




目录
1. 实验概述
1.1. 实验代号
本次实验代号为halibut。
1.2. 实验目的
本实验是一次对于数据集成的操作实践,实验目的在于通过使用Kettle工具的Spoon组件,实现从FTP服务器获取日志数据并将其整理、处理后存储到MySQL数据库的完整流程。这一过程不仅能加深我们对信息系统集成与管理的理解,也能够大大锻炼我们在实际工作中应用ETL技术的能力。
2. 实验准备
2.1. 实验要求
本次实验的要求为:在Kettle中使用Spoon工具向ftp server中的halibut.log(个人日志文件)发起请求,并通过设计一系列的转换规则,将数据进行格式整理后加载到数据库表中,并导出相应的SQL文件。
最终提交成果:
- 实验描述文档(本文档)
- halibut.sql文件
2.2. 环境搭建
2.2.1. 系统环境
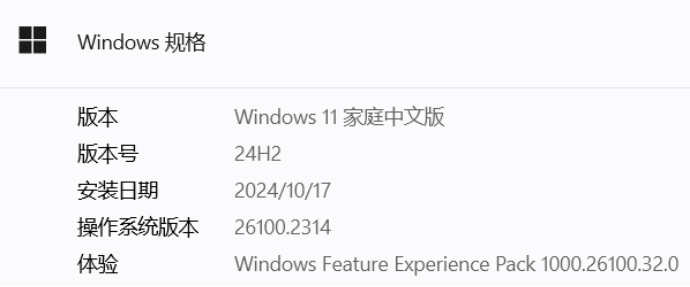
本次实验的操作系统为Windows 11。
2.2.2. FTP服务器
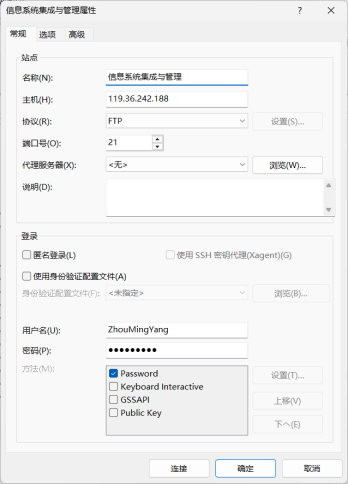
本实验使用的服务器为信息系统集成与管理课程指定的ftp服务器,服务器信息及个人用户登录信息如下:
- 主机地址:119.36.242.188
- 协议:FTP
- 端口:21
- 用户名:ZhouMingYang
- 密码:zmy020022
- 连接工具:Xftp 8
2.2.3. MySQL
-
数据库:MySQL
-
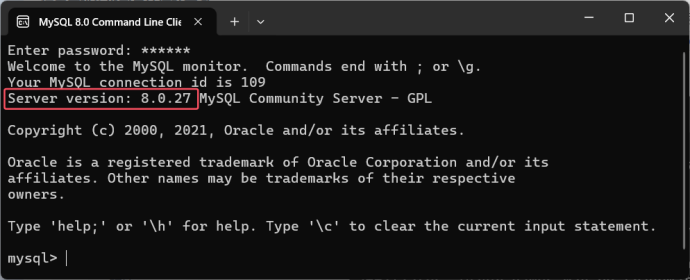
版本:8.0.27
-
安装包为课程ftp服务器中提供的msi文件,具体安装流程参考经验帖:https://blog.youkuaiyun.com/m0_71422677/article/details/136007088。
-
安装完成后启动MySQL提供的 Command Line Client,输入root账号密码后可进入服务器控制台。
2.2.4. Java环境
- 版本:1.17.0.7
- 由于oracle官网加载太慢且下载jdk安装包需要登录账号,我使用了国内镜像源编程宝库进行下载:http://www.codebaoku.com/jdk/jdk-index.html
