






ITA:通过图像文本对齐实现的多模态命名实体识别
2022NAACL
代码:https://github.com/Alibaba-NLP/KB-NER/tree/main/ITA
1.核心思想
- 在多模态命名实体识别任务中,文本依然发挥关键作用,因此本文将图像特征对齐到文本表示空间,以使得基于transformer的文本预训练向量得以被更好地使用。
- 图像模态仅在消除歧义中扮演重要角色。
- 多模态命名实体识别模型( MNER model)应当在仅有文本的情况下有一定的健壮性(因为实际场景中不是所有的都带有图像信息)。
2. 整体框架
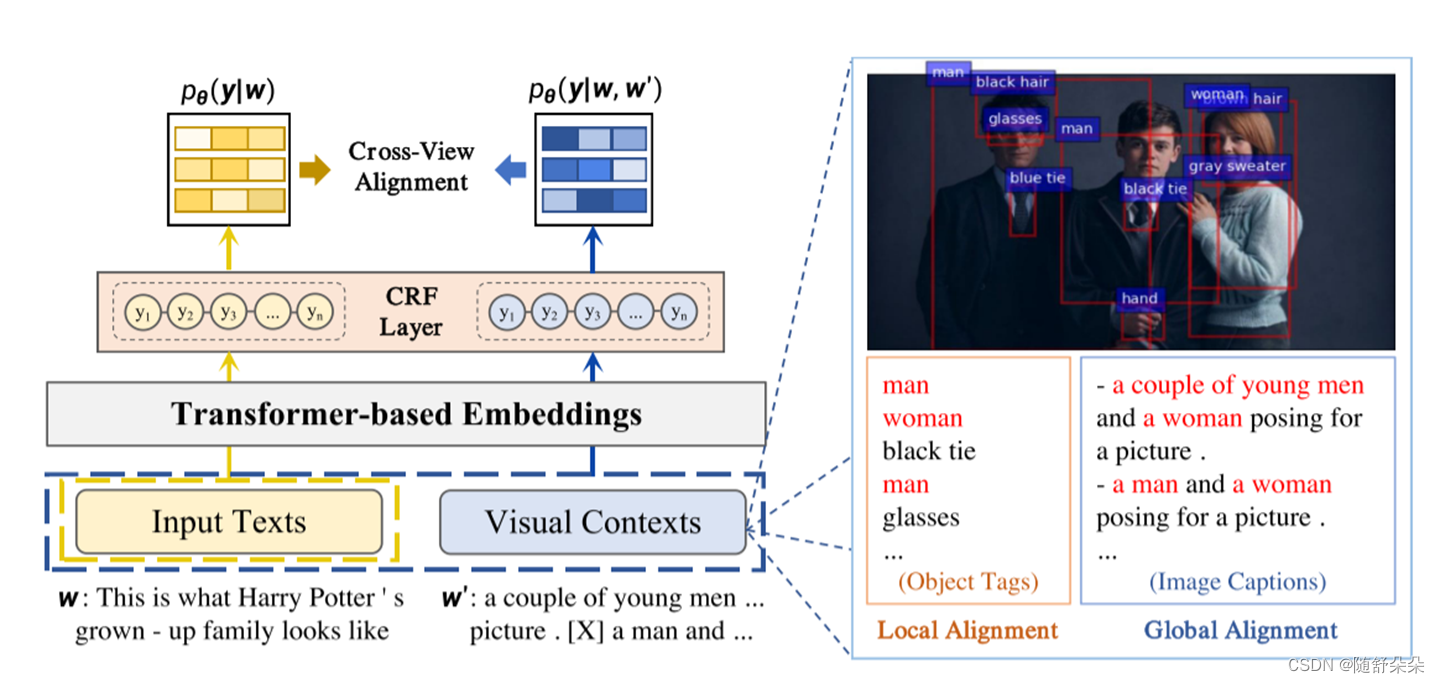
图1:ITA的体系结构
ITA将图像对齐为对象标签 (局部对齐) 和图像标题 (全局对齐)。ITA将它们作为视觉上下文,然后将它们与输入文本一起馈送到基于transformer的嵌入中。在交叉视图对齐模块中,ITA最小化了交叉模态输入的输出分布与文本输入之间的距离。视觉环境中的红色单词是我们认为有助于预测的内容。
如上图:Visual Contexts表示从图像端获得的“视觉上下文”(也是文本表示),再将其和Input Texts拼接起来,经过一个Transformer-based Embeddings(如BERT等),再经过一个CRF层(序列标注任务常用),最后的Cross-View Alignment部分用来对齐(通过计算两个view的KL距离,详细看原文)。
