







 本文详细介绍了在CIFAR10数据集上使用ResNet模型的实现过程,包括模型架构、代码实现及优化技巧,最终在测试集上达到了91%的准确率。
本文详细介绍了在CIFAR10数据集上使用ResNet模型的实现过程,包括模型架构、代码实现及优化技巧,最终在测试集上达到了91%的准确率。
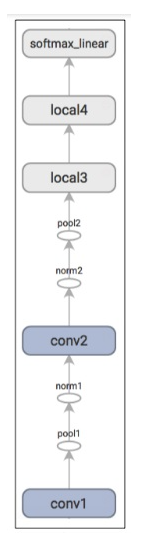
在上一篇博文中我重写了Tensorflow中的CNN的实现,对于CIFAR10的测试集的准确率为85%左右。在这个实现中,用到了2个卷积层和2个全连接层。具体的模型架构如下:
为了进一步提高准确率,我们可以采用一些更先进的模型架构,其中一种很出名的架构就是RESNET,残差网络。这是Kaiming大神在2015年的论文"Deep Residual Learning for Image Recognition"中提到的一种网络架构,其思想是观察到一般的神经网络结构随着层数的加深,训练的误差反而会增大,因此引入了残差这个概念,把上一层的输出直接和下一层的输出相加,如下图所示。这样理论上随着网络层数的加深,引入这个结构并不会使得误差比浅层的网络更大,因为随着参数的优化,如果浅层网络已经逼近了最优值,那么之后的网络层相当于一个恒等式,即每一层的输入和输出相等,因此更深的层数不会额外增加训练误差。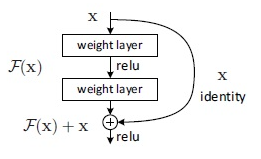
在2016年,Kaiming大神发布了另一篇论文“Identity Mappings in Deep Residual Networks”,在这个论文中对Resnet的网络结构作了进一步的改进。改进前和改进后的resnet网络结构如下图所示,按照论文的解释,改进后的结构可以在前向和后向更好的传递残差,因此能取得更好的优化效果: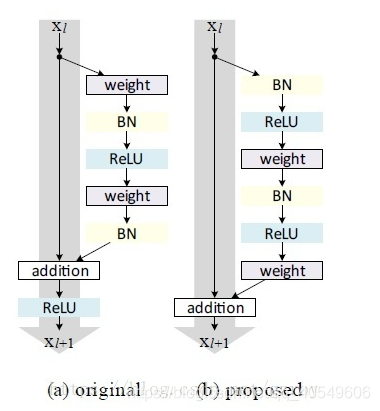
在Tensorflow的官方模型中,已经带了一个Resnet的实现,用这个模型训练,在110层的深度下,可以达到CIFAR10测试集92%左右的准确率。但是,这个代码实在是写的比较难读,做了很多辅助功能的封装,每次看代码都是要跳来跳去的看,实在是很不方便。为此我也再次改写了这个代码,按照Kaiming论文介绍的方式来进行模型的构建,在110层的网络层数下,可以达到91%左右的准确率,和官方模型的很接近。
具体的代码分为两部分,我把构建Resnet模型的代码单独封装在一个文件中。如以下的代码,这个代码里面的_resnet_block_v1和_resnet_block_v2分别对应了上图的两种不同的resnet结构:
import tensorflow as tf
def _resnet_block_v1(inputs, filters, stride, projection, stage, blockname, TRAINING):
# defining name basis
conv_name_base = 'res' + str(stage) + blockname + '_branch'
bn_name_base = 'bn' + str(stage) + blockname + '_branch'
with tf.name_scope("conv_block_stage" + str(stage)):
if projection:
shortcut = tf.layers.conv2d(inputs, filters, (1,1),
strides=(stride, stride),
name=conv_name_base + '1',
kernel_initializer=tf.contrib.layers.variance_scaling_initializer(),
reuse=tf.AUTO_REUSE, padding='same',
data_format='channels_first')
shortcut = tf.layers.batch_normalization(shortcut, axis=1, name=bn_name_base + '1',
training=TRAINING, reuse=tf.AUTO_REUSE)
else:
shortcut = inputs
outputs = tf.layers.conv2d(inputs, filters,
kernel_size=(3, 3),
strides=(stride, stride),
kernel_initializer=tf.contrib.layers.variance_scaling_initializer(),
name=conv_name_base+'2a', reuse=tf.AUTO_REUSE, padding='same',
data_format='channels_first')
outputs = tf.layers.batch_normalization(outputs, axis=1, name=bn_name_base+'2a',
training=TRAINING, reuse=tf.AUTO_REUSE)
outputs = tf.nn.relu(outputs)
outputs = tf.layers.conv2d(outputs, filters,
kernel_size=(3, 3),
strides=(1, 1),
kernel_initializer=tf.contrib.layers.variance_scaling_initializer(),
name=conv_name_base+'2b', reuse=tf.AUTO_REUSE, padding='same',