- 下载好安装包后,具体安装流程参考经验帖:https://blog.youkuaiyun.com/m0_74137224/article/details/136332384
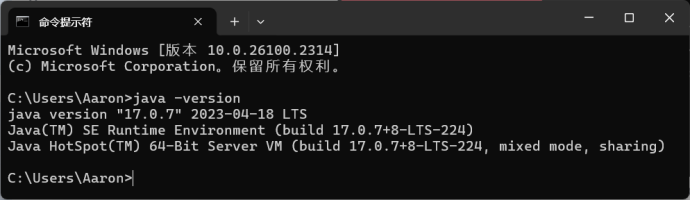
- 安装完成且配置好环境变量后,启动cmd,查看Java版本信息:
-
java --version
2.2.5. Kettle
- 版本:9.3.0.0-428
- Kettle工具为课程FTP服务器提供的2022年版本,下载pdi-ce-9.3.0.0-428.zip文件后解压,即可直接使用。
- 启动Kettle目录中的Spoon.bat,若环境配置无异常则可正常启动Spoon图形化界面。
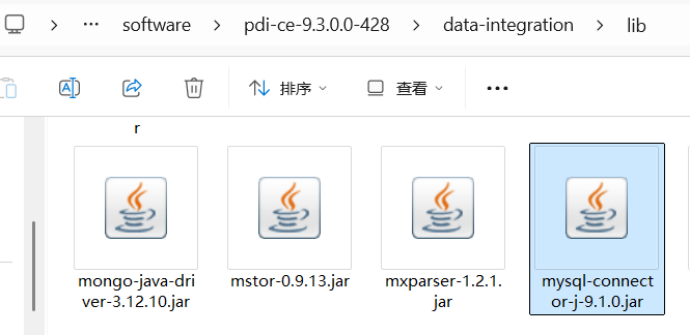
- 若要实现与MySQL数据库的连接,则还需下载MySQL Connector java连接驱动,并放置于Kettle目录的lib文件夹下。驱动下载方式参考经验帖:https://blog.youkuaiyun.com/weixin_44031029/article/details/109284132
2.3. 数据准备
本次实验的原始数据为个人在信息系统集成与管理课程中访问FTP数据库的日志文件halibut.log,存放于ftp server,共包含14个字段,记录数因人而异。
每个字段的具体含义如下所示:
| 字段 | 示例 | 描述 |
| date | Tue Nov 16 15:41:44 2021 | 记录的时间 |
| consumed_time | 1 | 传输⽂件花费的时间(秒) |
| ip | 113.57.80.253 | 客户端ip地址 |
| file_size | 437423 | 传输的⽂件⼤⼩(byte) |
| file_name | /zhuguobin/Maze.zip | 传输的⽂件 |
| trans_type | b | 传输类型,b表示⼆进制传输,a表示 ascii码传输 |
| special_op | _ | 特殊动作标记 |
| trans_method | i | 传输⽅法,o表示从服务器下载,i表示 向服务器上传 |
