






 本文介绍了一系列用于提升ResNet网络性能的技巧,包括训练程序优化、有效训练策略、模型结构调整等,成功将ResNet-50在ImageNet上的准确率从75.3%提升至79.29%。
本文介绍了一系列用于提升ResNet网络性能的技巧,包括训练程序优化、有效训练策略、模型结构调整等,成功将ResNet-50在ImageNet上的准确率从75.3%提升至79.29%。
论文笔记:Bag of Tricks for Image Classification with Convolutional Neural Networks and a new ResNet.
My Github:(https://github.com/Linchunhui/Tricks-and-new-ResNet)
A new ResNet-D is here.
And here is the paper.
Index
论文笔记
论文笔记
我们在训练网络的时候经常会发现一模一样的网络总是达不到人家的效果,主要是因为他们还有一些trick。
这篇文章主要就是列举了一些tricks以及对ResNet网络结构进行了一些调整,就将ResNet-50在ImageNet
的结果从75.3% 提升到了 79.29% ,甚至超过了SE-ResNet-50的 76.71% 以及DenseNet-201的 79.29% 。
结果如下:
![]](https://i-blog.csdnimg.cn/blog_migrate/cbd8a8e4e36d8d045576178ac089999a.png)
1.训练程序
1.1Baseline
训练时
- 随机抽取一幅图像,并且将[0,255]原像素值转为32位浮点数;
- 以[3/4,4/3]长宽比例随机裁剪一个矩形区域,再以[8%,100%]随机采样,最后resize为224x224的正方形;
- 0.5的概率随机水平翻转;
- 比例色调、饱和度和亮度的系数从[0:6;1:4];
- 增加正态分布的PCA噪声;
- 标准化RGB通道,通过分别减去均值[123.68,116.779,103.939],再除以[58.393,57.12,57.375]。
测试时
- 保持长宽比例,将短边resize成256,再中心裁剪出224x224区域;
- 同上的标准化过程。
初始化
- 卷积和全连接层
weights的初始化都基于Xavier algorithm,就是在[-a,a]均匀取随机值。
a的值为
a=sqrt(6/(d_in+d_out))
其中d_in,d_out分别为该层的输入输出通道数。
biases初始化为0;
BN层alpha和belta分别初始化为1和0;
NAG优化,学习率初始化为0.1,每30个epochs除以10,总共12epochs。
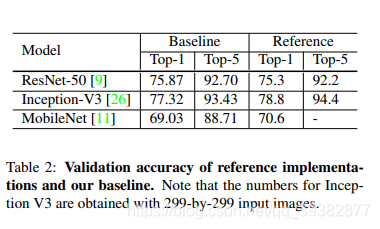
1.2Results
用ISLVR2012数据集,训练集130万共1000类,
结果如下
2.有效训练
2.1大规模batch训练
Mini-batch SGD算法中如果batch size过大的话,将会影响收敛速度,从而减少精度,但是最近许多工作解决了这一问题。
2.1.1线性降低学习率
在Mini-batch SGD算法中,梯度下降是一个随机过程,增大batch size不会影响梯度,但是会减少方差,也就是说减少了噪声,
起到一定正则化效果。
因此当batch size为256是初始学习率为0.1,增大为b时,初始学习率设为
0.1 * b/256
2.1.2学习率热身
因为一开始参数都是随机的,因此大的学习率会导致训练不稳定。
因此提出了热身阶段,也就是先用一些数据 m batches例如5个epochs来使得学习率从0升到初始学习率,
比如第i个batch,学习率为 i*u/m,u是初始学习率。
2.1.3Alpha初始化为0
将BN的alpha也初始化为0,这样只有residual blocks会返回他的输入,初始阶段会更容易训练。
2.1.4Bias不衰减
训练的时候会采用L1、L2正则化使得权值衰减到接近0来避免过拟合。
