




本文来源公众号“OpenMMLab”,仅用于学术分享,侵权删,干货满满。
原文链接:如何解决大模型长距离依赖问题?HiPPO 技术深度解析
HiPPO 是包括 S4、H3 等一系列 state space model (SSM) 相关模型的理论基石,提出了全新架构,旨在解决序列建模中的长距离依赖问题(long-term dependencies)。长距离依赖建模的核心问题在于如何用有限空间记录累计历史数据的信息,并随输入在线更新。当前主流模型大多有各种各样的问题,包括:
-
记忆范围有限,有 vanishing gradient 等问题
-
需要先验,并一定程度上受限于此
-
缺乏处理长距离依赖关系的理论保证
而这篇论文经数学推导,证明了 HiPPO 理论上可较好地处理长距离依赖关系,并提供了初始化参数,对后续研究产生了深远影响。
论文标题:
HiPPO: Recurrent Memory with Optimal Polynomial Projections
论文地址:
https://arxiv.org/abs/2008.07669
1 基本思路 —— 在线函数近似

以下将对这一过程进行更详细的说明。
1.1 目的

1.2 如何判断近似的质量

1.3 如何找到近似函数

2 HiPPO 架构
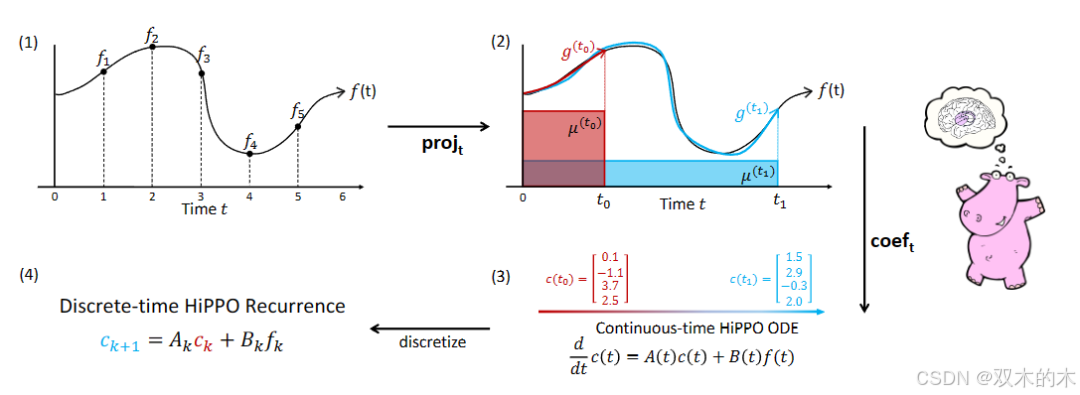
HiPPO

2.1 ODE

2.2 如何离散化

2.3 广义双线性变换法(GBT)


3 实例:LegT,LagT,LegS
在选择多项式空间的基础上,根据不同的概率测度,该论文着重分析了三个实例:translated Legendre (LegT),translated Laguerre (LagT),scaled Legendre (LegS)。
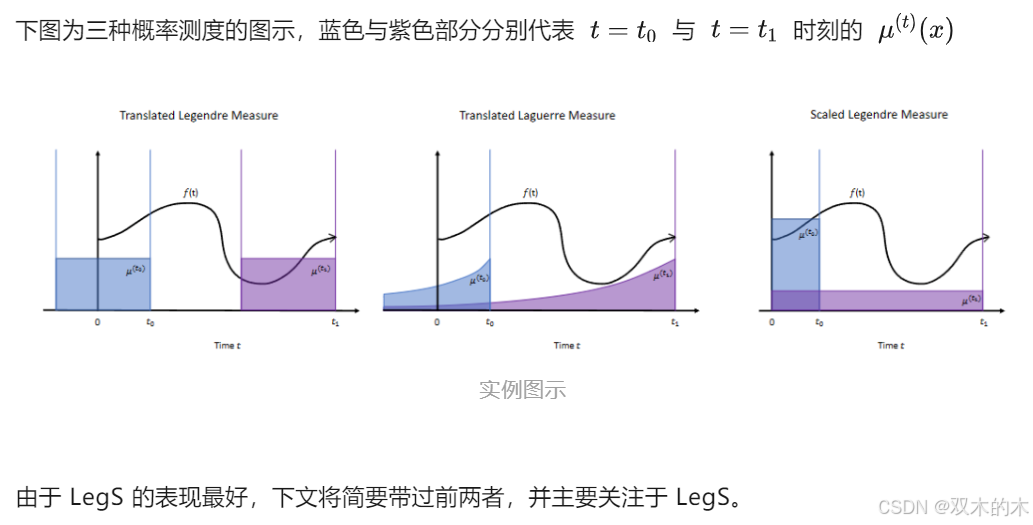
3.1 LegS

3.1.1 正交基



3.1.2 系数求导

3.1.3 结论

3.2 LegT \& LagT

4 LegSc的优势与特性
在论文中,指出了三个 HiPPO-LegS 的优势,并分析了近似造成的误差幅度,以下对此进行介绍。
4.1 时间尺度的鲁棒性

4.2 计算效率高

4.3 对历史信息遗忘速度慢

4.4 误差与输入平滑度的关联

5 结语
文章根据在线函数近似的思路提出了 HiPPO 架构,解释了可以通过递推式反映历史的根本原因,主要理论核心是对若干概率测度的情形给出了 HiPPO 初始化实例,其中论证了取测度为 的 HiPPO-LegS 的优势。同时,ODE 的形式也启发后续对 SSM 的使用。
参考:https://zhuanlan.zhihu.com/p/613713261
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1888
1888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