| visit_mode | g | 访问模式,g表示虚拟用户,a表示匿名 用户 |
| user | profzhu | 用户名 |
| service | ftp | 服务名 |
| autho_method | 0 | 授权方式 |
| autho_ip | * | 表示授权用户已认证IP |
| status | c | 完成状态,c表示complete, i表示 incomplete |
3. 实验内容
3.1. 整体作业流程设计
在Spoon中,可自行设计自动化作业流程,完成从ftp获取数据、数据格式转换、数据入库、导出数据、直到测试SQL数据的一系列操作。
本实验设计的作业流程task1.kjb如下:
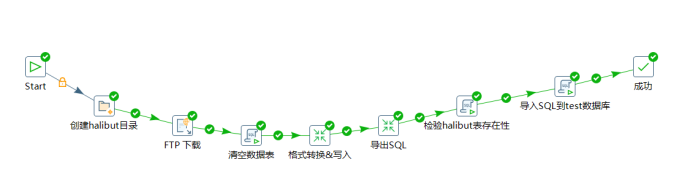
实验中用到的两个转换(格式转换 transform和导出SQL export)分别如下:

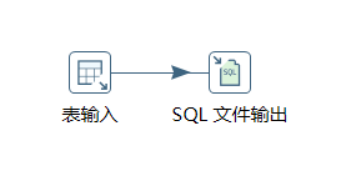
3.2. 创建数据库、数据表
启动MySQL Command Line Client,建立一个新的数据库infoSysZmy。
CREATE DATABASE infoSysZmy;
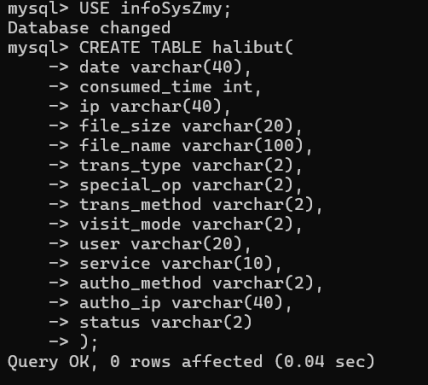
切换到infoSysZmy数据库,然后建立一个新的表halibut:
USE infoSysZmy;
CREATE TABLE halibut(
date varchar(40),
consumed_time int,
ip varchar(40),
file_size varchar(20),
file_name varchar(100),
trans_type varchar(2),
special_op varchar(2),
trans_method varchar(2),
visit_mode varchar(2),
user varchar(20),
service varchar(10),
autho_method varchar(2),
autho_ip varchar(40),
status varchar(2)
);
检查表结构:
desc halibut;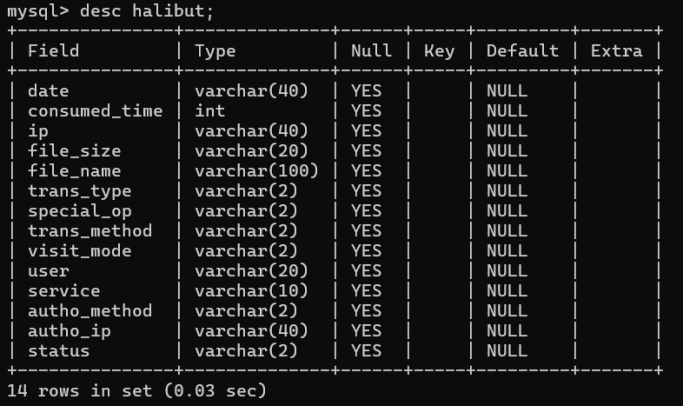
3.3. 数据库连接
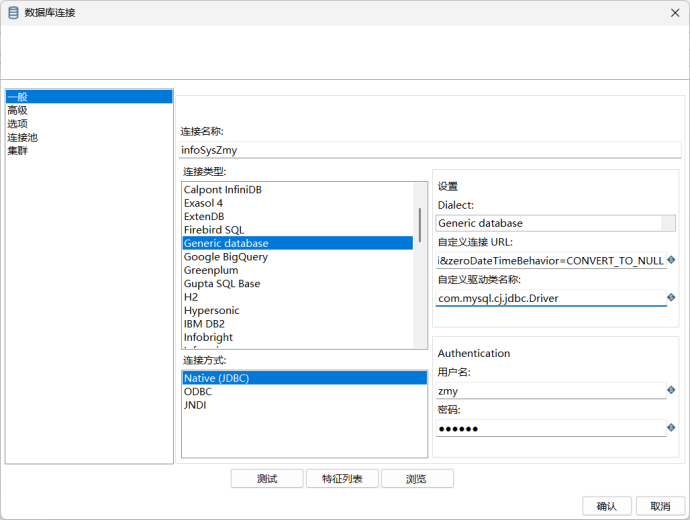
在Spoon中新建作业,命名为task1,然后在其中新建DB连接。
由于我使用的是MySQL8.0,在尝试连接数据库时点击测试按钮始终没有反应,研究后发现,该版本的MySQL不能通过MySQL类型直接连接,而是要使用Generic database类型的连接,输入URL和驱动类名称后即可成功连接。【URL中的localhost、3306、infoSysZmy分别对应数据库的地址、端口和数据库名】
- URL:jdbc:mysql://localhost:3306/infoSysZmy?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=Asia/Shanghai&zeroDateTimeBehavior=CONVERT_TO_NULL
- 驱动:com.mysql.cj.jdbc.Driver
测试连接,显示如下弹窗即表明连接成功:

3.4. 定义转换规则
在Spoon中新建作业task1,设计如下步骤:
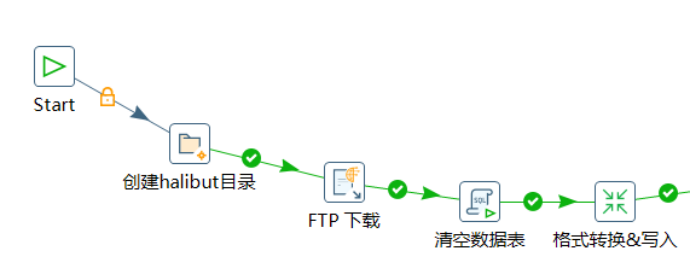
3.4.1. 新建halibut目录
步骤:核心对象/文件管理/创建一个目录
本步骤为个人习惯,规范化整理输入及输出文件,于是将task1放置于Kettle目录内的halibut文件夹内,便于统一流程的输出文件。该步骤用于检查halibut文件夹的存在性,正常情况下可无需此步骤。
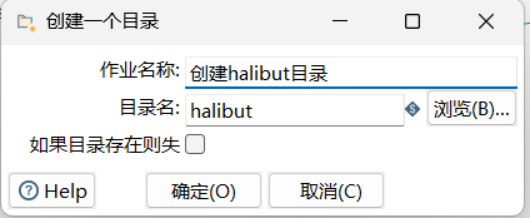
3.4.2. FTP下载
步骤:核心对象/文件传输/FTP下载
实验要求禁止预先下载好halibut.log文件后作为本地文件输入到流程中,因此我们需要在流程中自动下载FTP服务器中最新的halibut.log文件,并作为后续数据的输入源。
测试连接请求:
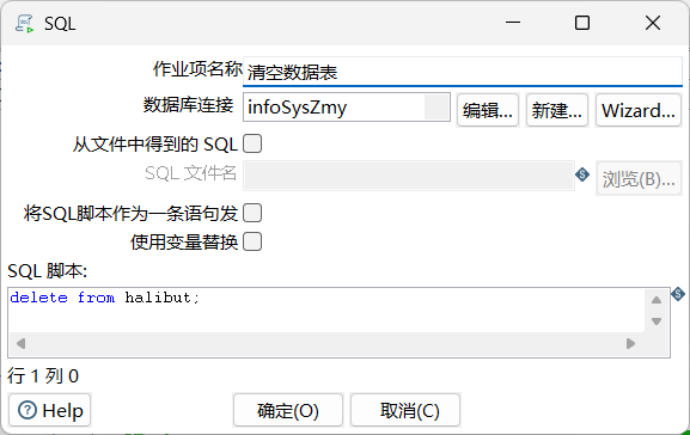
3.4.3. 清空数据表
为了防止重复执行时数据库中相应表不为空,可能导致执行出错或数据冗余堆叠,因此在每次转换、加载数据前都需要清空数据库中的相应表格。
