







前言
HiPPO 是包括 S4、H3 等一系列 state space model (SSM) 相关模型的理论基石,提出了全新架构,旨在解决序列建模中的长距离依赖问题(long-term dependencies)。长距离依赖建模的核心问题在于如何用有限空间记录累计历史数据的信息,并随输入在线更新。当前主流模型大多有各种各样的问题,包括:
- 记忆范围有限,有 vanishing gradient 等问题
- 需要先验,并一定程度上受限于此
- 缺乏处理长距离依赖关系的理论保证
而这篇论文经数学推导,证明了HiPPO理论上可较好地处理长距离依赖关系,并提供了初始化参数,对后续研究产生了深远影响。
HiPPO: Recurrent Memory with Optimal Polynomial Projections
论文地址:https://arxiv.org/abs/2008.07669
正文
1.基本思路 —— 在线函数近似
我们希望通过某种方式将历史信息存储在一个向量中,借此处理长距离依赖关系。为便于分析,将所有历史输入看作一个关于时间的连续函数 f ( t ) f(t) f(t),最后再对其进行离散化处理。一个自然的思路是用一个性质更好的函数 g ( t ) g(t) g(t) 对其进行近似,随输入不断更新,达到预测未来的效果。而为将函数转换更容易处理的形式,希望将 g ( t ) g(t) g(t) 用一个向量 c = ( c i ) i \boldsymbol{c}=(c_i)_i c=(ci)i 表示,这就引出了取一组空间上的基,用系数表示函数的想法。我们还希望 ( c i ) i (c_i)_i (ci)i 满足某种递推关系,从而可以只考虑当前输入和向量的历史累计值。
以下将对这一过程进行更详细的说明。
1.1 目的
给定输入函数 f ( t ) ∈ R , ( t ≥ 0 ) f(t)\in \mathbb{R} ,(t\geq 0) f(t)∈R,(t≥0),对给定的 t 0 t_0 t0,记此时的历史为 f ≤ t 0 : = f ( x ) ∣ x ≤ t 0 f_{\leq t_0}:=f(x)|_{x\leq t_0} f≤t0:=f(x)∣x≤t0,它是否能用固定长度的向量 c ( t ) = ( c i ( t 0 ) ) i \boldsymbol{c}(t)=(c_i(t_0))_i c(t)=(ci(t0))i 近似地表示,并将其写成一个常微分方程的形式(离散条件下是递推式)?
1.2 如何判断近似的质量
评判近似质量需要定义一个在函数空间上的距离。我们选择一个概率测度 μ ( t ) \mu (t) μ(t) 代表每个时间点在近似时所占的权重(也即每个时间点的影响力有多大),而任何测度都诱导一个内积为 ⟨ f , g ⟩ μ = ∫ 0 + ∞ f ( x ) g ( x ) d μ ( x ) \left\langle f,g \right\rangle _\mu =\int_{0}^{+\infty} f(x)g(x)\,d\mu (x) ⟨f,g⟩μ=∫0+∞f(x)g(x)dμ(x),平方可积的函数空间(即希尔伯特空间,记为 H μ \mathcal{H} _\mu Hμ),对应范数为 ∥ f ∥ L 2 ( μ ) = ⟨ f , f ⟩ μ 1 / 2 \left\lVert f\right\rVert _{L_2(\mu)}=\left\langle f,f\right\rangle _\mu ^{1/2} ∥f∥L2(μ)=⟨f,f⟩μ1/2
我们最终想要一个次数有限的结果,因此我们取一个 H μ \mathcal{H} _\mu Hμ 的 N N N 维子空间 G \mathcal{G} G, N N N 代表了近似程度。在以下的论证中,均选择多项式作为自然基, G \mathcal{G} G 为次数低于 N N N 的多项式空间。
实际上并不要求如此选取,此处是出于多项式受到广泛研究,有更多现成结论的缘故。
