







本文章的内容和知识为作者学习期间总结且部分内容借助AI理解,可能存在一定错误与误区,期待各位读者指正。
本文章中的部分例子仅用于生动解释相关概念,切勿结合实际过度解读。
语雀链接:《简单神经网络项目实战》
部分内容来源:B站:李哥考研
目前内容仍处于更新阶段,部分章节存在缺失内容,望读者理解
来写一个最简单的神经网络项目,首先我们需要明确整个训练流程
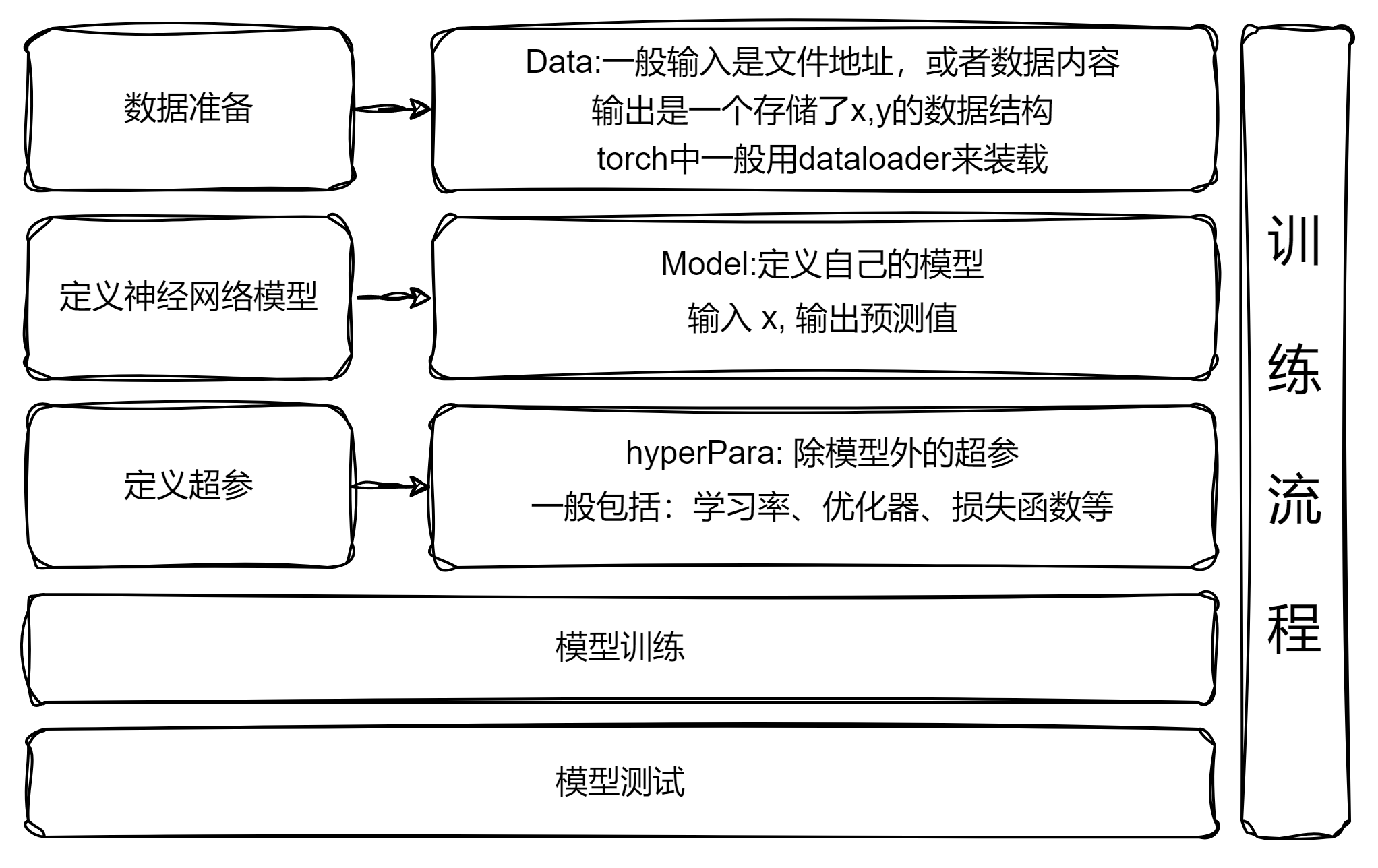
数据准备
在获取数据之前,我们要考虑一个问题:我们应该要取多少数据?是用所有数据算一次loss,还是每一个条数据都算一次loss,这两种方式听起来都太极端了。我们可以选用从训练数据中选出一批数据(称为mini-batch,小批量),然后对每个mini-batch进行学习,这种学习方式成为mini-batch学习。我们对数据训练多轮(多个epoch,而每个epoch训练很多batch)。如果我们将随机选择的min-batch数据与梯度下降方法结合,那么我们就得到了新方法:随机梯度下降法(stochastic gradient descent, SGD),“随机”指的是“随机选择的” 的意思。
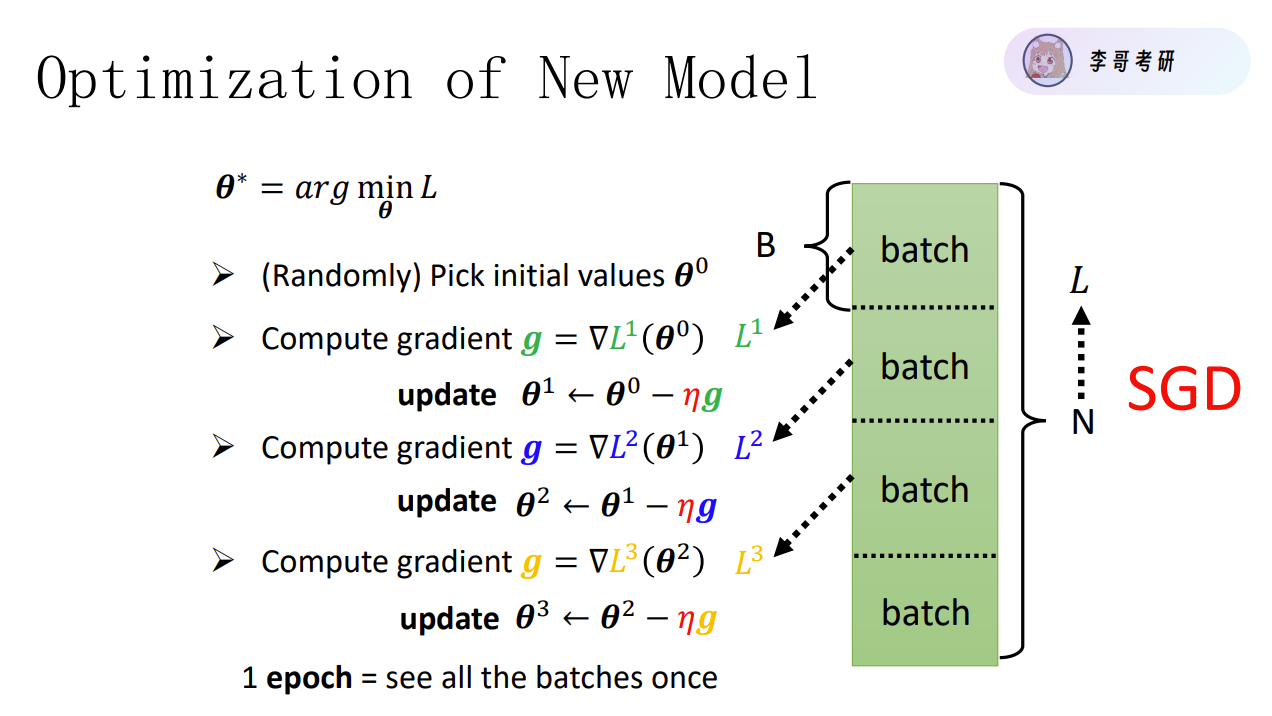
如果所有数据进行一次更新,资源成本:可能会导致内存占用高,计算时间长。模型训练效果差:在基于梯度下降的优化算法中,如果使用所有数据计算的梯度是整个数据集的平均梯度。对于非凸优化问题(大多数深度学习模型的损失函数都是非凸的),这种平均梯度可能会引导模型收敛到局部最优解,而不是全局最优解。如果数据是动态变化的,可能会导致对局部数据变化的不敏感,同时由于计算慢,导致更新存在滞后性
如果单数据进行一次更新,梯度估计的不稳定性:单个数据点计算得到的梯度可能会有很大的噪声,因为它只基于一个样本的信息。这会导致模型参数的更新方向可能比较随机,使得训练过程不稳定。例如,在一个复杂的非线性模型中,如果一个数据点是异常值,那么基于这个数据点计算的梯度可能会使模型参数朝着错误的方向更新,远离最优解。
