







本文章的内容和知识为作者学习期间总结且部分内容借助AI理解,可能存在一定错误与误区,期待各位读者指正。
本文章中的部分例子仅用于生动解释相关概念,切勿结合实际过度解读。
语雀链接:《无监督学习》
部分内容来源:B站:李哥考研
目前内容仍处于更新阶段,部分章节存在缺失内容,望读者理解
有监督学习的模型往往只能学习到我们已经知道的类别和模式,如果数据中存在一些我们尚未发现的潜在信息或者新的类别,有监督学习可能就无法很好地捕捉到这些内容。这就像我们只教给学生已知的知识,而忽略了让他们自己去探索和发现新知识的能力。
无监督学习它不需要我们事先给它提供明确的标签和指导,而是能够自己去探索数据中的奥秘。它可以自动地从大量无标签的数据中发现数据的内在结构、模式和规律,我们可以通过无监督学习来更好地提取特征。
无监督学习
无监督学习处理的是没有标签的数据。在无监督学习中,算法会尝试在数据中发现一些内在的结构、模式或规律,而不需要预先知道数据的类别或目标输出。现实中大部分数据都是没有标签的,而大量的数据标注的费用又很昂贵。
就像小孩子,当没有人教他时,他依然可以根据外观、叫声等特点,简单区分出狗和猫,尽管他不知道这两个动物具体是什么,但依然能够区分这两种不同动物。
无监督学习方法
机器学习:
降维 主成分分析(PCA)
聚类 K-Means聚类
深度学习方法:
生成对抗网络(GAN)
自监督学习:对比学习和生成式自监督是子监督下学习的两种方式
本章节主要介绍生成对抗网络与自监督学习
对比学习
正如本章开头所说,一个小孩子,当没有人教他时,他可以根据外观、叫声等特点,简单区分出狗和猫,尽管他不知道这两个动物具体是什么,但依然能够区分这两种不同动物。我们是否也可以尝试让机器也可以不需要标签,而是进行对比学习,只要让相同的类的特征离得更近,让狗和狗的特征更近,猫和猫更近。
显然我们需要更多的数据,能够让模型学习到哪些是同类型,哪些是不同类型。
数据增广
数据增广(Data Augmentation),也叫数据增强,是一种用于扩充数据集的技术,旨在通过对原始数据进行各种变换操作,创造出更多与原始数据相似但又有所不同的新数据,从而提升机器学习和深度学习模型的性能。