data_format='channels_first')
outputs = tf.layers.batch_normalization(outputs, axis=1, name=bn_name_base+'2b',
training=TRAINING, reuse=tf.AUTO_REUSE)
outputs = tf.add(shortcut, outputs)
outputs = tf.nn.relu(outputs)
return outputs
def _resnet_block_v2(inputs, filters, stride, projection, stage, blockname, TRAINING):
# defining name basis
conv_name_base = 'res' + str(stage) + blockname + '_branch'
bn_name_base = 'bn' + str(stage) + blockname + '_branch'
with tf.name_scope("conv_block_stage" + str(stage)):
shortcut = inputs
outputs = tf.layers.batch_normalization(inputs, axis=1, name=bn_name_base+'2a',
training=TRAINING, reuse=tf.AUTO_REUSE)
outputs = tf.nn.relu(outputs)
if projection:
shortcut = tf.layers.conv2d(outputs, filters, (1,1),
strides=(stride, stride),
name=conv_name_base + '1',
kernel_initializer=tf.contrib.layers.variance_scaling_initializer(),
reuse=tf.AUTO_REUSE, padding='same',
data_format='channels_first')
shortcut = tf.layers.batch_normalization(shortcut, axis=1, name=bn_name_base + '1',
training=TRAINING, reuse=tf.AUTO_REUSE)
outputs = tf.layers.conv2d(outputs, filters,
kernel_size=(3, 3),
strides=(stride, stride),
kernel_initializer=tf.contrib.layers.variance_scaling_initializer(),
name=conv_name_base+'2a', reuse=tf.AUTO_REUSE, padding='same',
data_format='channels_first')
outputs = tf.layers.batch_normalization(outputs, axis=1, name=bn_name_base+'2b',
training=TRAINING, reuse=tf.AUTO_REUSE)
outputs = tf.nn.relu(outputs)
outputs = tf.layers.conv2d(outputs, filters,
kernel_size=(3, 3),
strides=(1, 1),
kernel_initializer=tf.contrib.layers.variance_scaling_initializer(),
name=conv_name_base+'2b', reuse=tf.AUTO_REUSE, padding='same',
data_format='channels_first')
outputs = tf.add(shortcut, outputs)
return outputs
def inference(images, training, filters, n, ver):
"""Construct the resnet model
Args:
images: [batch*channel*height*width]
training: boolean
filters: integer, the filters of the first resnet stage, the next stage will have filters*2
n: integer, how many resnet blocks in each stage, the total layers number is 6n+2
ver: integer, can be 1 or 2, for resnet v1 or v2
Returns:
Tensor, model inference output
"""
#Layer1 is a 3*3 conv layer, input channels are 3, output channels are 16
inputs = tf.layers.conv2d(images, filters=16, kernel_size=(3, 3), strides=(1, 1),
name='conv1', reuse=tf.AUTO_REUSE, padding='same', data_format='channels_first')
#no need to batch normal and activate for version 2 resnet.