在分批获取数据之前,我们先把数据从文件中获取出来
获取数据函数Dataset,它的主要作用是表示一个数据集,并提供一种标准的方式来访问数据集中的数据。
class CovidDataset(Dataset):
def __init__(self, file_path, mode="train"):
with open(file_path, "r") as f:
ori_data = list(csv.reader(f)) # 读文件 并转为列表
csv_data = np.array(ori_data[1:])[:, 1:].astype(float) # 去掉第一行 第一列,并转换成浮点数(原本结果为字符串)
if mode == "train":
indices = [i for i in range(len(csv_data)) if i % 5 != 0] # 每5空1
self.y = torch.tensor(csv_data[indices, -1]) # 获取对应的y(标签),即最后一列
data = torch.tensor(csv_data[indices, :-1]) # 获取特征(feature),去掉最后一列,其余作为训练集 因为y是结果 不用训练,只作为训练模型是否准确的参照
elif mode == "val":
indices = [i for i in range(len(csv_data)) if i % 5 == 0] # 逢5取1
self.y = torch.tensor(csv_data[indices, -1]) # 获取对应的y 即最后一列
data = torch.tensor(csv_data[indices, :-1]) # 去掉最后一列,其余作为训练集
else:
indices = [i for i in range(len(csv_data))] # 按顺序取