由于对于时刻 t t t,我们仅关心 f ≤ t f_{\leq t} f≤t 的影响,令选择的测度随时间变化,记作 μ ( t ) \mu ^{(t)} μ(t),在 ( − ∞ , t ] (-\infty ,t] (−∞,t] 上度量。此时,近似程度便可以用距离 ∥ f ≤ t − g ( t ) ∥ L 2 ( μ ( t ) ) \left\lVert f_{\leq t}-g^{(t)}\right\rVert _{L_2(\mu ^{(t)})} f≤t−g(t) L2(μ(t)) 来表示。我们希望找到 g ( t ) ∈ G g^{(t)}\in \mathcal{G} g(t)∈G 使其取得最小值。
1.3 如何找到近似函数
近似函数可用其在 G \mathcal{G} G 的一组基下的展开中的 N N N 个系数来表示,关键在于如何选取适当的基。一个自然的选择是正交基 KaTeX parse error: Expected '}', got 'EOF' at end of input: …_n\}_{n,它可以扩展为 \mathcal{H} _\mu$$ 的一组正交基。
一个希尔伯特空间的正交基 { q n } \{q_n\} {qn} 也即满足
⟨ q i , q j ⟩ μ ( t ) = { 1 , i = j 0 , i ≠ j \left\langle q_i,q_j \right\rangle _{\mu ^{(t)}}=\begin{cases} 1, &i=j\\ 0, &i\neq j \end{cases} ⟨qi,qj⟩μ(t)={1,0,i=ji=j
的一组基(可用 Gram-Schmidt 正交化方法将非正交基转换为正交基得到)。特别地,对于 G \mathcal{G} G,一般 q n q_n qn 为一个 ( n − 1 ) (n-1) (n−1) 次多项式。
f ≤ t f_{\leq t} f≤t 可以表示为在 H μ \mathcal{H} _\mu Hμ 的正交基下的分解,因此 g ( t ) g^{(t)} g(t) 为 f ≤ t f_{\leq t} f≤t 在 G \mathcal{G} G 上的限制,即 g ( t ) g^{(t)} g(t) 在空间 G \mathcal{G} G 的正交基上分解的系数表达式为 c n ( t ) : = ⟨ f ≤ t , q n ⟩ μ ( t ) c_n^{(t)}:=\left\langle f_{\leq t},q_n\right\rangle _{\mu ^{(t)}} cn(t):=⟨f≤t,qn⟩μ(t)
2 HiPPO 架构
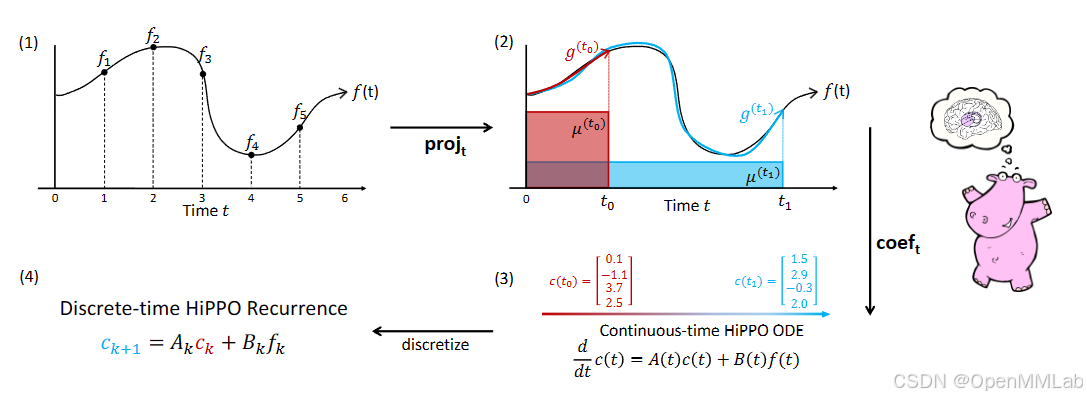
HiPPO 定义了两个映射:
- p r o j t \mathsf{proj}_t projt:给定连续输入函数 f f f 与概率测度 μ ( t ) \mu ^{(t)} μ(t),将 f ≤ t f_{\leq t} f≤t 映射到上文中的近似函数 g ( t ) g^{(t)} g(t)
- c o e f t \mathsf{coef}_t coeft:将 g ( t ) g^{(t)} g(t) 映射到系数向量 c ( t ) ∈ R N \boldsymbol{c}(t)\in \mathbb{R}^N c(t)∈RN
这两个映射的合成称为 h i p p o : = c o e f ∘ p r o j \mathsf{hippo}:=\mathsf{coef} \circ \mathsf{proj} hippo:=coef∘proj,也即 ( h i p p o ( f ) ) ( t ) = c ( t ) (\mathsf{hippo} (f))(t)=\boldsymbol{c}(t) (hippo(f))(t)=c(t)
2.1 ODE
我们的最终目标是将系数向量表示为递推形式,便于训练与推理。为了达到这一离散的目标,需要在连续情形下先写成 ODE 的形式,再对其离散化。