ITA可以概括为三个方面:
- 作为局部对齐的对象标记:ITA从对象检测器中局部提取对象标记及其对应的图像区域属性。
- 作为全局对齐的图像标题:ITA通过从图像标题模型预测图像标题来总结图像所描述的内容。
- 交叉视图对齐:我们计算两个输入视图的输出分布之间的KL散度。
这样一来,解决了如下几个问题:
- 1.有的MNER场景缺少图片
- 2.图片中的噪音会误导预测结果
- 3.许多在线场景对推理时间要求高,而直接用pipeline的方法将文本和图像对齐很耗时。
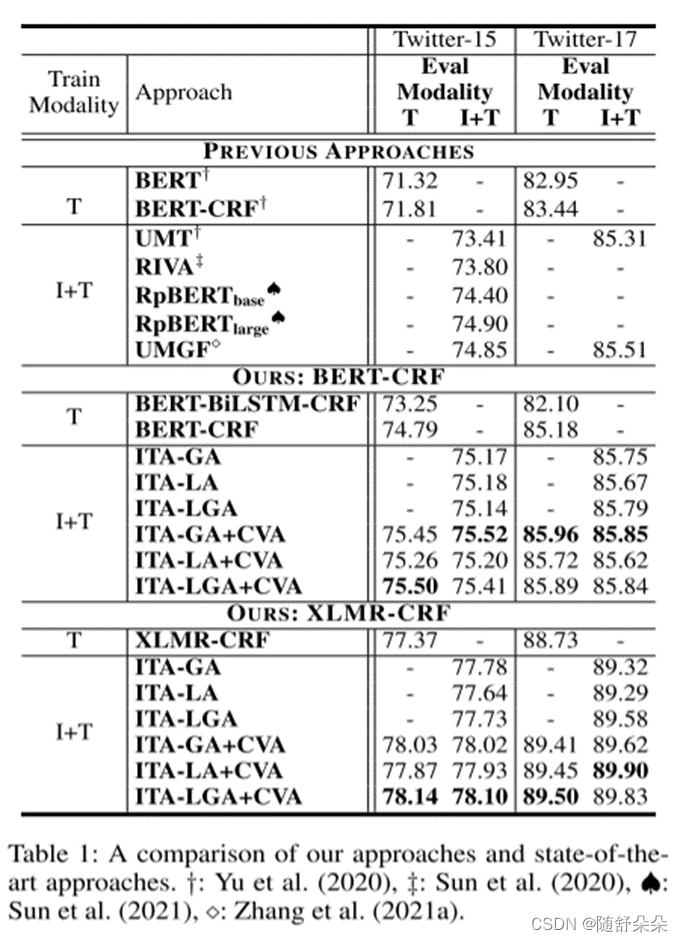
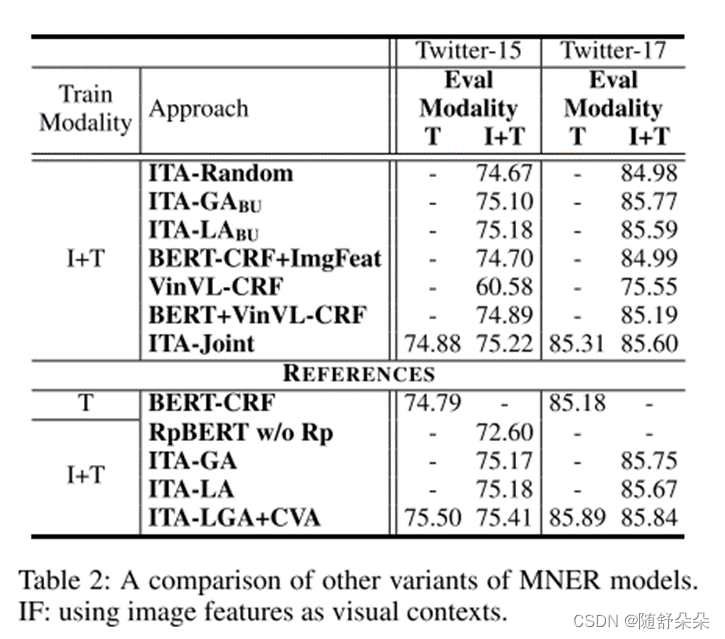
3.实验结果
4.总结
- ITA将图像转换为对象标签、标题和OCR文本,以将图像表示与文本空间对齐。
- CVA使MNER模型更好地利用输入中的文本信息。
- 我们发现,ITA显着优于先前的最先进的方法对MNER数据集。
- 我们进一步分析了ITA如何简化跨模态对齐,以及图像如何影响NER预测。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