data = torch.tensor(csv_data[indices]) # 获取所有值 这里不能去掉最后一列,因为test.csv最后一列不是标签,是特征,你去掉之后就少了,没看懂可以看一下excel文件
# 归一化 将数据归为-1 到 1 之间
self.data = (data - data.mean(dim=0, keepdim=True)) / data.std(dim=0, keepdim=True)
self.mode = mode
# 获取数据
def __getitem__(self, idx):
# 不用64位 用32位 节省资源
if self.mode != "test":
# 不是测试 需要将x y 返回
return self.data[idx].float(), self.y[idx].float()
else:
# 测试模式下不用返回y ,因为待求的就是y
return self.data[idx].float()
# 返回数据集长度
def __len__(self):
return len(self.data)
1、什么是归一化?为什么要归一化?怎么归一化?
机器学习和深度学习模型中,不同的特征可能具有不同的取值范围和单位。例如,在一个预测房价的模型中,房屋面积可能以平方米为单位,取值范围可能是几十到几百;而房间数量可能是整数,范围在 1 - 10 之间。如果不进行归一化,面积这个特征由于数值较大,在模型训练过程中可能会对模型的参数更新产生主导作用,使得模型更倾向于学习面积相关的模式,而忽略房间数量等其他特征。而归一化后,所有特征被缩放到相同的范围,如 [0,1] 或 [- 1,1],这样模型在学习过程中能够平等地对待各个特征,更全面地学习数据中的各种模式,从而提高模型的准确性和稳定性。
Z - score 归一化算法: x n e w x_{new} xnew= ( x x x- 平均值)/ 标准差 = x n e w = x − μ σ x_{new}=\frac{x-μ}{σ} xnew=σx−μ,其中 μ μ μ为平均值, σ σ σ为标准差
2、为什么这里转成浮点数(float)?
