







 文章提出了一种新的层次化视觉前缀融合网络(HVPNET),用于多模态命名实体识别和关系抽取。通过将视觉表示作为可插入的前缀来指导文本表示,减少错误敏感性。HVPNET利用动态门控聚合策略融合分层多尺度视觉特征,提高了性能。实验结果证明了该方法的有效性和先进性。
文章提出了一种新的层次化视觉前缀融合网络(HVPNET),用于多模态命名实体识别和关系抽取。通过将视觉表示作为可插入的前缀来指导文本表示,减少错误敏感性。HVPNET利用动态门控聚合策略融合分层多尺度视觉特征,提高了性能。实验结果证明了该方法的有效性和先进性。
多模态命名实体识别与关系抽取(MNER和MRE)是信息抽取的一个重要分支。 然而,现有的MNER和MRE方法在文本中包含无关的目标图像时往往存在错误敏感性。 针对这些问题,我们提出了一种新的层次化视觉前缀融合网络(HVPNET),用于可视化增强的实体和关系提取,以获得更有效和鲁棒的性能。 具体地说,我们将可视化表示作为可插入的可视化前缀来指导文本表示,以实现对错误不敏感的预测决策。 我们进一步提出了一种动态门控聚合策略来实现分层的多尺度视觉特征作为融合的视觉前缀。 在三个基准数据集上进行的大量实验证明了该方法的有效性,并取得了最先进的性能。
考虑到Web文档中图像经常出现在文本之前,我们认为图像可以作为文本描述的前缀,这是受到语言模型中的即时学习的启发。 具体地说,给定一个图像-文本对,我们在Bert(Devlin et al.,2019)的每个自我注意层处,将长度为vi(视觉前缀)的对象级图像特征序列预置到文本序列上。 请注意,可视化前缀是一个可插入的操作,不需要任何相关性注释。 因此,可视化前缀不仅可以引入对象级的可视化信号,还可以进一步减少对表示文本的架构的影响。 从直观上看,视觉前缀作为文本的提示,有助于减轻对无关对象图像的错误敏感性。
卷积神经网络(CNN)包含从低到高的多尺度信息和金字塔特征层次结构。而BERT从底部到顶部编码了丰富的语言信息层次结构。受Lin等人和Liu等人的启发,不同大小的对象可以在相应的尺度上具有适当的特征表示。因此,作者提出让BERT的每一层都能感知分层多尺度视觉特征,以做出更明智、更全面的预测决策。
为此,我们提出了一种新的分层视觉前缀融合网络(HVPNET),用于视觉增强的实体和关系提取。 具体来说,受SIMVLM(Wang et al.,2021)启发,我们提出了视觉前缀引导融合机制,将串联对象级视觉表示作为Bert中每个自关注层的前缀,这是一个更软、更鲁棒的视觉增强NER和RE注意力模块。 我们进一步为每一层设计了一个动态门来生成与图像相关的路径,从而将各种聚集的分层多尺度视觉特征作为增强NER和RE的视觉前缀。 总的来说,我们将论文的主要贡献归纳如下:
- 针对MNER和MRE提出了一个层次化的视觉前缀融合网络,通过基于视觉前缀的注意机制在BERT的每个自注意层引入层次化的多尺度视觉特征,生成有效的、鲁棒的文本表示,以降低错误敏感性。
- 我们利用动态门的开发来充分利用层次化的视觉特征。 从而使Transformer中每一层的文本表示能够自适应地感知相应的层次视觉特征。 据我们所知,本文是第一个利用层次金字塔视觉特征进行多模态学习的工作。