if ver==1:
inputs = tf.layers.batch_normalization(inputs, axis=1, name='bn_conv1',
training=training, reuse=tf.AUTO_REUSE)
inputs = tf.nn.relu(inputs)
for stage in range(3):
stage_filter = filters*(2**stage)
for i in range(n):
stride = 1
projection = False
if i==0 and stage>0:
stride = 2
projection = True
if ver==1:
inputs = _resnet_block_v1(inputs, stage_filter, stride, projection,
stage, blockname=str(i), TRAINING=training)
else:
inputs = _resnet_block_v2(inputs, stage_filter, stride, projection,
stage, blockname=str(i), TRAINING=training)
#only need for version 2 resnet.
if ver==2:
inputs = tf.layers.batch_normalization(inputs, axis=1, name='pre_activation_final_norm',
training=training, reuse=tf.AUTO_REUSE)
inputs = tf.nn.relu(inputs)
axes = [2, 3]
inputs = tf.reduce_mean(inputs, axes, keep_dims=True)
inputs = tf.identity(inputs, 'final_reduce_mean')
inputs = tf.reshape(inputs, [-1, filters*(2**2)])
inputs = tf.layers.dense(inputs=inputs, units=10, name='dense1', reuse=tf.AUTO_REUSE)
return inputs
另外一部分的代码就是和Cifar10的处理相关的,其中Cifar10的50000张图片中选取45000张作为训练集,另外5000张作为验证集,测试的10000张图片都作为测试集。在98层的网络深度下,测试集的准确度可以达到92%左右.
import tensorflow as tf
import numpy as np
import os
import resnet_model
#Construct the filenames that include the train cifar10 images
folderPath = 'cifar-10-batches-bin/'
filenames = [os.path.join(folderPath, 'data_batch_%d.bin' % i) for i in xrange(1,6)]
#Define the parameters of the cifar10 image
imageWidth = 32
imageHeight = 32
imageDepth = 3
label_bytes = 1
#Define the train and test batch size
batch_size = 100
test_batch_size = 100
valid_batch_size = 100
#Calulate the per image bytes and record bytes
image_bytes = imageWidth * imageHeight * imageDepth
record_bytes = label_bytes + image_bytes
#Construct the dataset to read the train images
dataset = tf.data.FixedLengthRecordDataset(filenames, record_bytes)
dataset = dataset.shuffle(50000)
#Get the first 45000 records as train dataset records
train_dataset = dataset.take(45000)
train_dataset = train_dataset.batch(batch_size)
train_dataset = train_dataset.repeat(300)
iterator = train_dataset.make_initializable_iterator()
#Get the remain 5000 records as valid dataset records
valid_dataset = dataset.skip(45000)
valid_dataset = valid_dataset.batch(valid_batch_size)
validiterator = valid_dataset.make_initializable_iterator()
#Construct the dataset to read the test images
testfilename = os.path.join(folderPath, 'test_batch.bin')
testdataset = tf.data.FixedLengthRecordDataset(testfilename, record_bytes)
testdataset = testdataset.batch(test_batch_size)
testiterator = testdataset.make_initializable_iterator()
#Decode the train records from the iterator
record = iterator.get_next()
record_decoded_bytes = tf.decode_raw(record, tf.uint8)
#Get the labels from the records
record_labels = tf.slice(record_decoded_bytes, [0, 0], [batch_size, 1])
record_labels = tf.cast(record_labels, tf.int32)
#Get the images from the records
record_images = tf.slice(record_decoded_bytes, [0, 1], [batch_size, image_bytes])
record_images = tf.reshape(record_images, [batch_size, imageDepth, imageHeight, imageWidth])
record_images = tf.transpose(record_images, [0, 2, 3, 1])
record_images = tf.cast(record_images, tf.float32)
#Decode the records from the valid iterator
validrecord = validiterator.get_next()
validrecord_decoded_bytes = tf.decode_raw(validrecord, tf.uint8)
#Get the labels from the records
validrecord_labels = tf.slice(validrecord_decoded_bytes, [0, 0], [valid_batch_size, 1])
validrecord_labels = tf.cast(validrecord_labels, tf.int32)
validrecord_labels = tf.reshape(validrecord_labels, [-1])