通常在深度学习中,为了节省内存和计算资源等,会选择合适的数据类型,这里选择了 32 位浮点数而不是 64 位。
数据获取到了,那该如何随机分批获取呢?
DataLoader是一个用于加载数据的工具。它的主要功能是从给定的数据集(通常是自定义的数据集类,继承自Dataset)中按照一定的规则(如批次大小、是否打乱顺序等)加载数据,然后将这些数据以方便模型训练的格式提供给模型。
# 文件路径
train_file = "covid.train.csv"
test_file = "covid.test.csv"
# dataset 实例化对象,根据模式不同,获取数据集
train_dataset = CovidDataset(train_file, "train")
val_dataset = CovidDataset(train_file, "val")
test_dataset = CovidDataset(test_file, "test")
# loader 从dataset分批且按照规则取数据,shuffle 是否打乱,batch_size(批次大小)
batch_size = 16
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True)
# 测试模式下,单个进行测试且不能随机
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False)
batch_size规定了批次的大小,为16条数据,shuffle=True规定了随机获取,通过DataLoader方法,可以实现分批且随机获取数据。
测试模式下,应该单个进行计算,并按顺序输出
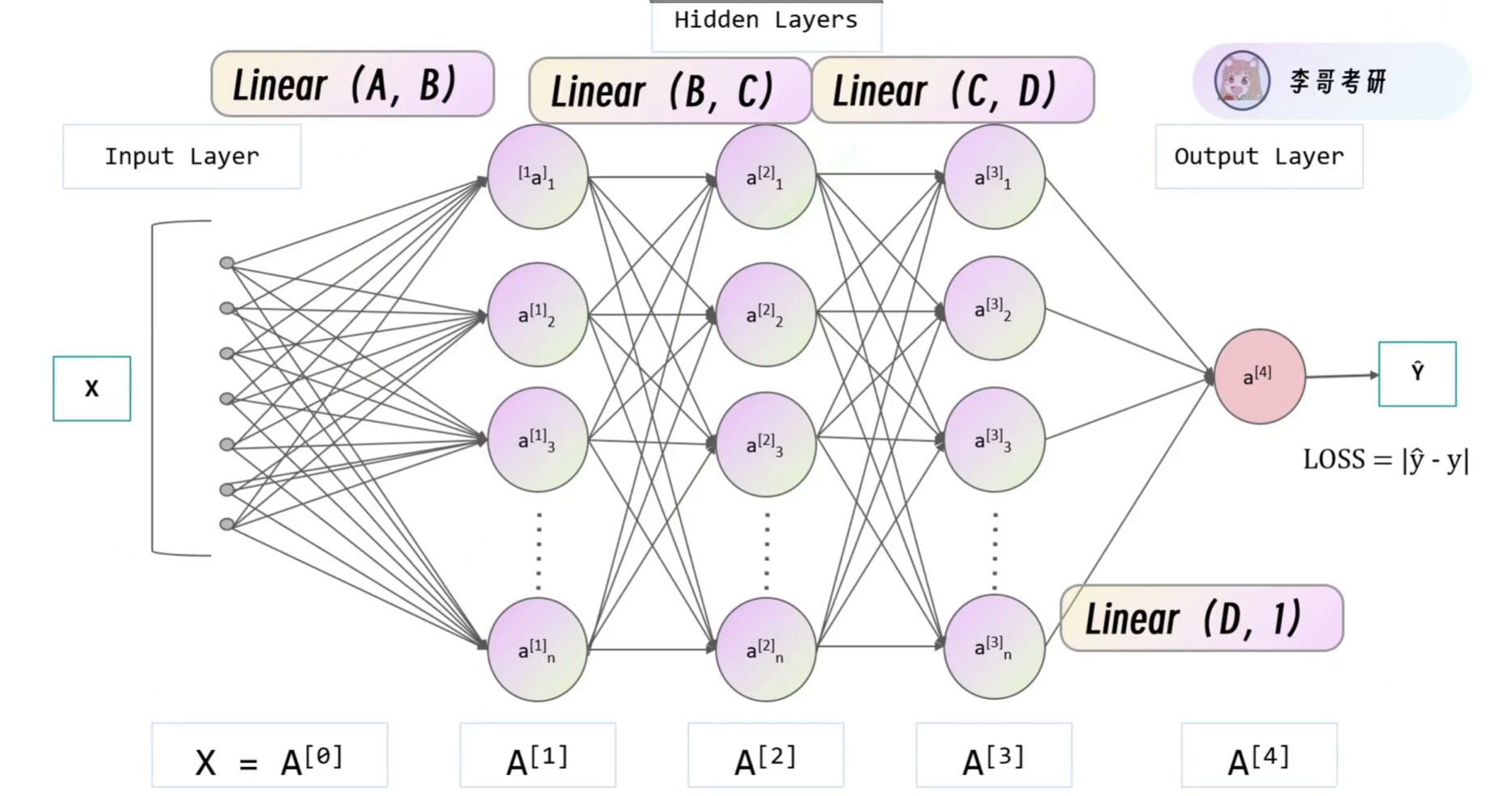
定义神经网络模型
规定模型长什么样子,也就是我们模型的内部形状