步骤:核心对象/脚本/SQL
SQL语句:delete from halibut;
3.4.4. 格式转换
步骤:核心对象/通用/转换
其中Transformation设定为后续新建的转换文件。
该部分主要是将halibut.log文件中的数据格式转换为MySQL数据库的halibut表设置的格式,以便于将日志数据导入到数据库中。
在Spoon中新建转换transform,其总体流程设计如下:

然后将transform的文件路径链接到task1作业的格式转换&写入步骤中。
3.4.4.1. 文本文件输入
步骤:核心对象/输入/文本文件输入
这个部分主要是将halibut.log以文本文件读取后,按照一定的格式对其中每一行的内容进行拆分,然后再进行后续操作。
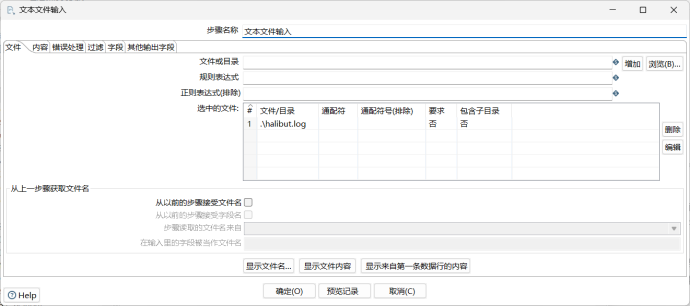
经分析发现,halibut.log文件中每一行各字段信息之间用空格相互分隔,但是关于时间戳部分的信息存在一种特性,即具体日期始终以两个字符位进行显示:若日期为17日,则表示为17,;若日期为8日,则在数字8的前面会存在一个空格。
我猜测该特性本意是为了规范化时间戳的表达,确保时间戳始终为24个字符,但是这就会导致,如果以单空格作为分隔符来拆分字段,部分记录会存在字段被错位读取的情况,即本该是日期的字段读取为null,剩余字段均向后延移了一位。
为了解决这一问题,我想到两种思路:
第一种是:首先在读取文件时以双空格作为分隔符,将记录拆分为part1和part2,然后再将拆分后的字符串以单空格进行连接,即可得到每个字段之间都是严格按照单空格进行分隔的记录,后续再按照单空格拆分字符串即可得到所有字段;
第二种是:读取1~24字符为date字段,读取25及后续字符为content字段,之后再对content字段进行拆解,以获取全部目标字段值。
此处我选择第一种方法进行展示,在实验分析部分会对两种方法的结果进行对比分析。
3.4.4.2. 修整字符串
步骤:核心对象/转换/Concat fields
该步骤是将前一步分割得到的part1和part2字段按照单空格的方式进行连接,以获取规范化字符串字段content。在Concat fields步骤组件中进行如下操作,设置Spectator为单个空格:
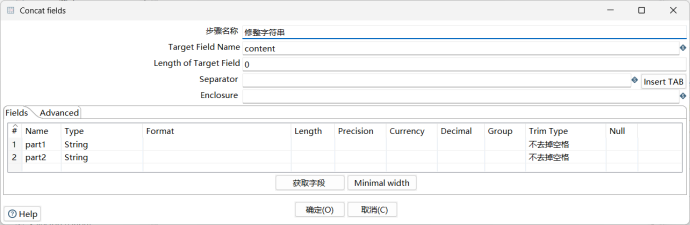
3.4.4.3. 拆分字段
步骤:核心对象/转换/拆分字段
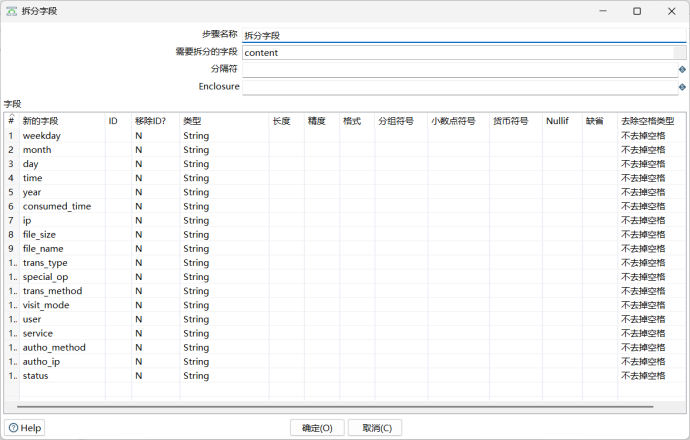
该步骤是将前一步获取到的规范化字段content以单空格为分隔,拆解为18个信息字段,其中前五个字段为date字段的子字段,需要在下一步进行合并,其他字段均为需要写入数据库的目标字段。在拆分字段步骤组件中进行如下操作,设置分隔符为单个空格:
3.4.4.4. 连接date字段
步骤:核心对象/转换/Concat fields
由于本应属于date字段的内容在上一步按照单空格的方式读取时,被分别读取为了5个字段。因此在这一步要对五个字符串进行拼接,分隔符还是单空格,拼接后的目标字段为date。
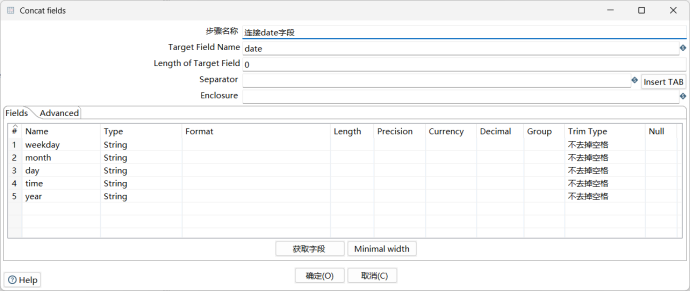
3.4.4.5. 定义输出
步骤:核心对象/输出/插入 / 更新
从上述步骤获取的字段里选择我们需要的14个字段(在4.4.3中获取的13个目标字段以及4.4.4中合并出来的date字段),写入数据库中。在插入/更新步骤组件中进行如下操作,数据库连接到infoSysZmy,目标表为halibut。
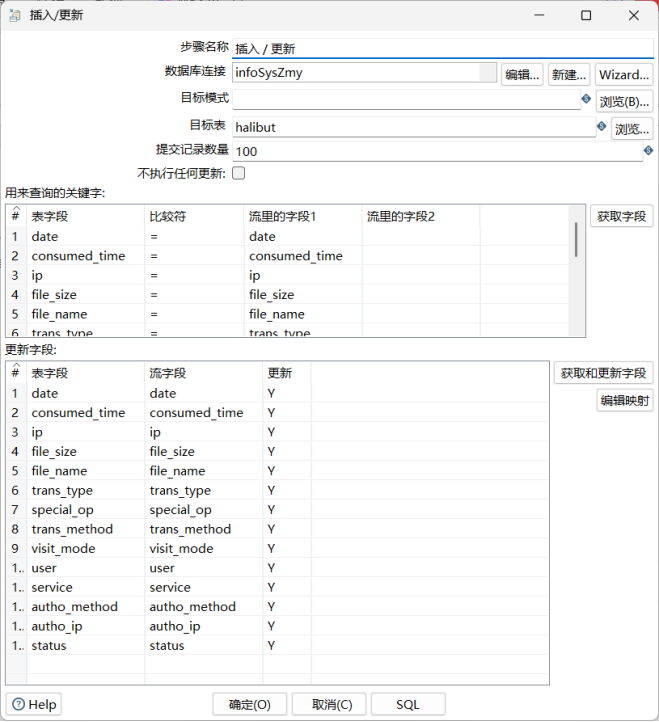
3.4.5. 执行转换过程
上述流程设计完成后,即可执行作业。点击Spoon内作业task1左上角的执行按钮,控制台打印如下信息,表明执行成功:

3.4.6. 检查数据库表
在MySQL Command Line Client中输入SELECT * FROM halibut;查看halibut表中的数据,与halibut.log中内容对比,内容一致且记录数相同,无数据损失,说明作业成功。
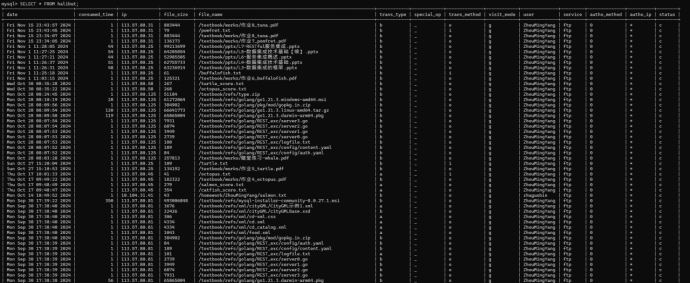
3.4.7. 导出数据库表
由于Kettle 9提供了快捷导出SQL文件的步骤组件,故此处选择在Spoon中完成导出SQL的任务。像前面的transform转换配置一样,在task1中加入一个转换步骤导出SQL,同时新建转换export并链接到该步骤。