#Get the images from the records
validrecord_images = tf.slice(validrecord_decoded_bytes, [0, 1], [valid_batch_size, image_bytes])
validrecord_images = tf.cast(validrecord_images, tf.float32)
validrecord_images = tf.reshape(validrecord_images,
[valid_batch_size, imageDepth, imageHeight, imageWidth])
validrecord_images = tf.transpose(validrecord_images, [0, 2, 3, 1])
#Decode the test records from the iterator
testrecord = testiterator.get_next()
testrecord_decoded_bytes = tf.decode_raw(testrecord, tf.uint8)
#Get the labels from the records
testrecord_labels = tf.slice(testrecord_decoded_bytes, [0, 0], [test_batch_size, 1])
testrecord_labels = tf.cast(testrecord_labels, tf.int32)
testrecord_labels = tf.reshape(testrecord_labels, [-1])
#Get the images from the records
testrecord_images = tf.slice(testrecord_decoded_bytes, [0, 1], [test_batch_size, image_bytes])
testrecord_images = tf.cast(testrecord_images, tf.float32)
testrecord_images = tf.reshape(testrecord_images,
[test_batch_size, imageDepth, imageHeight, imageWidth])
testrecord_images = tf.transpose(testrecord_images, [0, 2, 3, 1])
#Random crop the images after pad each side with 4 pixels
distorted_images = tf.image.resize_image_with_crop_or_pad(record_images,
imageHeight+8, imageWidth+8)
distorted_images = tf.random_crop(distorted_images, size = [batch_size, imageHeight, imageHeight, 3])
#Unstack the images as the follow up operation are on single train image
distorted_images = tf.unstack(distorted_images)
for i in xrange(len(distorted_images)):
distorted_images[i] = tf.image.random_flip_left_right(distorted_images[i])
distorted_images[i] = tf.image.random_brightness(distorted_images[i], max_delta=63)
distorted_images[i] = tf.image.random_contrast(distorted_images[i], lower=0.2, upper=1.8)
distorted_images[i] = tf.image.per_image_standardization(distorted_images[i])
#Stack the images
distorted_images = tf.stack(distorted_images)
#transpose to set the channel first
distorted_images = tf.transpose(distorted_images, perm=[0, 3, 1, 2])
#Unstack the images as the follow up operation are on single image
validrecord_images = tf.unstack(validrecord_images)
for i in xrange(len(validrecord_images)):
validrecord_images[i] = tf.image.per_image_standardization(validrecord_images[i])
#Stack the images
validrecord_images = tf.stack(validrecord_images)
#transpose to set the channel first
validrecord_images = tf.transpose(validrecord_images, perm=[0, 3, 1, 2])
#Unstack the images as the follow up operation are on single image
testrecord_images = tf.unstack(testrecord_images)
for i in xrange(len(testrecord_images)):
testrecord_images[i] = tf.image.per_image_standardization(testrecord_images[i])
#Stack the images
testrecord_images = tf.stack(testrecord_images)
#transpose to set the channel first
testrecord_images = tf.transpose(testrecord_images, perm=[0, 3, 1, 2])
global_step = tf.Variable(0, trainable=False)
boundaries = [10000, 15000, 20000, 25000]
values = [0.1, 0.05, 0.01, 0.005, 0.001]
learning_rate = tf.train.piecewise_constant(global_step, boundaries, values)
weight_decay = 2e-4
filters = 16 #the first resnet block filter number
n = 5 #the basic resnet block number, total network layers are 6n+2
ver = 2 #the resnet block version
#Get the inference logits by the model
result = resnet_model.inference(distorted_images, True, filters, n, ver)
#Calculate the cross entropy loss
cross_entropy = tf.losses.sparse_softmax_cross_entropy(labels=record_labels, logits=result)
cross_entropy_mean = tf.reduce_mean(cross_entropy, name='cross_entropy')
#Add the l2 weights to the loss
#Add weight decay to the loss.