forward 即向前走的过程,是黑线的过程。与之对应的是 backward 即回传,是色虚线的过程。
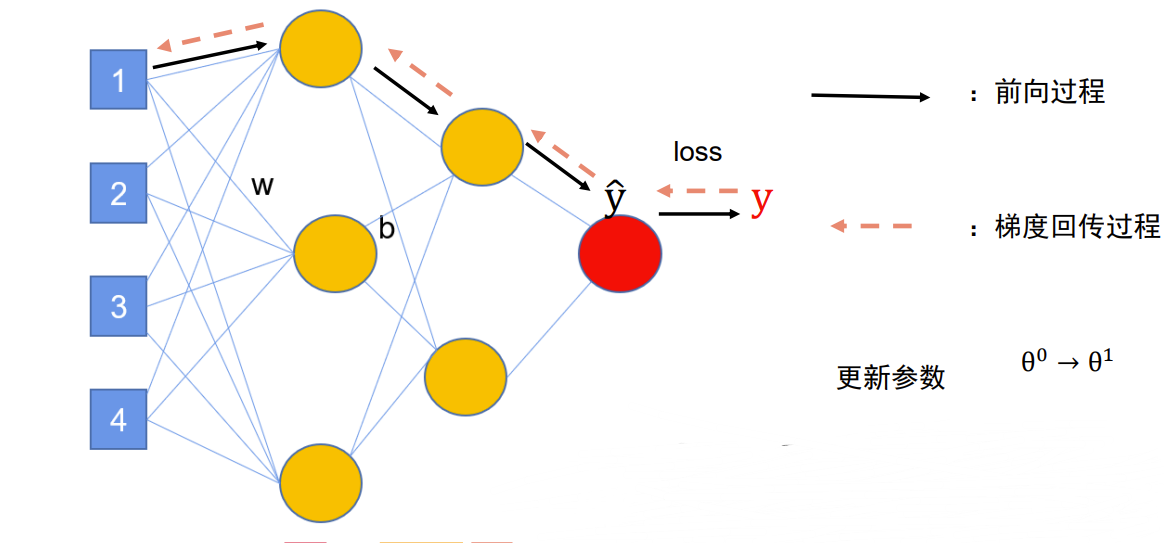
本案例神经网络模式为全连接,全连接是指当前层的每个神经元与下一层的所有神经元都有连接。
在回归中我们一般使用全连接,我们要关注维度变化,要注意的是前一层Linear的输出,一定是下一层Linear的输入。本案例下,X为 (16,93) ,16为样本数即批次大小,93才是我们更关注的特征数,因此A需要设置为93。
class MyModel(nn.Module):
def __init__(self, inDim):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(inDim, 64) # 全连接
self.relu1 = nn.ReLU() # 激活函数
self.fc2 = nn.Linear(64, 1) # 全连接
def forward(self, x): #forward, 即模型前向过程,数据如何通过这个模型
# 按照f1,relu1,fc2的顺序
x = self.fc1(x)
x = self.relu1(x)
x = self.fc2(x)
# x最终变为16,1 也就是我们要的预测值,若大于1维,则去掉后面那个 16,1 去掉1
if len(x.size()) > 1:
return x.squeeze(1)
return x # x 最终变成预测值
model = MyModel(inDim=93) # 93维
# 后续将优化成以下代码,我们但我们暂时先不关注他
# model = MyModel(inDim=feature_dim).to(device)
pred_y = model(batch_x) # 规定 如果() 则 forward
1、能否解释一下第15行代码?
