







 LUCIR是CVPR2019提出的一种增量学习方法,旨在处理新旧任务间的不平衡、偏差和模糊问题。通过余弦归一化、减少遗忘约束和类别间分离损失,改善模型在增量学习中的性能。实验表明,这些策略能有效提升模型对旧任务的保留能力和新旧任务的区分度。
LUCIR是CVPR2019提出的一种增量学习方法,旨在处理新旧任务间的不平衡、偏差和模糊问题。通过余弦归一化、减少遗忘约束和类别间分离损失,改善模型在增量学习中的性能。实验表明,这些策略能有效提升模型对旧任务的保留能力和新旧任务的区分度。
Learning a Unified Classifier Incrementally via Rebalancing (LUCIR)
Overview
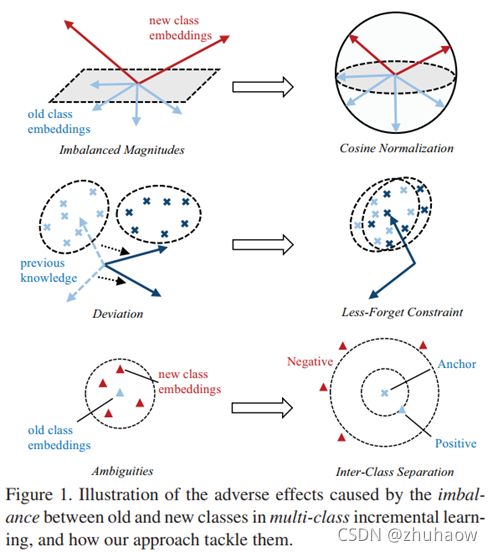
本文定义了增量学习任务中存在的三个问题:
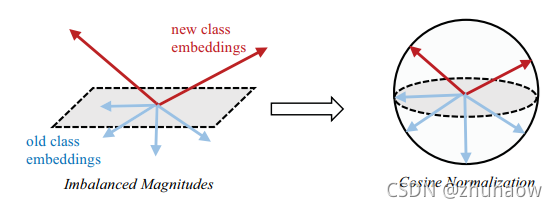
- Imbalanced Magnitudes;
- Deviation;
- Ambiguities;
并提出了对应的解决方法:
- Cosine Normalization;
- Less-Forget Constraint;
- Inter-Class Separation。
Notions:
分类器权重 = class embedding = classifier weights = ϴ
Introduction
由于增量学习过程中只能看见少量的旧样本,这会导致分类器对于新样本产生较大的偏好。会造成以下三个问题:
- Imbalanced magnitudes: 新类别的Linear classifier weights 幅值会高于旧类别;
- Deviation: 原有旧类别的知识没有能够很好地得到保留,例如,旧类别样本feature与分类器weights vector之间的;
- Ambiguities:新类别的weight vectors和旧类别的weight vectors会很接近,没有区分度造成新旧任务间的混淆,主要是旧类别误分为新类别。
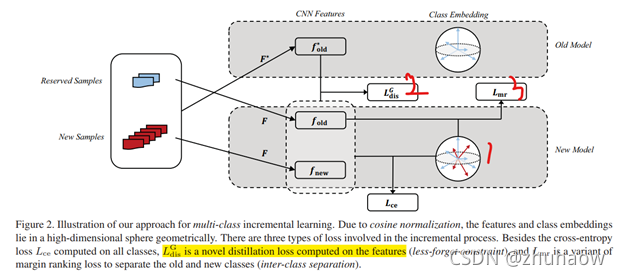
Our Approach
总的来说,该方法提出三个损失函数去约束Distillation-based的方法中存在的因新旧样本不均衡而导致的偏见问题。
A. Cosine Normalization (CN)
Cosine Normalization的做法如下:
- 模型分类器的权重weights进行二范数归一化
- 输入分类器的feature进行二范数归一化。
这样原有的公式3中的分类器weights和特征f(x)相乘的操作,就会变成公式4所示,由于此时weights和feature都是归一化后的,两者之间相乘其实是在计算余弦相似度,那最后的分类结果就是在计算各个类别的相似度。
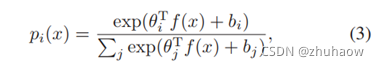
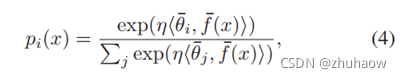
B. Less-Forget Constraint (LC)
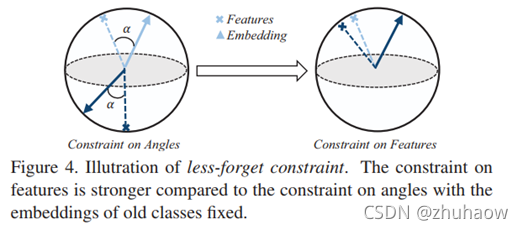
调整完新旧任务分类器的权重后,要开始考虑如何维持旧任务的知识,即通过公式2所示的蒸馏损失。如公式2所示,原有的iCarL (baseline)中的蒸馏loss是针对模型输出进行蒸馏的,但是呢,由于cosine normalization后,模型输出的是余弦相似性,就可能会发生图4中的情况。即如果class embedding和features整体发生偏移,可能会出现class embedding和features之间的余弦距离没有发生变化,但整体已经发生明显偏移的情况。因此,提出了约束旧样本在新旧模型中输出特征之间余弦距离的方式,让新旧模型输出的特征尽可能相近,如公式6所示。