l2_loss = weight_decay * tf.add_n(
# loss is computed using fp32 for numerical stability.
[tf.nn.l2_loss(tf.cast(v, tf.float32)) for v in tf.trainable_variables()])
tf.summary.scalar('l2_loss', l2_loss)
loss = cross_entropy_mean + l2_loss
#Define the optimizer
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.9)
#Relate to the batch normalization
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
opt_op = optimizer.minimize(loss, global_step)
valid_accuracy = tf.placeholder(tf.float32)
test_accuracy = tf.placeholder(tf.float32)
tf.summary.scalar("valid_accuracy", valid_accuracy)
tf.summary.scalar("test_accuracy", test_accuracy)
tf.summary.scalar("learning_rate", learning_rate)
validresult = tf.argmax(resnet_model.inference(validrecord_images, False, filters, n, ver), axis=1)
testresult = tf.argmax(resnet_model.inference(testrecord_images, False, filters, n, ver), axis=1)
#Create the session and run the graph
sess = tf.Session()
sess.run(tf.global_variables_initializer())
sess.run(iterator.initializer)
#Merge all the summary and write
summary_op = tf.summary.merge_all()
train_filewriter = tf.summary.FileWriter('train/', sess.graph)
step = 0
while(True):
try:
lossValue, lr, _ = sess.run([loss, learning_rate, opt_op])
if step % 100 == 0:
print "step %i: Learning_rate: %f Loss: %f" %(step, lr, lossValue)
if step % 1000 == 0:
saver.save(sess, 'model/my-model', global_step=step)
truepredictNum = 0