- 我们在MNER和MRE任务上评估我们的方法。 在三个基准数据集上的实验结果验证了HVPNET的有效性和优越性
3 Methodology
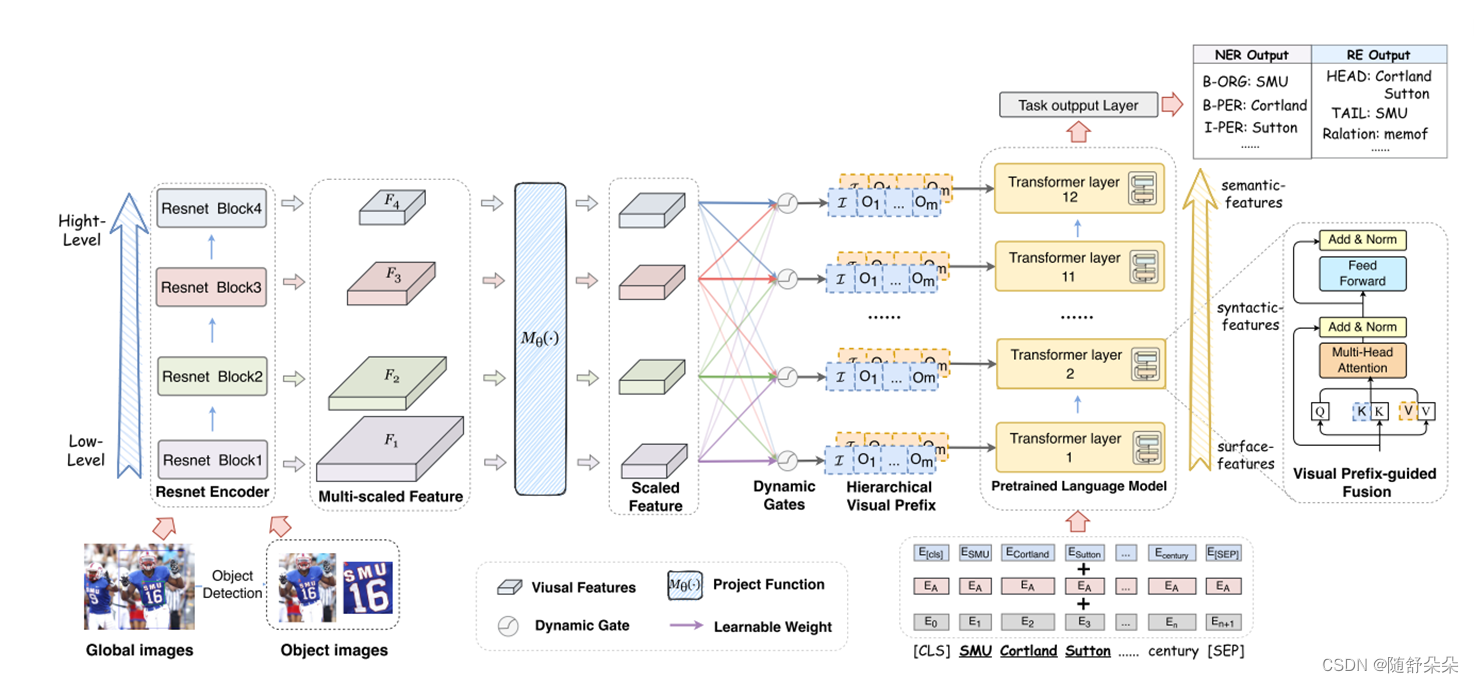
如图2所示,我们提出了一种用于多模态实体和关系提取的分层前缀融合网络。 注意,我们的方法也可以应用于其他针对文本的视觉增强任务。
3.1金字塔视觉特征的收集
一方面,与句子相关联的图像保持了与句子中实体相关的多个视觉对象,进一步提供了更多的语义知识来辅助信息提取。 另一方面,全局图像特征可能表达抽象概念,起到弱学习信号的作用。 因此,以区域图像为重要信息,以全局图像为补充,收集多个视觉线索进行多模态实体和关系提取。 给定一幅图像,我们遵循(Zhang et al.,2021a)采用视觉接地工具包(Yang et al.,2019)来提取具有顶部M显著性的局部视觉对象。 然后,我们将全局图像和对象图像重新缩放到224×224像素,作为全局图像I和可视对象O={O1,O2,...,OM,}。
在CV领域,利用预训练模型不同块特征的特征融合方法(Wang et al.,2019;Kim et al.,2018;Lin et al.,2017)被广泛应用于提高模型性能。 受这些实践的启发,我们迈出了第一步,重点研究金字塔特征在多模态领域的应用。 我们提出将分层图像特征融合到每个变压器层中; 因此,利用功能金字塔是必不可少的。 通常,给定一幅图像,我们用主干模型对其进行编码,并生成一系列不同比例尺的金字塔特征映射{f1,f2,f3,...,fc},然后用mθ(·)映射它们,如下所示:
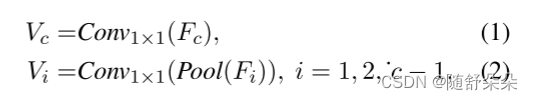
其中i表示主干模型的第i个块,c表示可视主干模型中的块数(这里是4表示ResNet),pool表示池操作,其中特征被聚合到相同的空间大小。 利用1×1卷积层映射金字塔视觉特征,以匹配变压器的嵌入尺寸。
3.2动态门控聚合
尽管不同大小的对象可以在相应的尺度上有适当的特征表示,但要确定为Transformer中的每一层指定视觉主干中的哪个块的视觉前缀并不是一件容易的事情。 为了解决这一难题,我们提出了构造密集连接路由空间,在该空间中,分层的多尺度视觉特征与每个变压器层相连。
3.2.1动态门模块
我们通过一个动态门模块进行常规处理,它可以看作是一个路径决策过程。 动态门的动机是预测一个归一化向量,该向量表示执行每个块的视觉特征的多少。 在动态门中,g(L)i∈[0,1]表示从视觉主干第i块到变压器第l层的路径概率。 其计算式为G(L)=G(L)(V)∈RC,其中G(L)(·)表示按变压器第L层的选通函数,C表示主干中的块数。 我们首先产生门信号的logitsα(L)I:
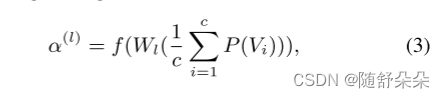
其中F(·)表示激活函数Leaky_RELU,P表示全局平均池层。 我们首先通过平均池操作从第i块中挤压形状为(di,hi,w)的输入特征vi。 然后将多个块中的特征加入,生成平均向量。 我们进一步利用MLP层WL对特征维数进行C降维,并通过生成连续值作为路径概率来考虑软门。 然后,我们生成变压器第L层的概率向量G(L),如下所示:
