




目录
1. 目的
目标检测跟踪计数(Object Detection, Tracking and Counting )的任务是找出图像中所有感兴趣的目标,并确定其类别、位置和数量,是计算机视觉领域的核心问题之一。因各类目标有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。通过本实验,了解基于深度学习目标检测跟踪计数基本原理、特征、结构以及主流模型的应用,掌握模型应用的工作方法与流程。
2. 内容
使用 YOLOv11 深度学习模型进行校内道路交通场景常见典型目标检测跟踪计数。
3. 条件
完成本项实验的基本条件如下:
1、PC 机(笔记本或台式计算机,配置 GPU 显卡可显著提升实验效率);
2、图像编辑工具软件;
3、撰写实验报告的字处理应用软件。
4. 参考资料
- 《空间智能计算与服务》课程教材、参考书、PPT 课件
- Ultralytics YOLOv11 Docs,https://docs.ultralytics.com/models/yolo11/
5. 数据描述与分析
本实验用到的数据主要是同学们自己采集的交通图像数据,以及通过labelImg工具标注锚框后得到的YOLO label描述文件。
实验开始前,老师让每位同学分别采集了15张以上的校内道路交通场景照片,上传到QQ群共享文件夹SICISP2025DataSet,每张照片中可见人员、小汽车、电瓶车、自行车等四类要素中的一类或多类。
采集完成后,每位同学自行使用labelImg工具,对照片中的四类要素按照ebike、car、person、bicycle的顺序进行标注,再将得到的标注数据txt文件上传到QQ群共享文件夹SICISP2025YoloLabel。
经过这样的众源数据采集过程,每位同学可以下载到实验数据如下:
- SICISP2025DataSet:交通图像数据集,包含几百张同学们共同采集的校内道路交通场景照片;
- SICISP2025YoloLabel:图像数据集对应的YOLO标注集,包含与照片数量相等的txt描述文件,每个文件包含若干行数据,对应照片里的若干个锚框。每一行数据描述了一个锚框的属性,形如“class_id x y w h”,其中class_id表示类别的id编号,x表示目标的中心点 x 坐标(横向)/图片总宽度,y表示目标的中心的 y 坐标(纵向)/图片总高度,w表示目标框的宽带/图片总宽度,h表示目标框的高度/图片总高度。
6. 核心算法与工具
本次实验主要用到的工具有:
- labelImg图像标注工具;
- YOLOv11深度学习模型;
- BoT-SORT目标跟踪器;
- AutoDL云算力租借平台,用于租借在线GPU进行模型训练。
7. 步骤
7.1. 图片采集
在课程开始之前,老师布置了一项数据采集任务,要求拍摄校内道路交通场景照片,每张照片中可见人员、小汽车、电瓶车、自行车这四类要素中的一类或多类,照片大小不超过 10M,数量不少于 15 张且须涵盖全部四类要素,保存为 JPG 格式文件,文件名形式为 “< 学号 > - < 照片序号 > .jpg”。同时,还需拍摄一段上述场景的视频,时长在 25 至 30 秒之间,格式为 MP4。拍摄时要注意多点位、多视角、多焦距、多光照条件,避免画面雷同、主题要素过多造成杂乱以及要素在画面中占比过小,最后将拍摄完成的照片和视频上传至群共享文件夹 SICISP2025DataSet。

7.2. 图片标注
为了能让YOLOv11理解我们拍摄的照片中包含的目标对象,还需要使用图片标注工具在图片上标出目标框。
这里我们使用labelImg工具进行标注。
在Anaconda中新建一个3.9版本的python环境,命名为SICISPyolo:
![]()
完成环境创建后,激活该环境:
![]()
然后安装labelImg工具所需要的依赖(pyQt5):
![]()
然后安装labelImg工具:
![]()
最后直接输入labelImg就可以启动了:
![]()
进入labelImg工具,点击左侧的“Open Dir”打开拍摄的照片的存放目录,点击“Change Save Dir”选择标注文件的保存目录,点击“Create RectBox”可以在图中拖动新增一个标注框,标注好的锚框会在右侧列表显示,标注完毕后,要点击左侧保存格式按键,调整为“yolo”,然后再点击“Save”保存标注文件。点击“Prev Image”和“Next Image”跳转到上一张或下一张图像,跳转前记得保存当前图像的标注信息。
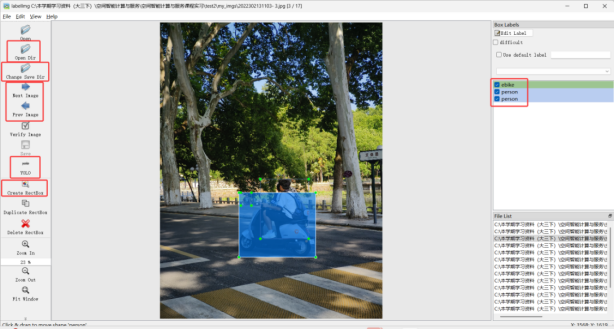
个人采集的全部照片都标注完毕后,便可关闭labelImg工具,然后将标注文件上传到QQ群SICISP2025YoloLabel共享文件夹。
7.3. 数据整理
由于众源数据采集是一种较不稳定的采集方式,在数据收集过程中难免会因为人员粗心、网络异常等多方面原因导致部分数据缺失或混乱,进而导致数据不能直接用于训练,所以需要对数据进行清洗整理。
本次实验提供的数据集中,可能由于部分同学的粗心,导致数据存在以下两种问题:
第一种是数据无法配对,上传了图片但是没有上传对应的label文件,或是上传了label文件但没上传对应图片,这样的数据就无法使用,应该剔除;
第二种是标注数据存在异常,例如今年同学采集的数据集中有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











