







 本文介绍了一种名为HRNet的新方法,该方法通过在整个网络中维持高分辨率表示,显著提高了人体姿态估计的准确性。HRNet采用并行连接的高分辨率子网络,并通过反复的多尺度融合来增强表示能力。
本文介绍了一种名为HRNet的新方法,该方法通过在整个网络中维持高分辨率表示,显著提高了人体姿态估计的准确性。HRNet采用并行连接的高分辨率子网络,并通过反复的多尺度融合来增强表示能力。
Title
Deep High-Resolution Representation Learning for Human Pose Estimation
原文地址:https://arxiv.org/abs/1902.09212v1
github:https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
Summary
论文使用全程高分辨路的网络替代从高到低分辨率再生成高分辨率的网络,并使用多角度融合的算法理念大大提升了人体姿态估计的准确率。
Research Objective
利用高分辨率表现学习提升人体姿态估计准确率
Problem Statement
- 大多数现有方法通过输入传递输入网络,通常由串联连接的高分辨率到低分辨率子网络组成,然后提高分辨率
- 大多数现有的融合方案聚合了低级和高级表示。
Method(s)
论文中提出一种在整个过程中都保持高分辨率表示的网络——High-Resolution Net。
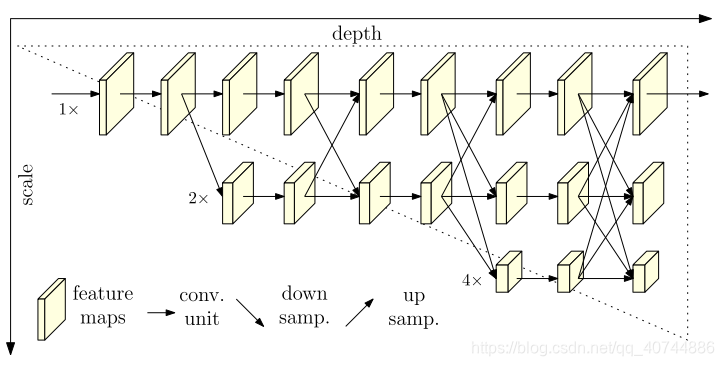
- 概述:
从高分辨率子网开始作为第一阶段,逐步添加高到低分辨率子网以形成更多阶段,并且并行连接多分辨率子网。我们通过在整个过程中反复交换并行多分辨率子网络中的信息来进行重复的多尺度融合。然后估计了网络输出的高分辨率表示的关键点。 - 优势
- 论文的方法采用并行连接高分辨率子网络,而不是像大多数现有解决方案那样串联连接。因此,这种方法能够保持高分辨率,而不是通过从低到高的过程恢复分辨率,因此预测的热图可能在空间上更精确。
- 大多数现有的融合方案聚合了低级和高级表示。相反,论文的方法是在相同深度1相似水平的低分辨率表示的帮助下执行重复的多尺度融合以提升高分辨率表示,反之亦然,从而导致高分辨率表示对于姿态估计也很丰富(rich)。
- Convolutional network
- We follow the widely-adopted pipeline [40, 72, 11] to
predict human keypoints using a convolutional network, which is composed of a stem consisting of two strided convolutions decreasing the resolution, a main body outputting the feature maps with the same resolution as its input feature maps, and a regressor estimating the heatmaps where the keypoint positions are chosen and transformed to the full resolution. - 翻译:它由两个降低分辨率的跨步卷积组成的杆、一个输出与其输入特征图分辨率相同的特征图的主体、以及一个用于估计选择关键点位置并转换为全分辨率的热图的回归器组成。
- Sequential multi-resolution subnetworks
- composed of a sequence of convolutions and there is a down-sample layer across adjacent subnetworks to halve the resolution
- 翻译:由一系列卷积组成,并且在相邻子网上有一个下采样层,以使分辨率减半
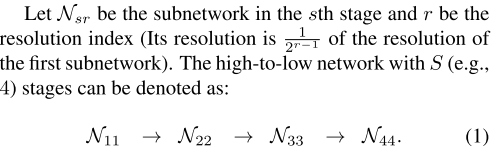
- Parallel multi-resolution subnetworks
- We start from a high-resolution subnetwork as the first stage, gradually add high-to-low resolution subnetworks one by one, forming new stages, and connect the multi-resolution subnetworks in parallel.
- 翻译:我们从高分辨率子网开始作为第一阶段,逐一逐步添加高到低分辨率子网,形成新阶段,并行连接多分辨率子网。
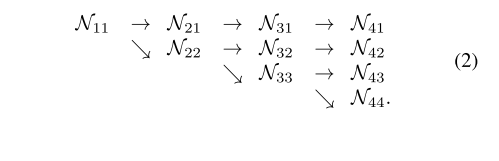
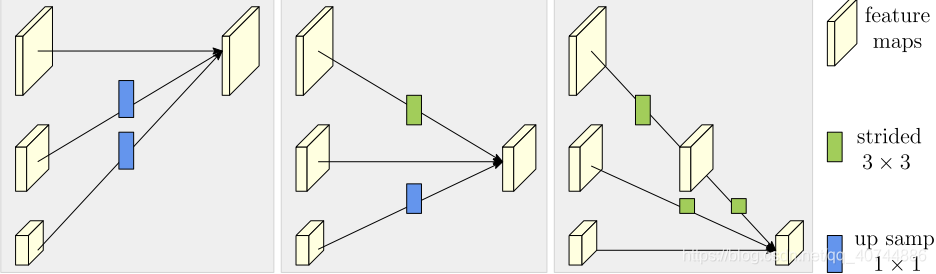
- Repeated multi-scale fusion
- We introduce exchange units across parallel subnetworks such that each subnetwork re- peatedly receives the information from other parallel sub- networks.
- 翻译:我们在并行子网中引入交换单元,使得每个子网重复地从其他并行子网接收信息。

- Heatmap estimation
- We regress the heatmaps simply from the high-resolution representations output by the last exchange unit, which empirically works well.
- 翻译:我们简单地从最后一个交换单元输出的高分辨率表示中回归热图,这很有效。
- Network instantiation
- We instantiate the network for keypoint heatmap estimation by following the design rule of ResNet to distribute the depth to each stage and the number of channels to each resolution.
- 翻译:我们通过遵循ResNet的设计规则来实例化关键点热图估计的网络,以将深度分布到每个阶段以及每个分辨率的信道数量。
- HRNet包含四个stage和四个平行子网,其分辨率逐渐降低到一半,因此宽度(通道数)增加到两倍。第一阶段包含每个单元的4个剩余单元。第2、3、4stage包含1、4、3个交换区。一个交换区包含四个剩余单元,每个单元包含两个3×3卷积分辨率和一个跨越分辨率的交换单元。总之,这里有8个交换单元,即进行8次多角度融合。
Evaluation
数据集:COCO ,MPII
- COCO Keypoint Detection Dataset.
- MPII Human Pose Estimation Dataset.
- Application to Pose Tracking Dataset.
Conclusion
1)maintain the high resolution through the whole process without the need of recovering the high resolution.
2)fuse multi-resolution representations repeat- edly, rendering reliable high-resolution representations.
这里不做翻译,原生的英文更能表达出论文的含义。

















 2493
2493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









