 Spark Shell入门:WordCount实战
Spark Shell入门:WordCount实战







 本文介绍了如何使用Spark Shell进行交互式编程,包括启动Spark Shell、编写并执行WordCount程序,以及解决启动过程中遇到的问题。详细步骤涵盖从启动HDFS、上传文件,到在shell中编写和运行程序,最后在IDEA中实现相同功能。同时,文章还讨论了一个Hive配置警告的解决方案。
本文介绍了如何使用Spark Shell进行交互式编程,包括启动Spark Shell、编写并执行WordCount程序,以及解决启动过程中遇到的问题。详细步骤涵盖从启动HDFS、上传文件,到在shell中编写和运行程序,最后在IDEA中实现相同功能。同时,文章还讨论了一个Hive配置警告的解决方案。
Spark Core:第一章 spark shell
文章目录
—>Spark知识点总结导航<—
一、关于spark-shell
spark-shell是spark自带的交互式shell程序,方便用户进行交互式编程,用户可以在该命令行下用scala编写spark程序。
二、启动spark-shell
开启HDFS和spark集群

~/software/spark/bin/spark-shell
(如果不成功请参考文末的Q1)

- 注意:
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的cluster模式,如果spark是单节点,并且没有指定slave文件,这个时候如果打开spark-shell 默认是local模式 - Local模式是master和worker在同同一进程内
- Cluster模式是master和worker在不同进程内
三、spark-shell中编写WordCount程序
1. 启动HDFS

2. 上传文件到HDFS


3. spark-shell中编写程序
sc.textFile("hdfs://Cloud00:9000/RELEASE").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://Cloud00:9000/out")