HiPPO 的另一个关键思想是将系数的计算式对 t t t求导。由于正交多项式由 Gram-Schmidt 计算得来,这往往会导致自相似关系,从而写成一个ODE的形式。具体地,HiPPO 证明了对于文中提及的几个概率测度 μ ( t ) \mu ^{(t)} μ(t),有特殊的 A ( t ) ∈ R N × N , B ( t ) ∈ R N × 1 A(t)\in \mathbb{R} ^{N\times N}, B(t)\in \mathbb{R} ^{N\times 1} A(t)∈RN×N,B(t)∈RN×1 满足:
c ˙ ( t ) = A ( t ) c ( t ) + B ( t ) f ( t ) \dot {\boldsymbol{c}}(t)=A(t)\boldsymbol{c}(t)+B(t)f(t) c˙(t)=A(t)c(t)+B(t)f(t)
2.2 如何离散化
在实际操作中,输入输出都相对时间离散,因此需要对上式进行离散化操作,整体分为四步:
- 接收输入序列 ( f k ) k ∈ N (f_k)_{k\in \mathbb{N}} (fk)k∈N
- 对于时间离散步长 Δ t \Delta t Δt,隐性定义连续函数 f ( t ) f(t) f(t),满足 f ( k ⋅ Δ t ) = f k f(k\cdot \Delta t)=f_k f(k⋅Δt)=fk
- 写出函数 c ( t ) \boldsymbol{c}(t) c(t) 的 ODE 表达式
- 重新离散为输出序列 c k : = c ( k ⋅ Δ t ) \boldsymbol{c}_k:=\boldsymbol{c}(k\cdot \Delta t) ck:=c(k⋅Δt)
通常,这一过程对于时间离散步长 Δ t \Delta t Δt 的选择是敏感的。
注意此处的 c k \boldsymbol{c}_k ck 为向量,与上文中有所不同。
2.3 广义双线性变换法(GBT)
离散化算法的选取有许多种,考虑到后续工作中使用了双线性变换法,此处介绍更为普适的广义双线性变换法(Generalized Bilinear Transformation, GBT)。
记 ODE 为 c ˙ ( t ) : = h ( t , c ( t ) ) \dot {\boldsymbol{c}}(t):=h(t,\boldsymbol{c}(t)) c˙(t):=h(t,c(t)),可将其改写为
c ( t + Δ t ) − c ( t ) = ∫ t t + Δ t h ( s , c ( s ) ) d s \boldsymbol{c}(t+\Delta t)-\boldsymbol{c}(t)=\int_{t}^{t+\Delta t} h(s,\boldsymbol{c}(s))\,ds c(t+Δt)−c(t)=∫tt+Δth(s,c(s))ds
GBT 通过取两端点的加权平均将右式近似为 Δ t [ ( 1 − α ) h ( t , c ( t ) ) + α h ( t + Δ t , c ( t + Δ t ) ) ] \Delta t[(1-\alpha)h(t,\boldsymbol{c}(t))+\alpha h(t+\Delta t,\boldsymbol{c}(t+\Delta t))] Δt[(1−α)h(t,c(t))+αh(t+Δt,c(t+Δt))] ( ∗ ) \boldsymbol{(*)} (∗),其中 α ∈ [ 0 , 1 ] \alpha \in [0,1] α∈[0,1]。
当 c ˙ ( t ) = A c ( t ) + B f ( t ) \dot {\boldsymbol{c}}(t)=A\boldsymbol{c}(t)+Bf(t) c˙(t)=Ac(t)+Bf(t) 时将其代入 ( ∗ ) \boldsymbol{(*)} (∗),整理可得:
( I − Δ t α A ) c ( t + Δ t ) = ( I + Δ t ( 1 − α ) A ) c ( t ) + Δ t B f ( t ) (I-\Delta t\alpha A)\boldsymbol{c}(t+\Delta t)=(I+\Delta t(1-\alpha)A)\boldsymbol{c}(t)+\Delta tBf(t) (I−ΔtαA)c(t+Δt)=(I+Δt(1−α)A)c(t)+ΔtBf(t)