数据增广的目标是增加数据量以及其可变性,并将模型暴露给同一实例的不同视角。常见的数据增强技术包括裁剪、翻转、旋转、随机裁剪和颜色变换。通过生成不同的实例,对比学习可确保模型学习捕获相关信息,而不管输入数据的变化如何。显然这些增广后的数据与原数据是同一类别。
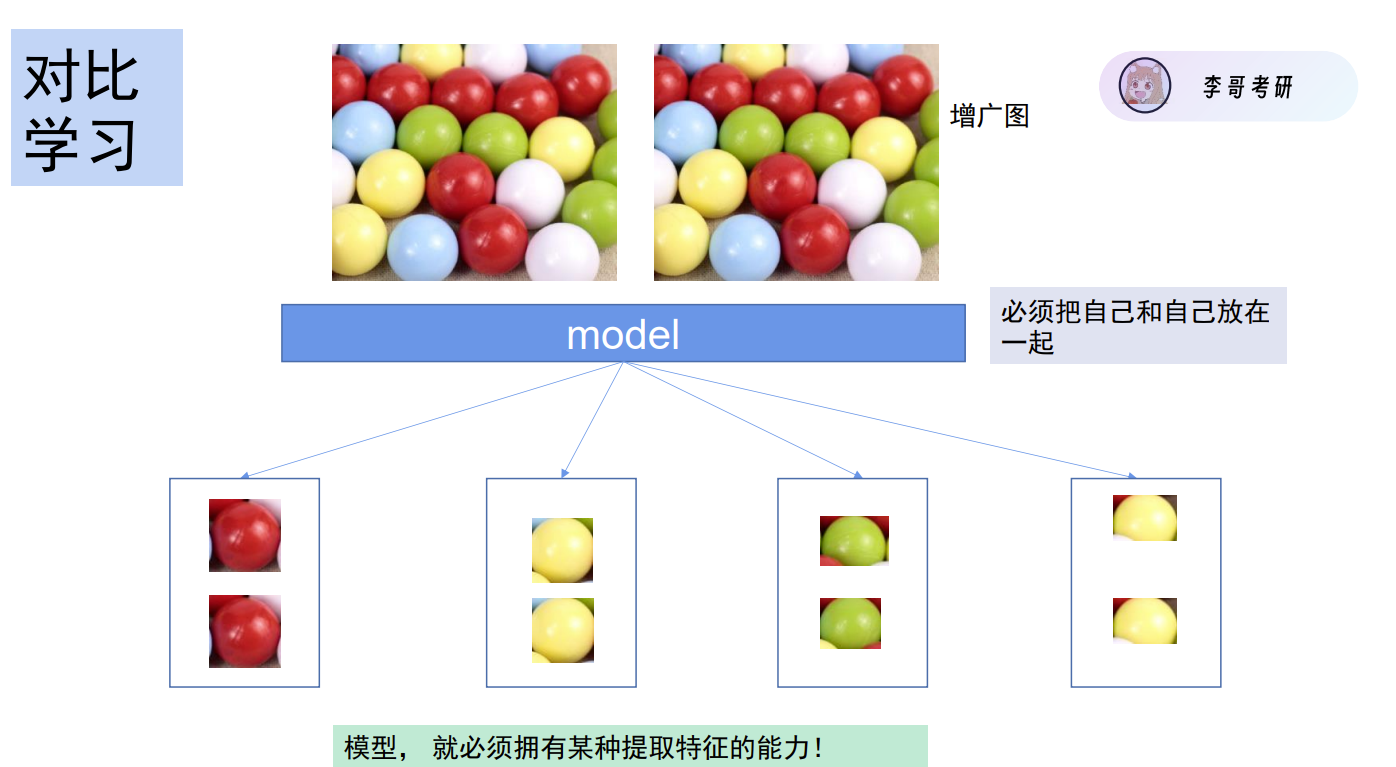
下图为simsiam的结构,其仍是由图片x,经过数据增广后得到x1和x2,作为训练模型的输入值。这里并不展开介绍
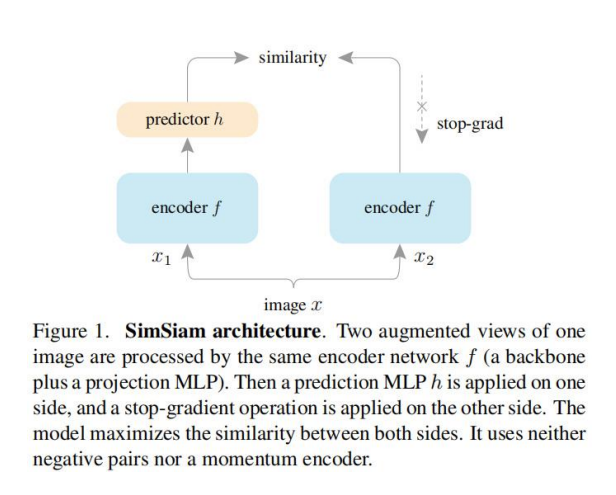
对抗生成网络(GAN)
对抗生成网络(Generative Adversarial Network,GAN)是一种深度学习模型,由生成器(Generator)和判别器(Discriminator)两部分组成,二者相互对抗训练。