- 说明:
- sc是SparkContext对象,该对象时提交spark程序的入口
- textFile(hdfs://Cloud01:9000/RELEASE)是hdfs中读取数据
- flatMap(_.split(" "))先map再压平
- map((_,1))将单词和1构成元组
- reduceByKey(+)按照key进行reduce,并将value累加
- saveAsTextFile(“hdfs:// Cloud01:9000/out”)将结果写入到hdfs中
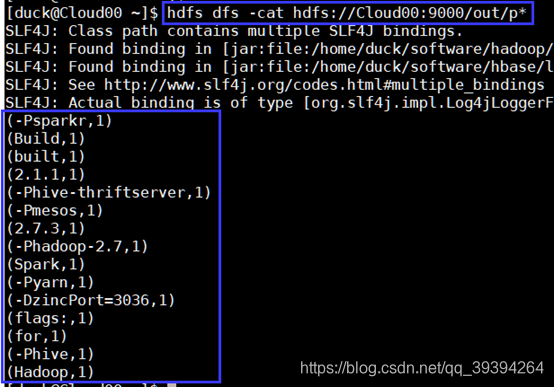
4. hdfs命令查看结果
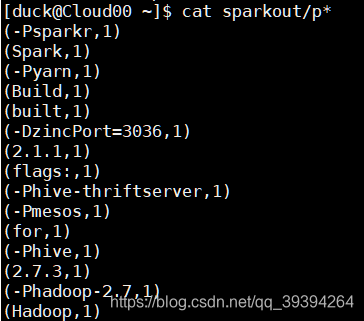
hdfs dfs -cat hdfs://Cloud00:9000/out/p*
四、IDEA中编写WordCount程序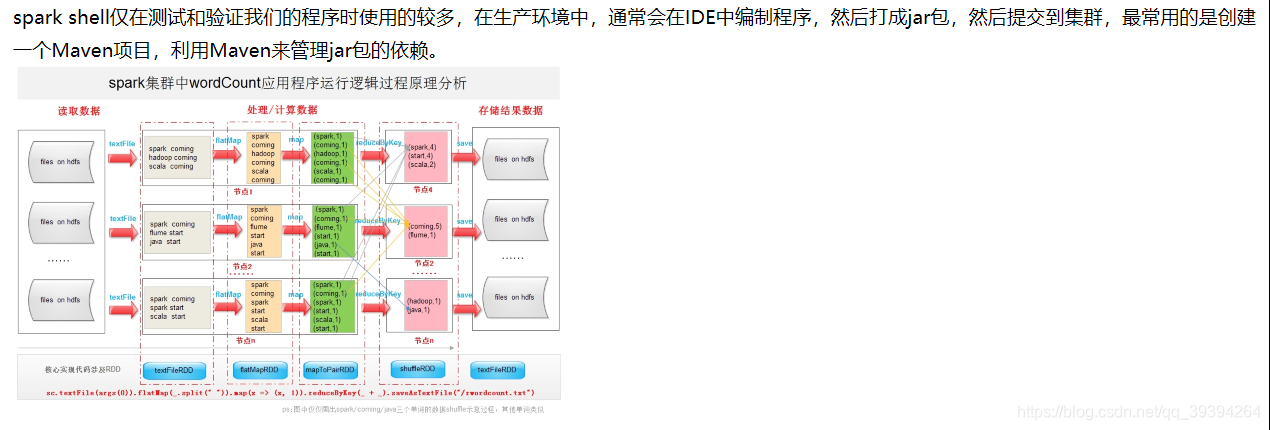
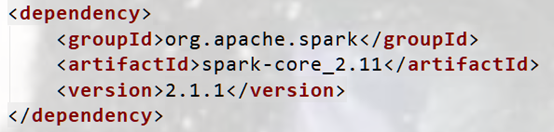
1. 配置maven配置文件
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
2. 编写程序
package com.spark.core
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("wordcount")
val sc = new SparkContext(conf)
//读取输入文件
val line = sc.textFile("hdfs://Cloud00:9000/RELEASE")
//按空格分割
val value = line.flatMap(_.split(" "))
//单词从1开始计数
val word = value.map((_, 1))
//对结果聚合
val count = word.reduceByKey(_ + _)
//保存输出文件格式和路径
count.saveAsTextFile("/home/duck/sparkout")
}
}
3. 打包上传
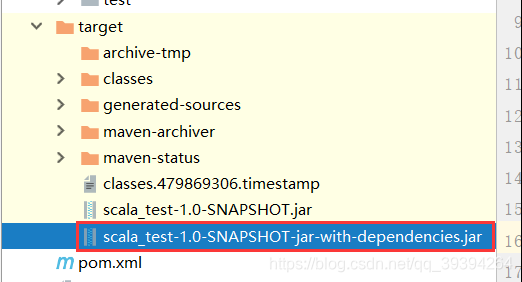
4. 启动HDFS和spark集群
5. spark命令提交任务
bin/spark-submit \
--class com.spark.core.WordCount \
/home/duck/Lesson-1.0-SNAPSHOT.jar

6. 查看程序执行结果
五、出现的问题
Q1: WARN HiveConf: HiveConf of name hive.server2.thrift.client.user does not exist
(1) 描述
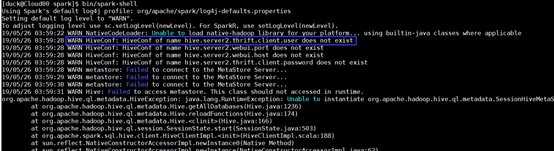
(2) 原因:找不到元数据路径
(3) 解决:
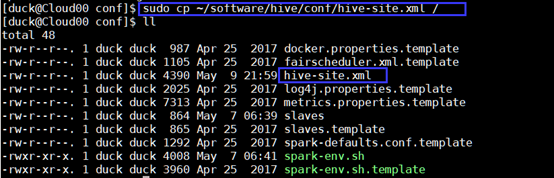
拷贝hive的配置文件hive-site.xml到spark/conf下
sudo cp ~/software/hive/conf/hive-site.xml /
开启元数据监听
hive --service metastore&

















 7797
7797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









