







 TUDataset 是一个包含120多个图形数据集的集合,涵盖了小分子、生物信息学、时间图等多个领域。小分子数据集用于药物发现等场景;生物信息学数据集如DD、ENZYMES 和 PROTEINS 用于蛋白质特性分析;时间图数据集则关注个体间的接触或相互作用,适用于传播过程的研究。
TUDataset 是一个包含120多个图形数据集的集合,涵盖了小分子、生物信息学、时间图等多个领域。小分子数据集用于药物发现等场景;生物信息学数据集如DD、ENZYMES 和 PROTEINS 用于蛋白质特性分析;时间图数据集则关注个体间的接触或相互作用,适用于传播过程的研究。
TUDataset: A collection of benchmark datasets for learning with graphs
GitHub:https://github.com/chrsmrrs/tudataset
2.TUDATASET集合包含www.graphlearning.io上提供的120多个数据集。
2.1 Datasets
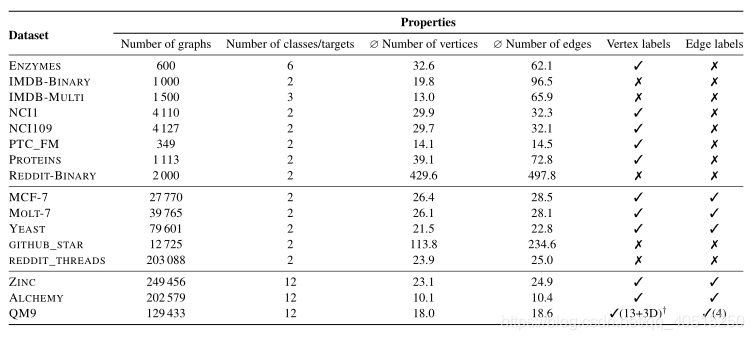
Small molecules. 小分子。一类常见的图形数据集由带有类别标签的小分子组成,代表例如药物发现项目中确定的毒性或生物活性。这里,一个图代表一个分子,即节点代表原子,边代表化学键。因此,标签编码原子和键的类型,可能有额外的化学属性。图形模型不同,例如,氢原子是否由节点明确表示,芳香环中的键被相应地注释。
Bioinformatics生物信息学。数据集DD, ENZYMES 以及PROTEINS代表大分子。Borgwardt等人(2005年)介绍了一种蛋白质的图形模型,其中节点代表二级结构元素,并由它们的类型,即螺旋、薄片或转弯,以及几个物理和化学信息来注释。如果两个节点是氨基酸序列的邻居或者是空间中三个最近的邻居之一,则一条边连接两个节点。使用这种方法,数据集酶来自BRENDA数据库(Schomburg等人,2004年)。在这里,任务是将酶分配到6个EC顶级类别之一,这反映了催化的化学反应。类似地,数据集蛋白质来源于(Dobson & Doig,2003),任务是预测蛋白质是否是酶。Shervashidze等人(2011年)使用的数据集DD基于相同的数据,但包含图形,其中节点表示单个氨基酸,边缘表示它们的空间邻近性。
temporal graphs最近,Oettershagen等人(2019)考虑了时间图,其中边缘表示两个个体在某个时间点的接触或相互作用。在研究传播过程时,例如流行病、谣言或假新闻的传播,这些图表很有意义。我们提供了从TUMBLR (Rozenshtein等人,2016)、DBLP和FACEBOOK (Viswanath等人,2009)以及麻省理工学院(Eagle & Pentland,2006)、一所高中的学生和传染病展览(Isella等人,2011)的参观者之间的联系中获得的时态图形分类数据集。
5.实验评估
数据集。我们使用了DEEZER_EGO_NETS、GITHUB _ STARGAZERS、ENYMES、IMDB-BINARY、IMDB-MULTI、MCF-7、MOLT-4、NCI1、PROTEINS、REDIT-BInary、REDDIT_THREADS、TWITCH_EGOS、UACC257图形分类数据集。此外,我们还使用了ALCHEMY、QM9、ZINC(多目标)回归数据集。数据集统计见网站和附录中的表4。我们选择不使用小数据集的连续节点特征(如果可用)和ALCHEMY数据集的3D坐标,只提供基于图形结构和离散标签的基线结果。在QM9数据集的情况下,我们紧密复制了Gilmer等人(2017)的(连续)节点和边缘特征。

















 4304
4304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