export中流程设计如下:
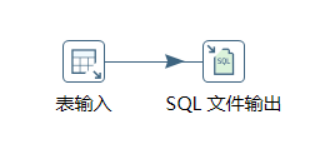
3.4.7.1. 表输入
步骤:核心对象/输入/表输入
数据库连接到infoSysZmy,设置的SQL语句为SELECT * FROM halibut;。这一步是从已经更新了数据的infoSysZmy数据库中获取halibut表中的所有记录。
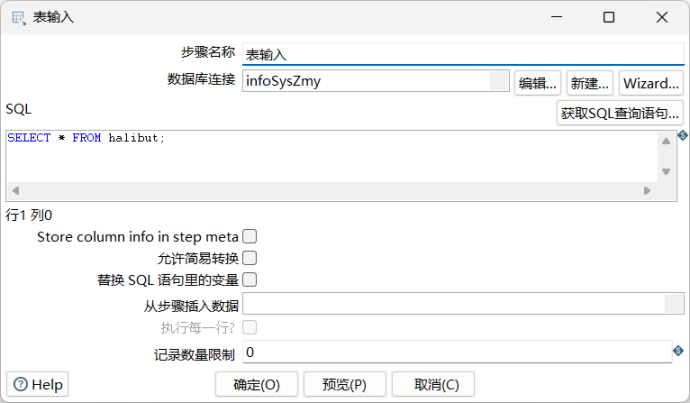
3.4.7.2. SQL文件输出
步骤:核心对象/输出/SQL文件输出
将获取到的数据输出SQL文件,需要作为作业的一部分提交。和上面一样,数据库连接到infoSysZmy,目标表选择halibut,为了便于导入test数据库,选中增加创建表语句选项。为了SQL工整美观,选中每个语句另起一行选项。最后设置好文件名,即可完成输出设置。再次运行整个作业流程,就可以正确导出SQL文件了。
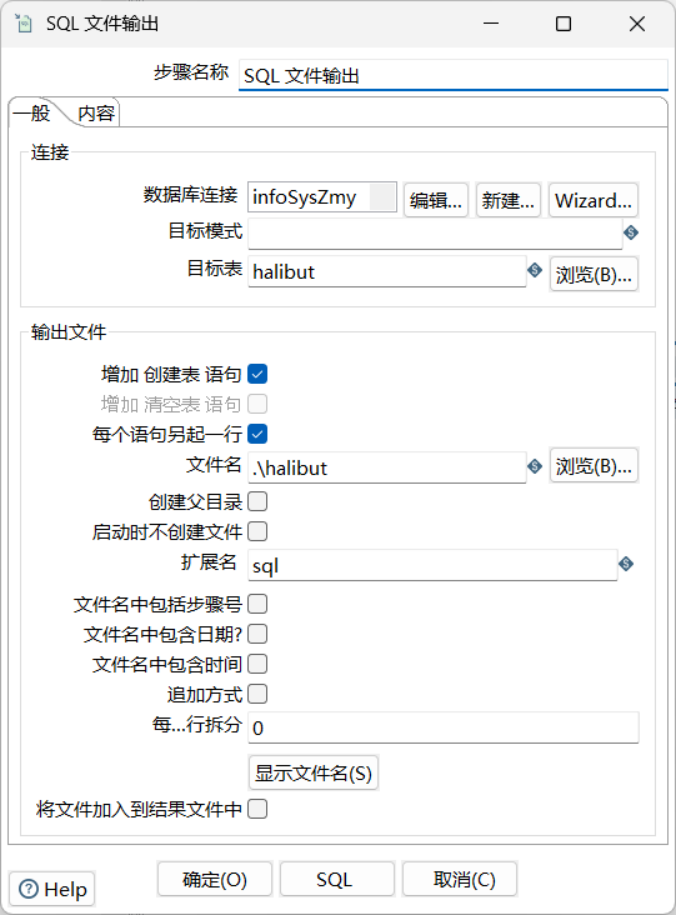
3.4.8. 导入测试数据库
在MySQL Command Line Client中输入CREATE DATABASE test;建立测试数据库。

在task1中加入两个SQL脚本步骤,第一个用于检验test数据库中halibut表的存在性,第二个用于执行前面输出的SQL文件,将数据导入到test数据库。
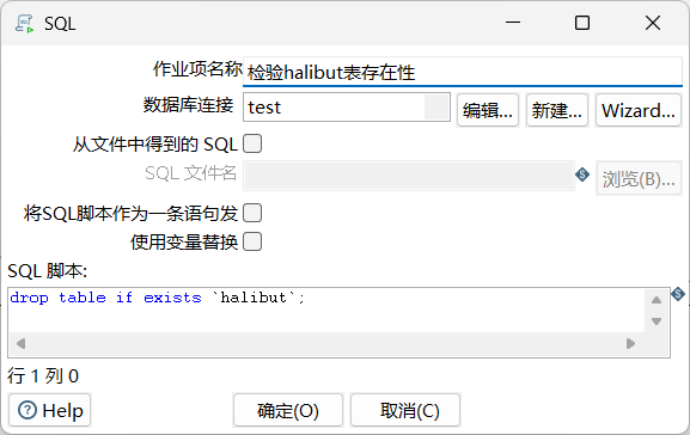
3.4.8.1 检验halibut表存在性
SQL脚本:drop table if exists `halibut`;
该语句意为,检验test数据库中是否存在halibut表,若存在则删除。这是为了避免halibut表存在而导致数据导入失败。
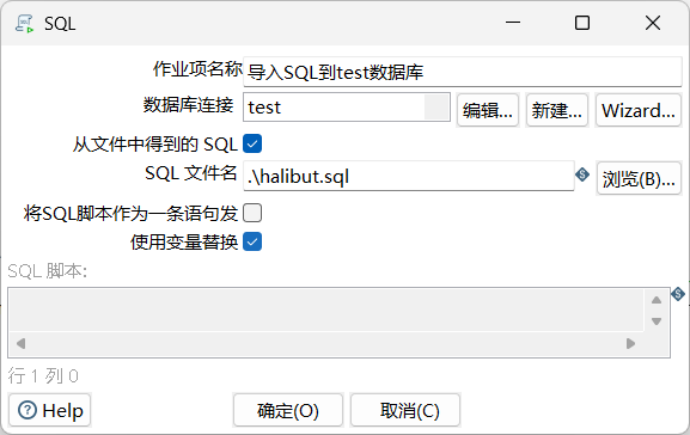
3.4.8.2. 导入SQL到test数据库
选中从文件中得到的SQL选项,并在SQL文件名设置SQL文件路径,随后再次运行作业流程,即可自动执行相应SQL文件中的命令,完成数据的导入。
3.4.8.3. 在test数据库中检查结果