根据上述操作,我们已经得到预测值(这里用变量x接收)为二维张量,大小为(16,1),但是真实值(batch_y)只有一维,为(16)。大小不同是不能进行运算的,所以我们得对得到的预测值进行降维。这里我们使用squeeze()方法
squeeze()是张量(Tensor)的一个方法,用于去除张量中维度大小为 1 的维度。它的主要目的是调整张量的维度,使张量的形状更符合实际需求,避免出现不必要的单维度情况。不输入参数,则去掉全部,输入则去掉指定索引。请注意,该方法只能去掉维度大小为1的维度。
定义超参
config = {
'device' = 'cuda' if torch.cuda.is_available() else 'cpu' #选择使用cpu还是gpu计算。
"lr": 0.001, # 学习率
"epochs": 20, # 轮次
"momentum": 0.9, # 动量
"save_path": "model_save/best_model.pth", # 最好的模型 保存路径
"rel_path": "pred.csv" # 测试结果保存路径
}
# 将模型放在device上
model = MyModel(inDim=93).to(config["device"])
# 设置损失函数,目前用官方提供的
loss = nn.MSELoss()
# 优化器 momentum为动量
optimizer = optim.SGD(model.parameters(), lr=config["lr"], momentum=config["momentum"])
device:设备,主要是根据当前系统的硬件配置情况,合理地选择用于运行深度学习模型及相关计算的设备。它优先尝试使用 GPU(如果可用)来加速计算,若 GPU 不可用,则选择使用 CPU 进行计算。
momentum:动量,它最初是受到物理学中动量概念的启发,用于加速模型训练过程中的收敛,并减少在优化过程中可能出现的震荡。
加速收敛:在优化过程中,特别是在损失函数的下降方向比较稳定的区域,动量能够积累之前的下降趋势,使得参数更新的步长更大,从而加速收敛。
减少震荡:动量可以帮助模型跳过浅的局部最优解,减少在这些局部最优解附近的震荡,从而更有可能找到全局最优解或者更好的局部最优解。
save_path :模型保存路径,在模型训练过程中,某个阶段的模型效果最好,我们要保存下来
rel_path:测试结果保存路径,当处于"test"模式下,将输出的结果,保存到文件。
学习率和轮次不再解释
所有准备工作都做好后,我们现在要开始编写训练方法了,希望你还能记得训练的流程。
def train_val(model, train_loader, val_loader, device, epochs, optimizer, loss, save_path):
model = model.to(device) # 模型和数据 ,要在一个设备上。
plt_train_loss = [] # 记录所有轮次的loss
plt_val_loss = [] # 同理
min_val_loss = 9999999999999 # 用于记录最小的loss值,以判断最好的模型
for epoch in range(epochs): # 开始训练,是冲锋的号角
train_loss = 0.0
val_loss = 0.0
start_time = time.time() # 记录开始时间 没什么用,只是通过它知道这一轮用了多少时间
# 训练
model.train() # 模型调为训练模式,有些模型中的某些结构,会因为训练或测试模式,而有所不同
for batch_x, batch_y in train_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x) # 通过模型 得到预测值--》forward
train_bat_loss = loss(pred, target,model) # 计算loss
train_bat_loss.backward() # 梯度回传
optimizer.step() # 更新模型