但是大的batch size只对weights正则化效果更好。
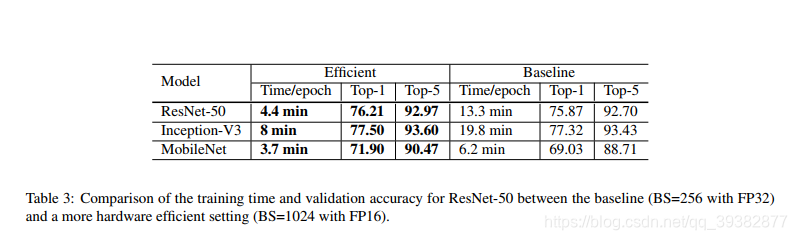
2.2低精度训练
用float16代替float32进行运算
2.3Results
结果如下
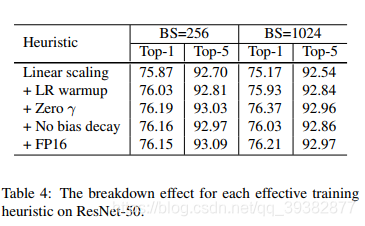
消融实验
3.模型调整
在原始的ResNet的基础上进行了略微修改
3.1模型微调
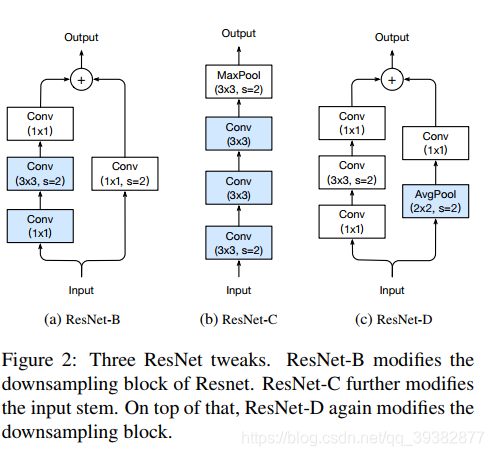
原始的ResNet如下,
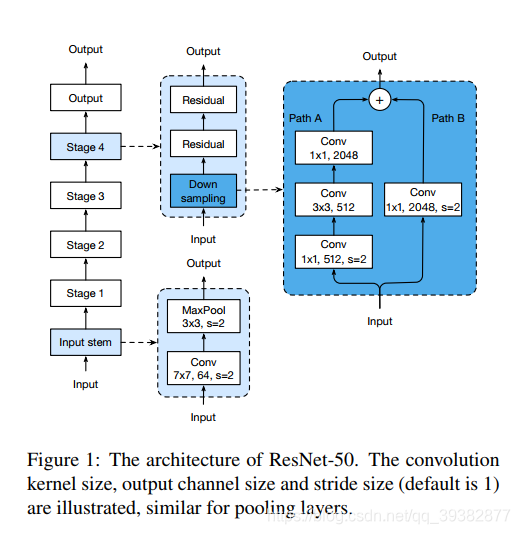
- ResNet Stage的下采样的第一个block先用了stride为2的1x1卷积,这会丢失原来
feature map3/4的信息,
从而降低了精度,通过修改,使得1x1卷积步长为1,后面3x3卷积步长为2,新的结构为ResNet-B;
with tf.variable_scope(scope):
net = slim.conv2d(input_x, num_outputs=base_channel, kernel_size=[1, 1], stride=1,
padding="VALID", biases_initializer=None, data_format=DATA_FORMAT,
scope='conv0')
net = tf.pad(net, paddings=[[0, 0], [1, 1], [1, 1], [0, 0]])
net = slim.conv2d(net, num_outputs=base_channel, kernel_size=[3, 3], stride=stride,
padding="VALID", biases_initializer=None, data_format=DATA_FORMAT,
scope='conv1')
net = slim.conv2d(net, num_outputs=base_channel * 4, kernel_size=[1, 1], stride=1,
padding="VALID", biases_initializer=None, data_format=DATA_FORMAT,
activation_fn=None, scope='conv2')
- ResNet一开始的7x7的卷积可以用3个3x3卷积代替,这在inception中就已经用到了,能够获得同样的感受野,但是减少了参数,
加深了深度,新的结构为ResNet-C;
with tf.variable_scope(scope):
net = tf.pad(net, paddings=[[0, 0], [1, 1], [1, 1], [0, 0]])
net = slim.conv2d(net, num_outputs=input_channel, kernel_size=[3, 3], stride=2,
padding="VALID", biases_initializer=None, data_format=DATA_FORMAT,
scope='conv0')
net = tf.pad(net, paddings=[[0, 0], [1, 1], [1, 1], [0, 0]])
net = slim.conv2d(net, num_outputs=input_channel, kernel_size=[3, 3], stride=1,
padding="VALID", biases_initializer=None, data_format=DATA_FORMAT,
scope='conv1')
net = tf.pad(net, paddings=[[0, 0], [1, 1], [1, 1], [0, 0]])
net = slim.conv2d(net, num_outputs=input_channel*2, kernel_size=[3, 3], stride=1,