在MySQL Command Line Client中输入USE test;切换到test数据库,然后输入SELECT * FROM halibut;查看结果,出现如下结果,并与infoSysZmy数据库中的选择结果对比后,确认数据完整且一致,至此实验一成功完成。

4. 实验分析
前面提到,有两种方法从日志文件获取各种字段并进行格式转换:
- 一种是在读取文件时以双空格作为分隔符,将记录拆分为part1和part2,然后再将拆分后的字符串以单空格进行连接,即可得到每个字段之间都是严格按照单空格进行分隔的记录,后续再按照单空格拆分字符串即可得到所有字段;
- 另一种是读取1~24字符为date字段,读取25及后续字符为content字段,之后再对content字段进行拆解,以获取全部目标字段值。
第一种方法的优点是可以得到单空格分隔的数据,更容易获取更精细的数据(如将date字段拆分到具体的年、月、日、星期、时刻),但相较于第二种方法会多出拆分与合并这两个步骤。
第二种方法的优点是可以省去两个步骤,且获得到的date字段始终为24个字符的固定长度,适合对date字段有定长要求的场景使用。
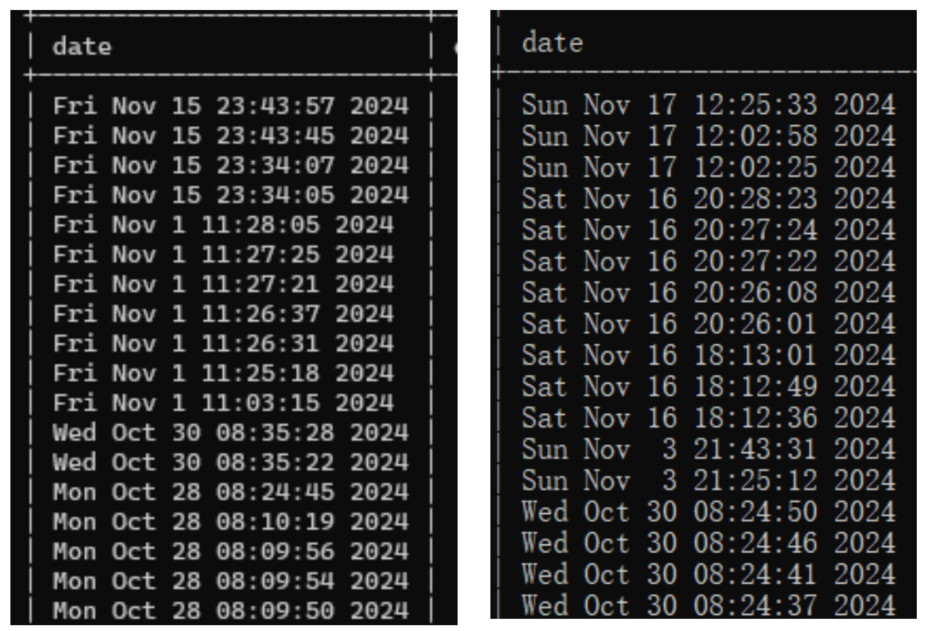
以下是两种方法各自得到的数据库数据对比(左侧为第一种方法得到的date字段,右侧为第二种方法得到的date字段),不难看出,当遇到日期为单个数字的记录时,第一种方法会消除冗余空格并规范化排布字符串,而第二种方法会保留空格并格式化排布字符串。
5. 实验心得
通过这次实验,我学习到了如何设计和实施数据集成流程,以及如何确保数据的准确性和完整性。通过实操,我体会到了将理论知识应用于实践的重要性。在实际操作中,我遇到了各种预料之外的问题,例如数据读取不全、数据排布错误、服务器连接失败等多种问题。这些问题促使我不断学习和探索,从而提高了我的问题解决能力。同时,我也深刻认识到了细节的重要性,数据处理中的任何小错误都可能导致整个流程的失败。
总的来说,这次实验不仅提升了我的技术技能,也让我对数据集成有了更深的认识,为未来的学习和工作打下更坚实的基础。
最后,感谢老师的悉心指导与经验传授,本次实验让我受益匪浅。


















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