因此
c ( t + Δ t ) = ( I − Δ t α A ) − 1 ( I + Δ t ( 1 − α ) A ) c ( t ) + Δ t ( I − Δ t α A ) − 1 B f ( t ) \boldsymbol{c}(t+\Delta t)=(I-\Delta t\alpha A)^{-1}(I+\Delta t(1-\alpha)A)\boldsymbol{c}(t)+\Delta t(I-\Delta t\alpha A)^{-1}Bf(t) c(t+Δt)=(I−ΔtαA)−1(I+Δt(1−α)A)c(t)+Δt(I−ΔtαA)−1Bf(t)
注意到 c k : = c ( k ⋅ Δ t ) \boldsymbol{c}_k:=\boldsymbol{c}(k\cdot \Delta t) ck:=c(k⋅Δt),上式也即:
c k + 1 = ( I − Δ t α A ) − 1 ( I + Δ t ( 1 − α ) A ) c k + Δ t ( I − Δ t α A ) − 1 B f k \boldsymbol{c}_{k+1}=(I-\Delta t\alpha A)^{-1}(I+\Delta t(1-\alpha)A)\boldsymbol{c}_k+\Delta t(I-\Delta t\alpha A)^{-1}Bf_k ck+1=(I−ΔtαA)−1(I+Δt(1−α)A)ck+Δt(I−ΔtαA)−1Bfk
为一个关于 { c k } \{\boldsymbol{c}_k\} {ck} 的递推式。
此处假定 A A A 与 B B B 均为时间不变量,若随时间改变,也可用相同思路计算。
在 GBT 中, α \alpha α 取特殊值时有不同别名。当 α = 0 \alpha =0 α=0 时称前向欧拉法, α = 1 \alpha =1 α=1 时称反向欧拉法, α = 1 / 2 \alpha =1/2 α=1/2 时称双线性变换法。
3 实例:LegT,LagT,LegS
在选择多项式空间的基础上,根据不同的概率测度,该论文着重分析了三个实例:translated Legendre (LegT),translated Laguerre (LagT),scaled Legendre (LegS)。
下图为三种概率测度的图示,蓝色与紫色部分分别代表 t = t 0 t=t_0 t=t0 与 t = t 1 t=t_1 t=t1 时刻的 μ ( t ) ( x ) \mu ^{(t)}(x) μ(t)(x)

由于 LegS 的表现最好,下文将简要带过前两者,并主要关注于 LegS。
3.1 LegS
LegS 选取的概率测度为 μ ( t ) = 1 t I [ 0 , t ] \mu ^{(t)}=\frac{1}{t}\mathbb{I}_{[0,t]} μ(t)=t1I[0,t],为所有历史分配相同的权重,随时间的推移缩放窗口。这是最直观的记忆方式。以下,将从这一多项式空间的正交基出发,计算 c \boldsymbol{c} c 的导数,并得出 ODE 和递推式的表达。
3.1.1 正交基
首先,我们需要知道 H μ ( t ) \mathcal{H} _{\mu ^{(t)}} Hμ(t) 的正交基。考虑到测度的形式, H μ ( t ) \mathcal{H} _{\mu ^{(t)}} Hμ(t) 的正交基与 Legendre 多项式的数学表达式非常类似。
Legendre 多项式 { P n ( x ) } \{P_n(x)\} {Pn(x)} 是在内积取 ⟨ f , g ⟩ = ∫ − 1 1 f ( x ) g ( x ) d x \left\langle f,g \right\rangle =\int_{-1}^{1} f(x)g(x)\,dx ⟨f,g⟩=∫−11f(x)g(x)dx 时,从自然基 { 1 , x , x 2 , ⋯ } \{1,x,x^2,\cdots\} {1,x,x2,⋯} 出发进行 Gram-Schmidt 计算得到的结果,使得:
2 n + 1 2 ∫ − 1 1 P n ( x ) P m ( x ) d x = δ n m , δ n m = { 1 , i = j 0 , i ≠ j \frac{2n+1}{2}\int_{-1}^{1} P_n(x)P_m(x)\,dx=\delta_{nm}, \delta_{nm}=\begin{cases} 1, &i=j\\ 0, &i\neq j \end{cases} 22n+1∫−11Pn(x)Pm(x)dx=δnm,δnm={1,0,i=ji=j
且有 P n ( 1 ) , P n ( − 1 ) = ( − 1 ) n P_n(1), P_n(-1)=(-1)^n Pn(1),Pn(−1)=(−1)n
P n ( x ) P_n(x) Pn(x) 也可用求导表示:
P 0 ( x ) = 1 , P n ( x ) = 1 2 n n ! d n d x n ( x 2 − 1 ) n , x ∈ [ − 1 , 1 ] , n = 1 , 2 , ⋯ P_0(x)=1, P_n(x)=\frac{1}{2^nn!}\frac{d^n}{dx^n}(x^2-1)^n,x\in [-1,1],n=1,2,\cdots P0(x)=1,Pn(x)=2nn!1dxndn(x2−1)n,x∈[−1,1],n=1,2,⋯
Legendre 多项式有以下性质:
( 2 n + 1 ) P n = P n + 1 ′ − P n − 1 ′ P n + 1 ′ = ( n + 1 ) P n + x P n ′ \begin{aligned} (2n+1)P_n &=P_{n+1}^{\prime}-P_{n-1}^{\prime}\\ P_{n+1}^{\prime} &=(n+1)P_n+xP_n^{\prime} \end{aligned} (2n+1)PnPn+1′=Pn+1′−Pn−1′=(n+1)Pn+xPn′
在当前的测度之下,考虑内积表达式 ⟨ q n , q m ⟩ μ = ∫ 0 t q n ( u ) q m ( u ) d μ ( u ) \left\langle q_n,q_m \right\rangle _\mu =\int_{0}^{t} q_n(u)q_m(u)\,d\mu (u) ⟨qn,qm⟩μ=∫0tqn(u)qm(u)dμ(u),由于 μ ( t ) = 1 t I [ 0 , t ] \mu ^{(t)}=\frac{1}{t}\mathbb{I}_{[0,t]} μ(t)=t1I[0,t],我们希望
∫ 0 t q n ( u ) q m ( u ) 1 t d u = δ n m , δ n m = { 1 , i = j 0 , i ≠ j \int_{0}^{t} q_n(u)q_m(u)\frac{1}{t}\,du=\delta_{nm}, \delta_{nm}=\begin{cases} 1, &i=j\\ 0, &i\neq j \end{cases} ∫0tqn(u)qm(u)t1du=δnm,δnm={1,0,i=ji=j
与 Legendre 多项式计算式中的积分表达与上下限进行比较可知,对 Legendre 多项式进行 x : = 2 u t − 1 x:=\frac{2u}{t}-1 x:=t2u−1 的变量替换,得到
2 n + 1 t ∫ 0 t P n ( 2 u t − 1 ) P m ( 2 u t − 1 ) d u = δ n m , δ n m = { 1 , i = j 0 , i ≠ j \frac{2n+1}{t}\int_{0}^{t} P_n(\frac{2u}{t}-1)P_m(\frac{2u}{t}-1)\,du=\delta_{nm}, \delta_{nm}=\begin{cases} 1, &i=j\\ 0, &i\neq j \end{cases} t2n+1∫0tPn(t2u−1)Pm(t2u−1)du=δnm,δnm={1,0,i=ji=j
