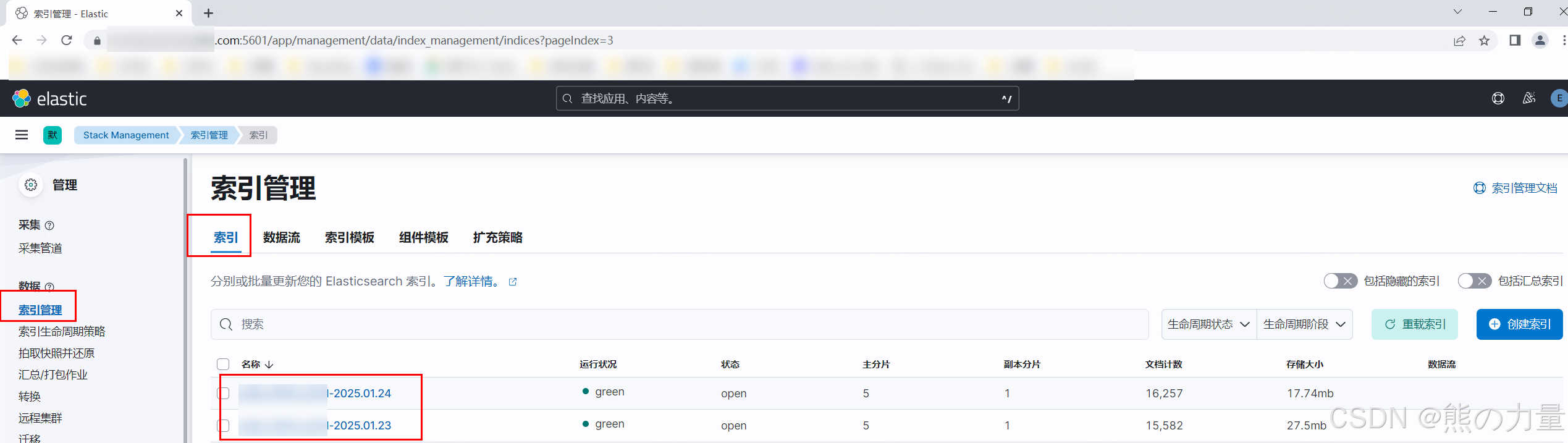
下图是使用索引模板创建的索引,方便后续管理,规划。
output {
#stdout { codec => rubydebug }
elasticsearch {
hosts =>["https://10.10.16.146:9200","https://10.10.16.147:9200","https://10.10.16.148:9200","https://10.10.16.149:9200","https://10.10.16.150:9200"]
template_name => "yzy_default_template" #使用的索引模板
index => "yzy_prod-%{+YYYY.MM.dd}" #索引格式,我这里用的是每天滚动
ilm_enabled => true
user => "elastic"
password => "aaaaa"
ssl => "true"
cacert => "/etc/logstash/certs/http_ca.crt"
}
}
将 ES 的证书复制到 Logstash 目录。因为我们的 ES 使用的 HTTPS 访问认证, Logstash 要发送日志到 ES 时,需要进行证书认证。
scp -r /etc/elasticsearch/certs root@10.10.16.143:/etc/logstash/写个统一启动的脚本,统一拉起来logstash
[root@logstash-prod01 data]# cat /data/logstashstart.sh
#!/bin/bash
nohup /usr/share/logstash/bin/logstash --path.data=/data/oa_email_ngx -f /data/logstashconf/oa_email_ngx.conf > /dev/null 2>&1 &
nohup /usr/share/logstash/bin/logstash --path.data=/data/ebs_ems_prod -f /data/logstashconf/ebs_ems_prod.conf > /dev/null 2>&1 &
##出现过业务太多了,结果机器内存顶不住的问题,调节这个配置
[root@logstash-prod01 data]# cat /etc/logstash/jvm.options
## JVM configuration
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms512m #调节内存
-Xmx512m #调节内存
至此,下图所有配置完成。。。。!!!!

打开kibana查看索引是否生成,创建相应的patterns就ok了
冷热数据分离、索引模板创建、生命周期管理、字段拆解下次再说,写不动了啊啊啊啊啊啊


















 2577
2577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