optimizer.zero_grad() # 模型梯度清零
train_loss += train_bat_loss.cpu().item() # 记录本轮loss,张量转数值
plt_train_loss.append(train_loss / train_loader.dataset.__len__()) # 将本轮loss记录下来
# 验证 只是验证效果,不能积攒梯度
model.eval() # 模型设置为验证状态
with torch.no_grad(): # 模型不再计算梯度
for batch_x, batch_y in val_loader: # 从验证集取一个batch的数据
x, target = batch_x.to(device), batch_y.to(device) # 将数据放到设备上
pred = model(x) # 用模型预测数据
val_bat_loss = loss(pred, target,model) # 计算loss
val_loss += val_bat_loss.cpu().item() # 累计loss
plt_val_loss.append(val_loss/ val_loader.__len__()) # 记录loss到列表。注意是平均的loss ,因此要除以数据集长度。
# 保存效果最好的模型
if val_loss < min_val_loss:
torch.save(model, save_path)
min_val_loss = val_loss
# 输出的样例:[020/020] 0.32 sec(s) train_loss 1.111988 | valloss 1.037118
print("[%03d/%03d] %2.2f sec(s) Trainloss: %.6f |Valloss: %.6f"% \
(epoch + 1, epochs, time.time()-start_time, plt_train_loss[-1], plt_val_loss[-1]))
# 绘图
plt.plot(plt_train_loss) # 画图, 向图中放入训练loss数据
plt.plot(plt_val_loss) # 画图, 向图中放入训练loss数据
plt.title("loss") # 画图, 标题
plt.legend(["train", "val"]) # 画图, 图例
plt.show() # 画图, 展示
# 进行测试
def evaluate(sava_path, test_loader,device,rel_path ): #得出测试结果文件
model = torch.load(sava_path).to(device)
rel = []
with torch.no_grad(): # 模型不再计算梯度
for x in test_loader: # 从测试集取一个batch的数据
x = data.to(device) # 将数据放到设备上
pred = model(x) # 用模型预测数据
rel.append(pred.cpu().item()) #记录预测结果
with open(rel_path, "w",newline='') as f: #打开保存的文件
csvWriter = csv.writer(f) #初始化一个写文件器 writer
csvWriter.writerow(["id","tested_positive"]) #在第一行写上 “id” 和 “tested_positive”
for i, value in enumerate(rel): # 把测试结果的每一行放入输出的excel表中。
csvWriter.writerow([str(i), str(value)])
print("文件已经保存到"+rel_path)
注释相对详细,暂时不做补充
下面对上述方法的调用,也就是开始训练、验证和测试
# 既训练又验证
train_val(model, train_loader, val_loader, config["device"], config["epochs"], optimizer, loss, config["save_path"])