在电影中,犯罪分子负责制作假钞,而警察负责检验出假钞,两者也是对抗关系。同样的,在《射雕英雄传》中,周伯通在漫漫长夜中为了打发无聊时光,遂萌生“自己左手与右手”打架的想法,继而创造出金庸武学体系中的绝顶功夫——左右互搏术。这和对抗网络有异曲同工之妙。
将这个例子带入对抗网络中,生成器就是犯罪分子制作假钞,判别器就是警察使用验钞机检验。判别器将真假两种数据,作为输入,同时判断真假。通过这种训练,判别器越来越强,同时生成器也越来越强以让判别器区分不出,因此两个同时对抗,共同进步。
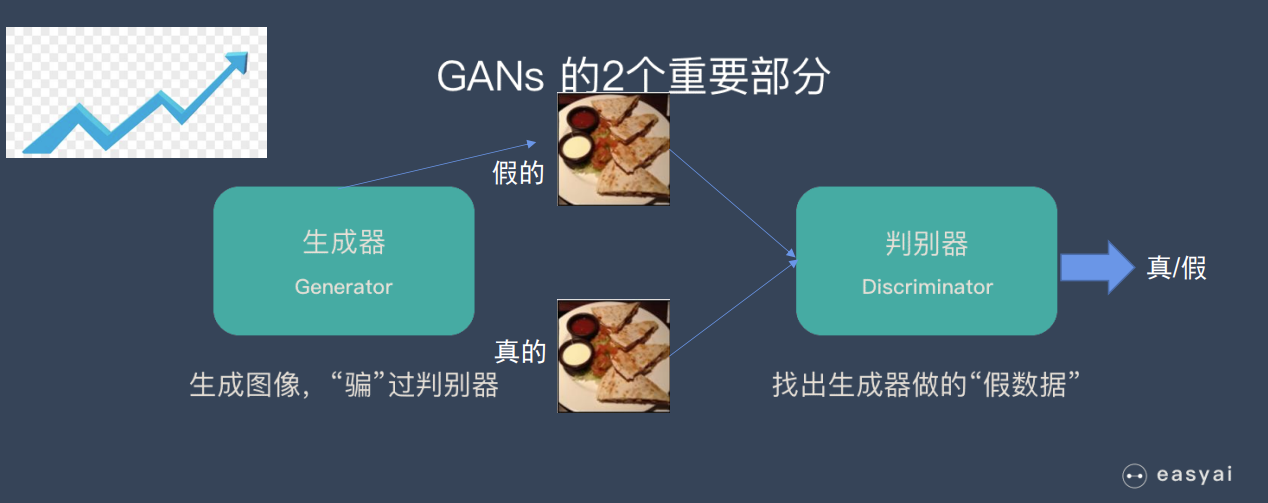
循环生成对抗网络(CycleGAN)
循环生成对抗网络(CycleGAN)是一种基于生成对抗网络(GAN)的深度学习模型,主要用于图像到图像的转换任务
例如,我们想要用一张本人的生活照,来生成一张对应的二次元风格头像,此时判别器只能确定生成的图片是不是二次元风格,没法确定是不是从你本人得来的。所以我们采用一种还原方法,根据生成的图片再还原出原始图片,要确保二者相像。
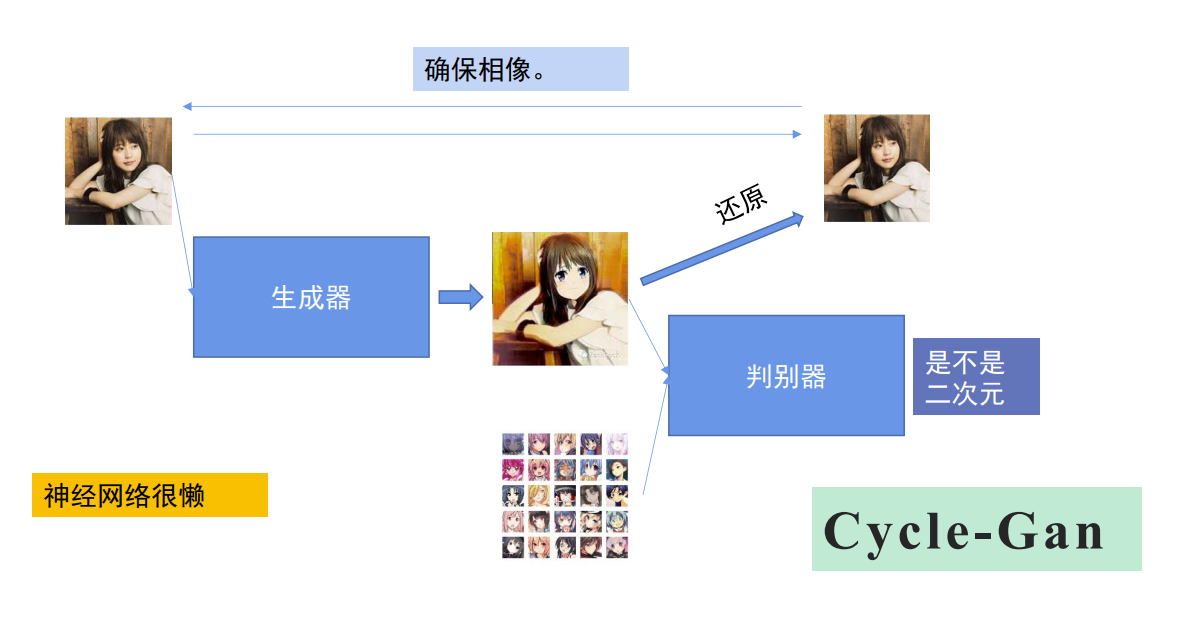