sess.run([testiterator.initializer, validiterator.initializer])
accuracy1 = 0.0
accuracy2 = 0.0
while(True):
try:
predictValue, testValue = sess.run([validresult, validrecord_labels])
truepredictNum += np.sum(predictValue==testValue)
except tf.errors.OutOfRangeError:
print "valid correct num: %i" %(truepredictNum)
accuracy1 = truepredictNum / 5000.0
break
truepredictNum = 0
while(True):
try:
predictValue, testValue = sess.run([testresult, testrecord_labels])
truepredictNum += np.sum(predictValue==testValue)
except tf.errors.OutOfRangeError:
print "test correct num: %i" %(truepredictNum)
accuracy2 = truepredictNum / 10000.0
break
summary = sess.run(summary_op, feed_dict={valid_accuracy: accuracy1, test_accuracy: accuracy2})
train_filewriter.add_summary(summary, step)
step += 1
except tf.errors.OutOfRangeError:
break
版权声明:本文为优快云博主「gzroy」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/gzroy/article/details/82386540
以上是转载的文章,因为我的电脑只有cpu,我想改成cpu能运行的版本,本来以为只是transpose改一下就可以,后面发现没那么简单:
1、注释掉3个transpose
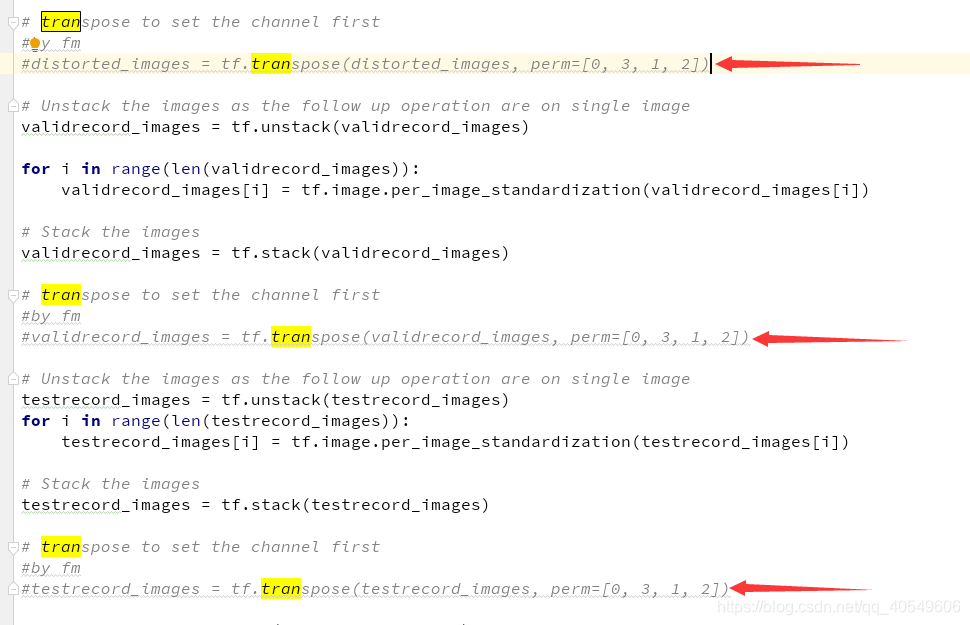
2、把resnet里的data_format都改成channels_last。
最隐蔽的是batch_normalization里的axis,原本设置为1,后面一直程序运行报错,我跟踪调试发现居然是在这一句出错,查了这个函数的用法,发现channels_first的时候设置为1,如果last就用默认的-1即可。
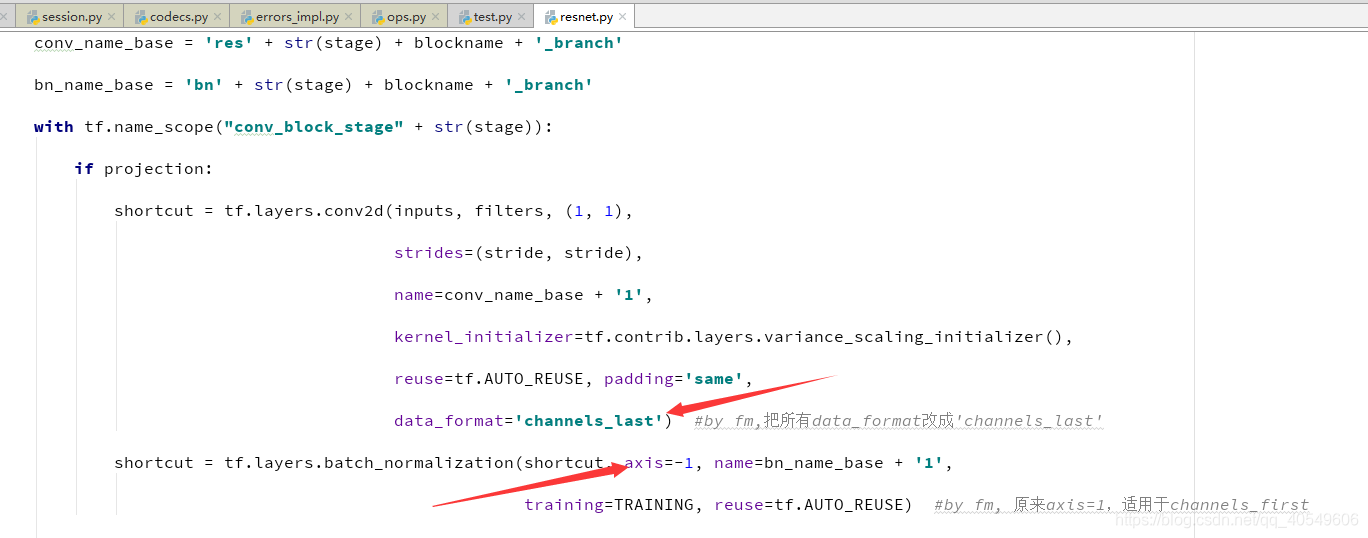
3、还有一个地方是,这里原来是[batch_size, c, h, w],所以对2,3列做reduce_mean。但是cpu上改成[batch_size, h, w, c],所以要对1,2列做reduce_mean。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