padding="VALID", biases_initializer=None, data_format=DATA_FORMAT,
scope='conv2')
net = tf.pad(net, paddings=[[0, 0], [1, 1], [1, 1], [0, 0]])
net = slim.max_pool2d(net, kernel_size=[3, 3], stride=2, padding="VALID", data_format=DATA_FORMAT)
- ResNet 的
shortcut在降采样的时候也用了步长为2的1x1卷积,因此也丢失了3/4的信息,相应的修改是在1x1卷积之前接一
个avg pooling来降采样,使得1x1卷积的步长仍为1,新的结构为ResNet-D;
shortcut = slim.avg_pool2d(input_x, kernel_size=[stride, stride], stride=stride, padding="SAME",
data_format=DATA_FORMAT)
shortcut = slim.conv2d(shortcut, num_outputs=base_channel*4, kernel_size=[1, 1],
stride=1, padding="VALID", biases_initializer=None, data_format=DATA_FORMAT,
activation_fn=None,
scope='shortcut')
新的ResNet图如下,代码在ResNet-D.py文件中。
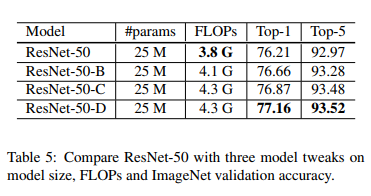
3.2Results
4.训练改进
4.1学习率余弦衰减
batch t对于总共的batch T的学习率为,
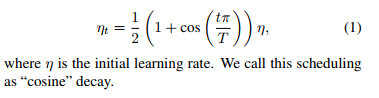
4.2标签平滑
见代码
label_smoothing = 0.1
batch_labels = (1.0-label_smoothing)*batch_labels+label_smoothing/N_CLASSES
比如原来三类的one-hot变量为[0,1,0],平滑后就变成了[0.03,0.9,0.03],
相当于原来是狄拉克函数,不是1就是0,比较尖锐,比较难学习,平滑之后就更容易学习了。
4.3知识蒸馏
这个之前是在模型压缩的时候看到的,就是用一个大的教师网络来指导小型网络的学习,
例如这里用ResNet-152来指导ResNet-50学习,有兴趣的可以看下原文。
具体就是如图
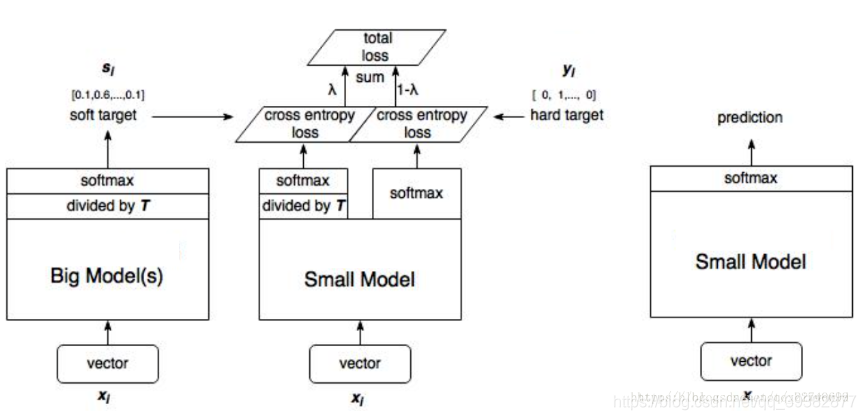
步骤:
- 训练大模型:先用hard target,也就是正常的label训练大模型;
- 计算soft target:利用训练好的大模型来计算soft target。也就是大模型“软化后”再经过softmax的output;
- 训练小模型,在小模型的基础上再加一个额外的soft target的loss function,通过lambda来调节两个loss functions的比重。
- 预测时,将训练好的小模型按常规方式(右图)使用。
4.4混合训练
就是随机挑选两张图,随即生成一个[0,1]的参数来将两张图加起来,
这样新的样本就变成了,具体训练是选择lambda为0.2
x=lambda*x1+(1-lambda)x2
y=lambda*x1+(1-lambda)y2
4.5Results
结果如下
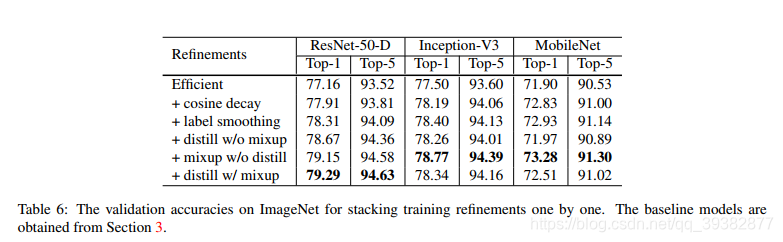
5.迁移学习
证明了这些tricks以及微调的网络对于目标检测以及图像分割也是有作用的。
结果如下
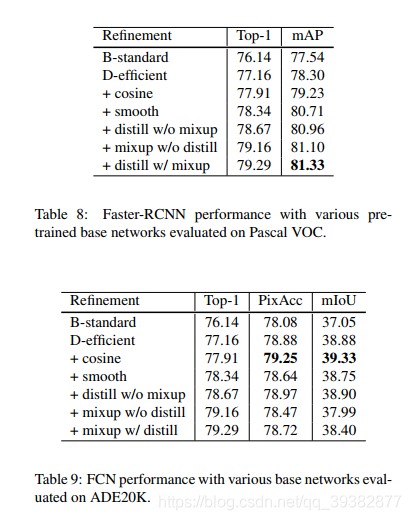

















 3388
3388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