此时相差常数倍,因此 H μ ( t ) \mathcal{H} _{\mu ^{(t)}} Hμ(t) 的正交基即为将 Legendre 多项式进行缩放与平移的结果,可写作 q n ( t ) ( x ) = ( 2 n + 1 ) 1 / 2 P n ( 2 x t − 1 ) q_n^{(t)}(x)=(2n+1)^{1/2}P_n(\frac{2x}{t}-1) qn(t)(x)=(2n+1)1/2Pn(t2x−1)
3.1.2 系数求导
记 ω ( t , x ) = 1 t I [ 0 , t ] , q n ( t , x ) = q n ( t ) \omega (t,x)=\frac{1}{t}\mathbb{I} _{[0,t]},q_n(t,x)=q_n^{(t)} ω(t,x)=t1I[0,t],qn(t,x)=qn(t) ,对 t t t 求偏导,结合 Legendre 多项式的性质可知:
∂ ∂ t q n ( t , x ) = − t − 1 ( 2 n + 1 ) 1 / 2 [ n ( 2 n + 1 ) − 1 2 q n ( t , x ) + ( 2 n − 1 ) 1 2 q n − 1 ( t , x ) + ⋯ ] \frac{\partial}{\partial t}q_n(t,x)=-t^{-1}(2n+1)^{1/2}[n(2n+1)^{-\frac{1}{2}}q_n(t,x)+(2n-1)^{\frac{1}{2}}q_{n-1}(t,x)+\cdots] ∂t∂qn(t,x)=−t−1(2n+1)1/2[n(2n+1)−21qn(t,x)+(2n−1)21qn−1(t,x)+⋯]
回忆到 c n ( t ) = ⟨ f ≤ t , q n ⟩ μ ( t ) c_n{(t)}=\left\langle f_{\leq t},q_n\right\rangle _{\mu ^{(t)}} cn(t)=⟨f≤t,qn⟩μ(t),再让 c n ( t ) c_n(t) cn(t) 对 t t t 求偏导,整理可得:
d d t c n ( t ) = − t − 1 ( 2 n + 1 ) 1 / 2 [ ( n + 1 ) ( 2 n + 1 ) − 1 2 c n ( t ) + ( 2 n − 1 ) 1 2 c n − 1 ( t ) + ⋯ ] + t − 1 ( 2 n + 1 ) 1 / 2 f ( t ) \frac{d}{dt}c_n(t)=-t^{-1}(2n+1)^{1/2}[(n+1)(2n+1)^{-\frac{1}{2}}c_n(t)+(2n-1)^{\frac{1}{2}}c_{n-1}(t)+\cdots]+t^{-1}(2n+1)^{1/2}f(t) dtdcn(t)=−t−1(2n+1)1/2[(n+1)(2n+1)−21cn(t)+(2n−1)21cn−1(t)+⋯]+t−1(2n+1)1/2f(t)
观察等式,发现 c ( t ) \boldsymbol{c}(t) c(t) 每个维度的导数都可以表示成 c k ( t ) c_k(t) ck(t) 与 f ( t ) f(t) f(t) 的线性组合,这正是我们想要的形式。因此,可以写作矩阵形式 c ˙ ( t ) = − 1 t A c ( t ) + 1 t B f ( t ) \dot {\boldsymbol{c}}(t)=-\frac{1}{t}A\boldsymbol{c}(t)+\frac{1}{t}Bf(t) c˙(t)=−t1Ac(t)+t1Bf(t) ,其中 A n k A_{nk} Ank 为 d d t c n ( t ) \frac{d}{dt}c_n(t) dtdcn(t) 中 c k ( t ) c_k(t) ck(t) 的系数。
而对这一结果运用双线性变换法即可得到离散表达,完整结论见下文。需要注意的是, LegS 的离散形式独立于时间离散步长 Δ t \Delta t Δt
3.1.3 结论