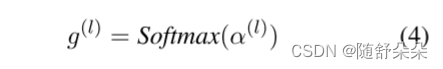
3.2.2聚合层次特征
基于上述动态门G(L),我们可以导出最终的聚合层次视觉特征Vgated以匹配Transformer中的第L层,如下:
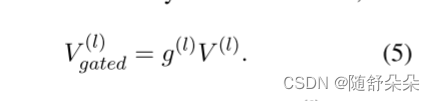
形式上,通过下面的级联操作获得对应于第L层变压器的最终视觉特征V~(L),
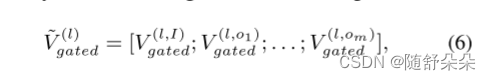
通过基于视觉前缀的注意来增强文本情态的层次表征。
3.3视觉前缀引导融合
我们将分层多尺度图像特征作为可视化前缀,并将可视化前缀序列预置于Bert(Devlin et al.,2019)的每个自关注层的文本序列中,特别是在给定输入序列x={x1,x2,...,xn}的情况下,首先将上下文表示HL-1∈rn×d投影到查询/键/值向量中:
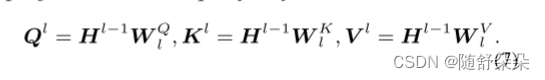
对于聚集的层次视觉特征V~(L)门控,我们对第L层使用一组线性变换WφL∈RD×2×D,将它们投射到自关注模块中文本表示的同一嵌入空间2中。 此外,我们定义了可视化提示函数φL k,φL v∈RHW(M+1)×D的运算为:
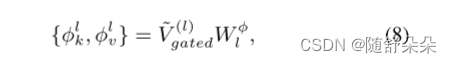
其中HW(m+1)表示视觉序列的长度,m表示由对象检测算法检测到的视觉对象的数量。 形式上,基于视觉前缀的注意力计算如下:
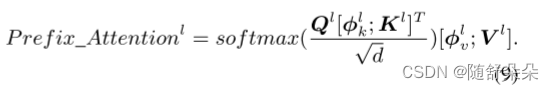
备注1 在每一融合层,我们以层次化的多尺度视觉特征作为视觉前缀,依次进行多模态注意,更新所有文本状态。 这样,最终的文本状态同时编码上下文和跨界语义信息。 有利于降低对无关对象元素的误差敏感性。
5结论和未来工作
本文提出了一种新的层次化可视化前缀融合网络(HVPNET),用于可视化增强的实体和关系提取。 具体地说,我们提出了视觉前缀引导的融合,将对象级视觉表示串联为BERT中每个自注意层的前缀,这是一个更软和鲁棒的视觉增强NER和RE的注意模块。 我们进一步设计了利用分层多尺度视觉表示作为融合的视觉指导。 从直观上看,良好的视觉引导使提取器更好,在三个基准上的大量实验和结果表明了我们提出的方法的有效性和鲁棒性。 同时,我们的方法也面临着不适合视觉侧多模态任务的局限性,如视觉接地。
未来,我们计划1)探索层次化视觉前缀在多模态表征学习中的更多应用,使其更具灵活性和可扩展性; 2)尝试应用我们的方法的反向版本,以文本增强简历的视觉表示; 3)将我们的方法扩展到多任务多模态预训练。
自问自答
ps:
1.多尺度特征:多尺度特征是指在图像处理中,使用不同的尺度来提取图像的特征。
2.多尺度特征中的尺度是什么?:在多尺度特征中,尺度指的是图像处理中使用的不同分辨率。在多尺度特征提取中,图像会被缩放到不同的分辨率,以便在不同的尺度下提取图像的特征。这种方法可以捕捉到图像中不同尺度下的信息,从而更好地描述图像的内容。