![]()
此外,作者还提出adaptive loss weight的思想,认为随着增量学习任务的进行,蒸馏的loss weight也应该随之变大。
笔者认为,此处的adaptive loss weight只是和增量任务的增加有了一个相对soft的正相关关系,并没有考虑增量任务增加导致的模型对旧任务的维持能力下降的本质。

C. Inter-Class Separation (IS)
为了避免新旧任务之间的混淆现象,应该尽可能加大两个任务之间的区分度。作者此处用了一个rank margin loss,去使得旧任务样本的GT类别输出尽可能大于新任务类别的输出,避免旧样本错分为新样本。

整体损失函数如下:
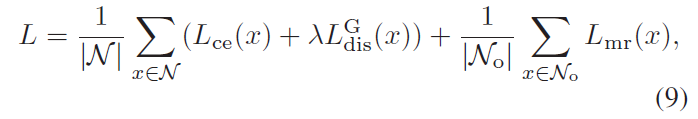
Experiment
作者提出了iCaRL-CNN和iCaRL-NME两种baseline,这里iCaRL-CNN和NME的区别是什么我没有太明白,我猜测iCaRL-CNN是类似LwF的一种训练方法,即随机挑选样本。
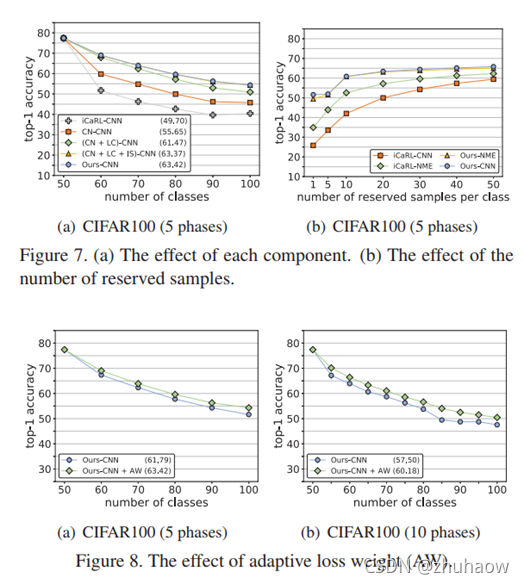
此外,作者发现在整体训练完后,在一个balanced数据集上微调下有助于提高模型结果,但是在LUCIR上提高很微弱,见图8
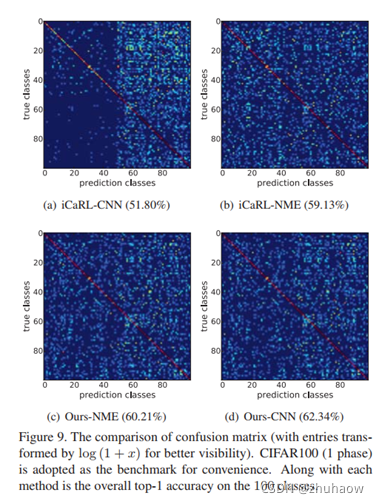
图7中可发现,NME可以提高模型对旧任务的表现,而Ours-CNN也具备同样的能力,且精度元高于iCaRL-NME,此外Ours-NME精度反而低于了Ours-CNN.
通过如图7所示的消融实验,验证了各个损失函数及adaptive loss weight的有效性。
值得一提的是,没有什么和sota方法对比的表格?

















 1224
1224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