这是 CycleGAN 的关键创新点,循环一致性损失(Cycle Consistency Loss),为了避免生成器生成无意义的图像,引入循环一致性约束。即对于一张生活照A,经过生成器后,得到二次元风格头像B,此时判别器会判断B是不是二次元风格的头像,但无法确定B是不是由A生成得来。此时,我们将B再输入到另一个生成器中,得到还原图像C。循环一致性损失就是计算生活照A和还原图C的差异,模型以此作为损失值进行参数调整。
生成式自监督
生成式自监督是一种让机器自己从数据中找规律学习的方法。其核心思想是通过对数据进行某种形式的 “破坏” 或 “变换”,然后让模型去 “恢复” 或 “预测” 原始数据,以此来训练模型,使模型能够学习到数据的内在特征和模式。常见的方式有掩码语言模型(MLM)、图像补全、音频重构。
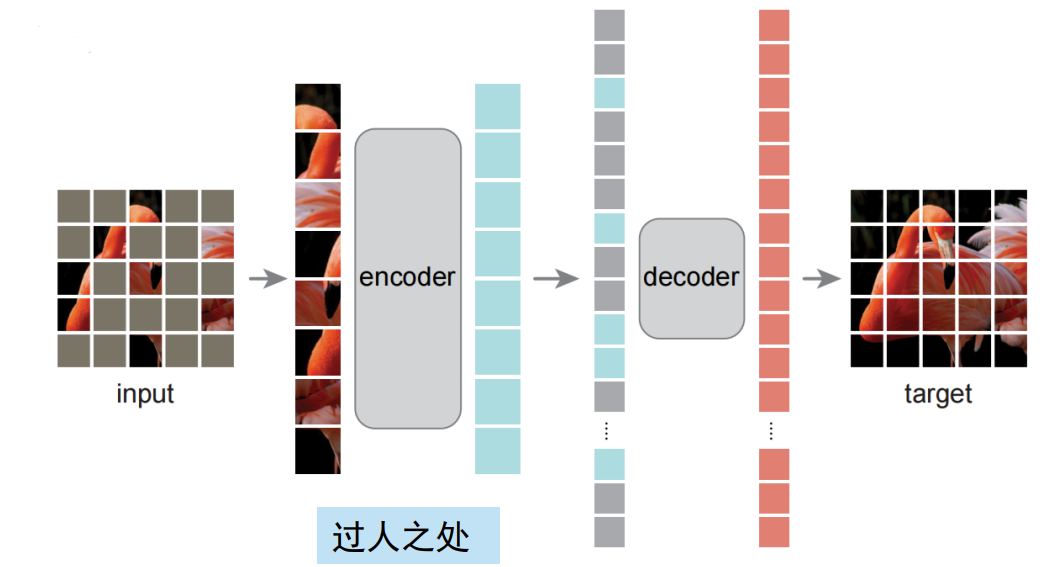
把图片拆成不同块,某些块遮住(mask),通过编码器得到特征,再通过解码器,尝试还原出原图。差异越小,模型越好,反之越差。