3.不同尺度提取的特征为什么不一样?:在不同的尺度下提取的特征不同,是因为图像在不同的分辨率下包含的信息不同。在较低的分辨率下,图像中的细节信息会丢失,而在较高的分辨率下,图像中的细节信息会更加清晰。因此,在不同的尺度下提取的特征会捕捉到图像中不同层次的信息。例如,在较低的尺度下,特征提取算法可能会捕捉到图像中的全局结构信息,而在较高的尺度下,特征提取算法可能会捕捉到图像中的局部细节信息。这就是为什么在多尺度特征提取中,不同尺度下提取的特征不同。
4.金字塔形视觉特征是什么?:金字塔形视觉特征是指在图像处理中,使用不同的尺度来提取图像的特征。这种方法可以捕捉到图像中不同尺度下的信息,从而更好地描述图像的内容。
5.为什么叫做金字塔形视觉特征?:金字塔形视觉特征之所以被称为金字塔形,是因为它们是通过在不同的尺度下提取图像特征来构建的。这些尺度通常是按照从粗到细的顺序排列的,就像一个金字塔一样。在较低的尺度下,图像中的细节信息会丢失,而在较高的尺度下,图像中的细节信息会更加清晰。因此,在不同的尺度下提取的特征会捕捉到图像中不同层次的信息。这就是为什么这种特征被称为金字塔形视觉特征。
6.视觉接地是什么?:视觉接地(Visual Grounding)是指根据自然语言查询,在图像中定位最相关的物体或区域。查询可以是一个短语、一个句子,甚至是一个多轮对话。视觉接地面临的三个主要挑战是:查询中的主要焦点是什么?如何理解图像?如何定位物体?7.Mθ(·)是什么?:Mθ(·)是一个映射函数,它用于将金字塔视觉特征映射到与Transformer嵌入大小匹配。在上面引用的文本中,它被用来将不同尺度的金字塔特征图{F1, F2, F3, . . . , Fc}映射为Vc =Conv1×1(Fc)和Vi =Conv1×1(Pool(Fi)),其中i = 1, 2,˙c − 1。
8.动态门控模块的作用是什么?:动态门控模块用于预测一个归一化向量,表示每个块的视觉特征执行的程度。动态门控的动机是为每个变压器层生成概率向量,表示每个块的视觉特征执行的程度。这允许生成图像相关路径,以便将各种聚合的分层多尺度视觉特征视为视觉前缀,以增强NER和RE。
9.预测一个归一化向量是什么意思?:预测一个归一化向量是指使用模型来预测一个向量,该向量的所有元素之和为1。这样的向量通常用于表示概率分布,其中每个元素表示某个事件发生的概率。在动态门控模块中,归一化向量用于表示每个块的视觉特征执行的程度。这意味着,归一化向量中的每个元素都表示对应块的视觉特征对最终结果的贡献程度。
10.视觉接地和目标检测一样吗?:视觉接地(Visual grounding)是指将自然语言描述与图像中的特定区域相关联的过程。它通常用于解决自然语言引用问题,即确定自然语言描述所指的图像区域。视觉接地与目标检测不同,目标检测是识别和定位图像中特定目标的过程,而视觉接地则是将自然语言描述与图像中的特定区域相关联。

















 1364
1364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