HiPPO-LegS 中在连续与离散情况下的变化为: c ˙ ( t ) = − 1 t A c ( t ) + 1 t B f ( t ) , c k + 1 = ( 1 − A k ) c k + 1 k B f k \dot {\boldsymbol{c}}(t)=-\frac{1}{t}A\boldsymbol{c}(t)+\frac{1}{t}Bf(t), \boldsymbol{c}_{k+1}=(1-\frac{A}{k})\boldsymbol{c}_k+\frac{1}{k}Bf_k c˙(t)=−t1Ac(t)+t1Bf(t),ck+1=(1−kA)ck+k1Bfk
其中 B n = ( 2 n + 1 ) 1 2 B_n=(2n+1)^{\frac{1}{2}} Bn=(2n+1)21,$$A_{nk}=\begin{cases} (2n+1){1/2}(2k+1){1/2}, &n>k\ n+1, &n=k\ 0, &n
3.2 LegT & LagT
LegT 选取的概率测度为 μ ( t ) ( x ) = 1 θ I [ t − θ , t ] ( x ) \mu ^{(t)}(x)=\frac{1}{\theta}\mathbb{I}_{[t-\theta,t]}(x) μ(t)(x)=θ1I[t−θ,t](x),为一长度固定的窗口。LagT 选取的测度为 μ ( t ) ( x ) = e − ( t − x ) I ( − ∞ , t ] ( x ) = { e − ( t − x ) , x ≤ t 0 , x > t \mu ^{(t)}(x)=e^{-(t-x)}\mathbb{I}_{(-\infty,t]}(x)=\begin{cases} e^{-(t-x)}, &x\leq t\\ 0, &x>t \end{cases} μ(t)(x)=e−(t−x)I(−∞,t](x)={e−(t−x),0,x≤tx>t,从当前时刻向前指数递减。
对于这两种测度,均有 ODE 为 c ˙ ( t ) = − A c ( t ) + B f ( t ) \dot {\boldsymbol{c}}(t)=-A\boldsymbol{c}(t)+Bf(t) c˙(t)=−Ac(t)+Bf(t) 的形式,其中 A A A 与 B B B 如下(证明类似 LegS 的情形):
LegT: A n k = 1 θ { ( − 1 ) n − k ( 2 n + 1 ) , n ≥ k 2 n + 1 , n ≤ k A_{nk}=\frac{1}{\theta}\begin{cases} (-1)^{n-k}(2n+1), &n\geq k\\ 2n+1, &n\leq k \end{cases} Ank=θ1{(−1)n−k(2n+1),2n+1,n≥kn≤k, B n = 1 θ ( 2 n + 1 ) ( − 1 ) n B_n=\frac{1}{\theta}(2n+1)(-1)^n Bn=θ1(2n+1)(−1)n
LagT: KaTeX parse error: Expected & or \\ or \cr or \end at end of input: … k\\ 0, &n, B_n=1$$
4 LegS的优势与特性
在论文中,指出了三个 HiPPO-LegS 的优势,并分析了近似造成的误差幅度,以下对此进行介绍。
4.1 时间尺度的鲁棒性
LegS 具有时间等变性,也就是说,对任意的 α > 0 \alpha >0 α>0,如果 h ( t ) : = f ( α t ) h(t):=f(\alpha t) h(t):=f(αt),则必有 h i p p o ( h ) ( t ) = h i p p o ( f ) ( α t ) \mathsf{hippo}(h)(t)=\mathsf{hippo}(f)(\alpha t) hippo(h)(t)=hippo(f)(αt)。这意味着它可以从某个时间尺度自然地迁移到其他尺度。
4.2 计算效率高