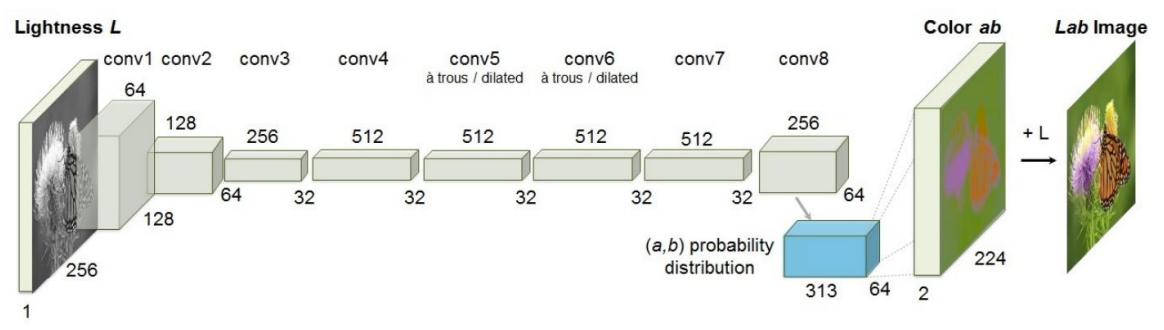
黑白作为输入x 彩色作为标签y,我们令黑白图片生成彩色图片作为预测值pred ,根据预测值pred与标签y计算loss。

下图为图像处理的模型结构
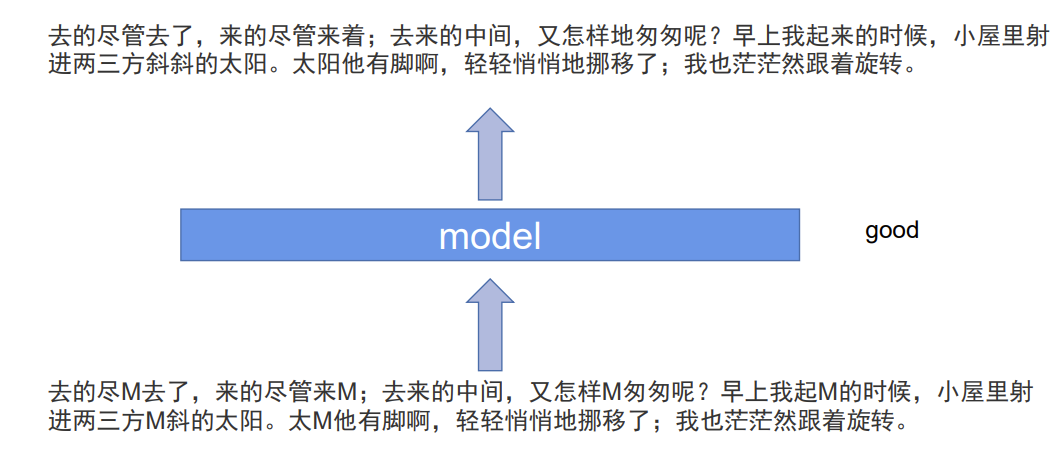
同样的,文字可以进行自监督训练
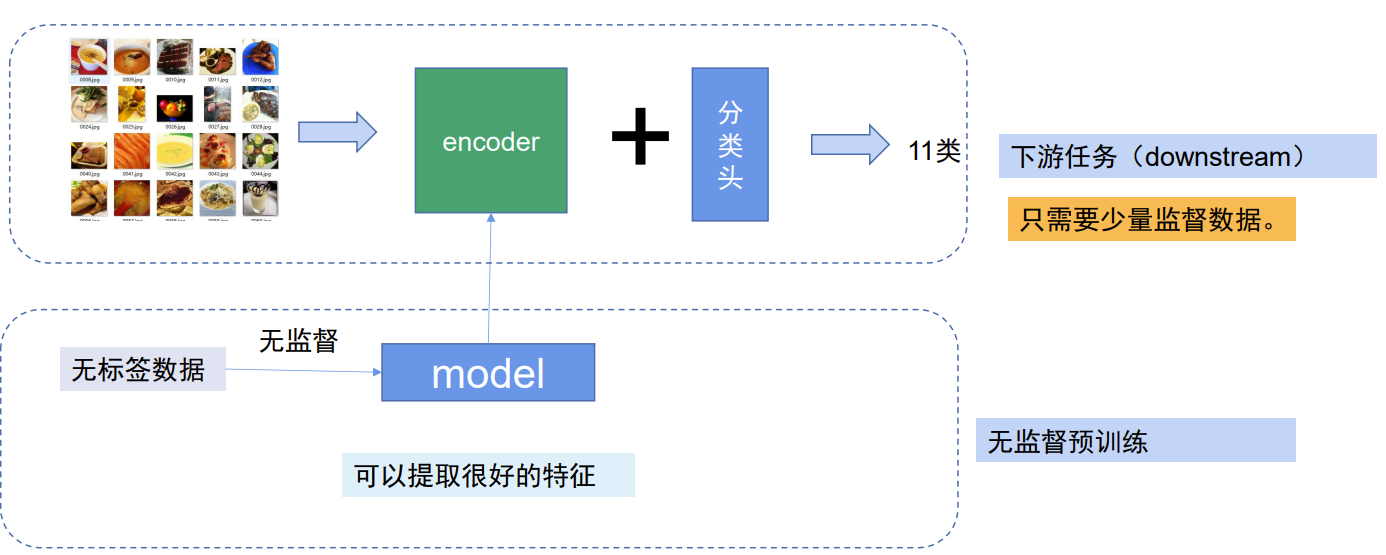
完成无监督后,我们就可以使用这个模型,为其他训练服务了。下图整体流程展示了先通过无监督预训练模型来提取特征,然后在下游任务中利用少量监督数据进行分类等操作的过程,无监督预训练可以帮助模型更好地学习数据的内在特征,从而提高下游任务的性能和效率。
自编码器
自编码器(Autoencoder)是一种无监督学习的神经网络模型,主要用于无监督学习任务,用于数据的降维、特征提取和数据重构。它通过编码器和解码器的结构,将输入数据转换为潜在表示,再从潜在表示重构回原始数据。
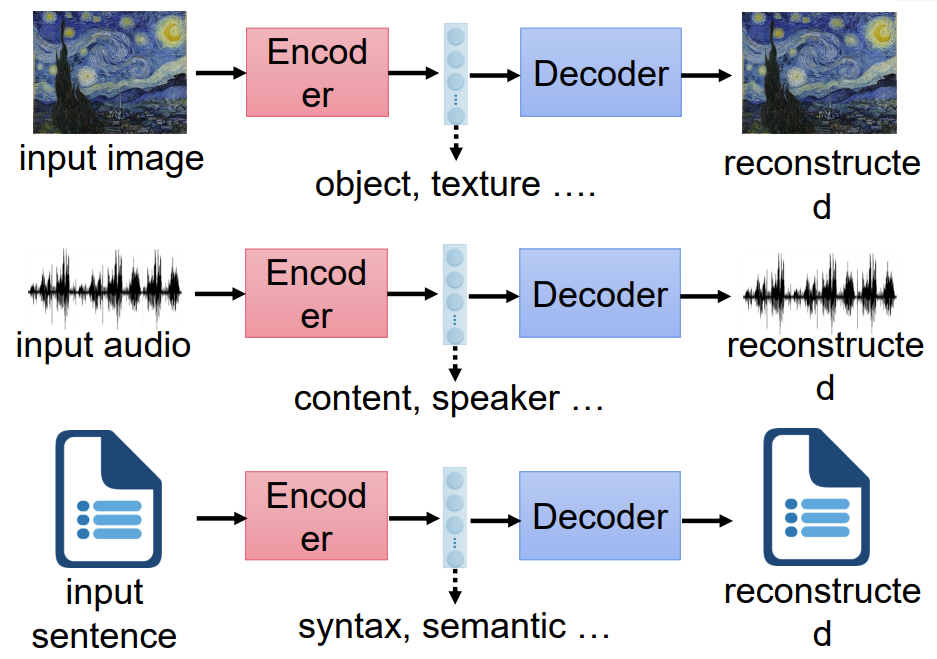
我们从图像中提取其风格与内容,再根据特征进行还原,同样可用于音频(内容 说话人)与文字(内容、方式)。
自编码器的应用
特征分离
特征分离(Feature disentanglement)将数据的复杂特征表示分解为多个相互独立或相关性较低的子特征的过程。在某些情况下,输入数据可能包含多个相关但不同的特征,这些特征可能以复杂的方式交织在一起。特征解耦的目标是将这些混杂的特征进行分解,使得模型能够独立地学习每个特征的表示,从而提取出更有意义、更有用的信息。
我们将这些特征分离后再组合,如下图,将图片的风格和内容特征分离再进行组合,可以创作出新的作品。
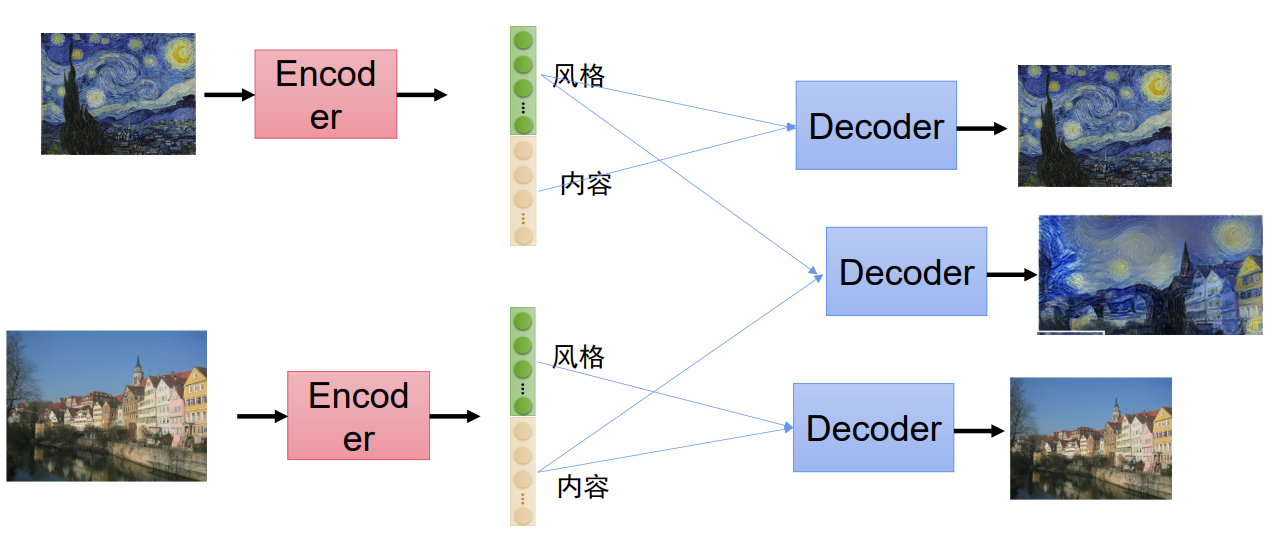
自编码器还有其他广泛用途,我们暂时仅进行简单了解。

















 1580
1580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