回忆 GBT 的推导过程,在更新 c k \boldsymbol{c}_k ck 时实质上在计算形如 ( I − Δ t α A ) − 1 (I-\Delta t\alpha A)^{-1} (I−ΔtαA)−1 和 ( I + Δ t ( 1 − α ) A ) (I+\Delta t(1-\alpha)A) (I+Δt(1−α)A) 的矩阵与向量的乘积。由于 A A A 的特殊结构,这一过程可以被大幅压缩,加快计算速度。这一结论在 Efficiently Modeling Long Sequences with Structured State Spaces 中有详细说明。
4.3 对历史信息遗忘速度慢
RNN 的遗忘速度为指数级,而 LegS 为多项式级,具体地有 ∥ ∂ c l + 1 ∂ f k ∥ = Θ ( 1 / l ) \left\lVert \frac{\partial c_{l+1}}{\partial f_k}\right\rVert =\Theta (1/l) ∂fk∂cl+1 =Θ(1/l)。
这是由于 c l \boldsymbol{c}_l cl 的递推形式,可以将其展开至由 f k f_k fk 表示,求偏导知 ∂ c l + 1 ∂ f k = ( I − A l ) ⋯ ( I − A k + 1 ) B k \frac{\partial c_{l+1}}{\partial f_k}=(I-\frac{A}{l})\cdots (I-\frac{A}{k+1})\frac{B}{k} ∂fk∂cl+1=(I−lA)⋯(I−k+1A)kB 由于 I − A n I-\frac{A}{n} I−nA 为可交换的可对角化矩阵(考虑到 A A A 下三角),可写作 ∂ c l + 1 ∂ f k = P − 1 D P B \frac{\partial c_{l+1}}{\partial f_k}=P^{-1}DPB ∂fk∂cl+1=P−1DPB,其中 D D D 为对角矩阵,它的最大对角元为 ρ = ( 1 − 1 l ) ⋯ ( 1 − 1 k + 1 ) 1 k \rho=(1-\frac{1}{l})\cdots (1-\frac{1}{k+1})\frac{1}{k} ρ=(1−l1)⋯(1−k+11)k1 取对数后分析可知 ρ = Θ ( 1 / l ) \rho=\Theta (1/l) ρ=Θ(1/l),因而原式成立。
这说明了 LegS 可以处理更长距离的内容。
4.4 误差与输入平滑度的关联
在 HiPPO 中有一步近似操作,其导致的误差与 f f f 的光滑度密切相关。
- 当 f f f 满足 L-Lipschitz 条件时(即对于 ∀ x , y ∈ [ 0 , t ] \forall x,y\in [0,t] ∀x,y∈[0,t],有 ∣ f ( x ) − f ( y ) ∣ ≤ L ∣ x − y ∣ \left\lvert f(x)-f(y)\right\rvert \leq L\left\lvert x-y\right\rvert ∣f(x)−f(y)∣≤L∣x−y∣ ),则 ∥ f ≤ t − g ( t ) ∥ = O ( t L / N ) \left\lVert f_{\leq t}-g^{(t)}\right\rVert =O(tL/\sqrt{N}) f≤t−g(t) =O(tL/N)
- 当 f f f 有 k k k 阶有界导数时,则 ∥ f ≤ t − g ( t ) ∥ = O ( t k N − k + 1 / 2 ) \left\lVert f_{\leq t}-g^{(t)}\right\rVert =O(t^kN^{-k+1/2}) f≤t−g(t) =O(tkN−k+1/2)
结语
文章根据在线函数近似的思路提出了 HiPPO 架构,解释了可以通过递推式反映历史的根本原因,主要理论核心是对若干概率测度的情形给出了 HiPPO 初始化实例,其中论证了取测度为 μ ( t ) = 1 t I [ 0 , t ] \mu ^{(t)}=\frac{1}{t}\mathbb{I}_{[0,t]} μ(t)=t1I[0,t] 的 HiPPO-LegS 的优势。同时,ODE 的形式也启发后续对 SSM 的使用。

















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