# 测试
evaluate(config["save_path"], test_loader, config["device"], config["rel_path"])
优化
正则化
待补充
LOSS = LOSS + W*W
LOSS = W(Y_0 - Y) + B
如果相差很大,那么由于loss很大,模型就会猛冲,就会导致过拟合现象
让你的参数更靠近0 平滑一些 这是一种解释
# 正则化
def mseLoss_with_reg(pred, target, model):
loss = nn.MSELoss(reduction='mean')
''' Calculate loss '''
regularization_loss = 0 # 正则项
for param in model.parameters():
# TODO: you may implement L1/L2 regularization here
# 使用L1正则项
# regularization_loss += torch.sum(abs(param))
# 使用L2正则项
regularization_loss += torch.sum(param ** 2) # 计算所有参数平方
return loss(pred, target) + 0.00075 * regularization_loss
loss = mseLoss_with_reg
L2 正则化的主要目的是防止模型过拟合。
相关系数
待补充
在提供的数据中,有些特征可能对训练模型没什么用,甚至是副作用,排除它们甚至可能会导致结果变好,就像打游戏时,菜鸡队友的指挥对我们来说可能是副作用,我们需要判断哪些队友是大神,哪些是菜鸡,排除干扰,确定重心才会更接近胜利。我们使用特征选择的相关方法来衡量每个特征与目标标签之间的相关性,进而确定重要特征。
def get_feature_importance(feature_data, label_data, k=4, column=None):
"""
此处省略 feature_data, label_data 的生成代码。
如果是 CSV 文件,可通过 read_csv() 函数获得特征和标签。
这个函数的目的是, 找到所有的特征种, 比较有用的k个特征, 并打印这些列的名字。
"""
model = SelectKBest(chi2, k=k) # 定义一个选择k个最佳特征的函数
feature_data = np.array(feature_data, dtype=np.float64)
# label_data = np.array(label_data, dtype=np.float64)
X_new = model.fit_transform(feature_data, label_data) # 用这个函数选择k个最佳特征
# feature_data是特征数据,label_data是标签数据,该函数可以选择出k个特征
print('x_new', X_new)
scores = model.scores_ # scores即每一列与结果的相关性
# 按重要性排序,选出最重要的 k 个
indices = np.argsort(scores)[::-1] # [::-1]表示反转一个列表或者矩阵。
# argsort这个函数, 可以矩阵排序后的下标。 比如 indices[0]表示的是,scores中最小值的下标。
if column: # 如果需要打印选中的列
k_best_features = [column[i + 1] for i in indices[0:k].tolist()] # 选中这些列 打印
print('k best features are: ', k_best_features)
return X_new, indices[0:k] # 返回选中列的特征和他们的下标。
主成分分析PCA
暂时没有
补充
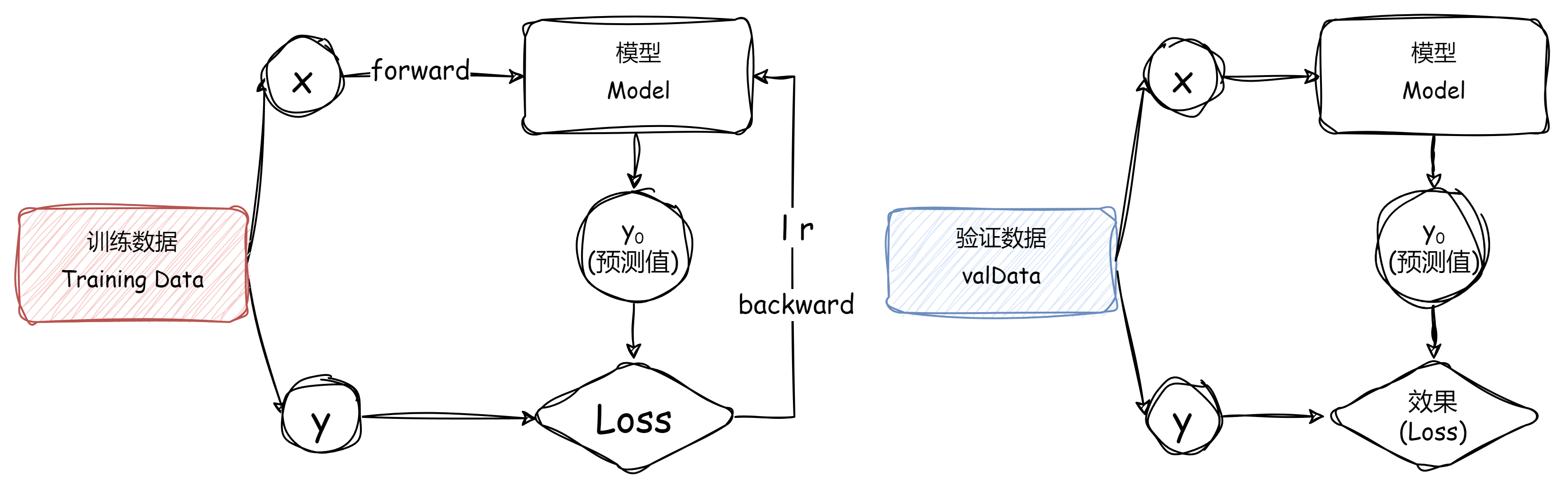
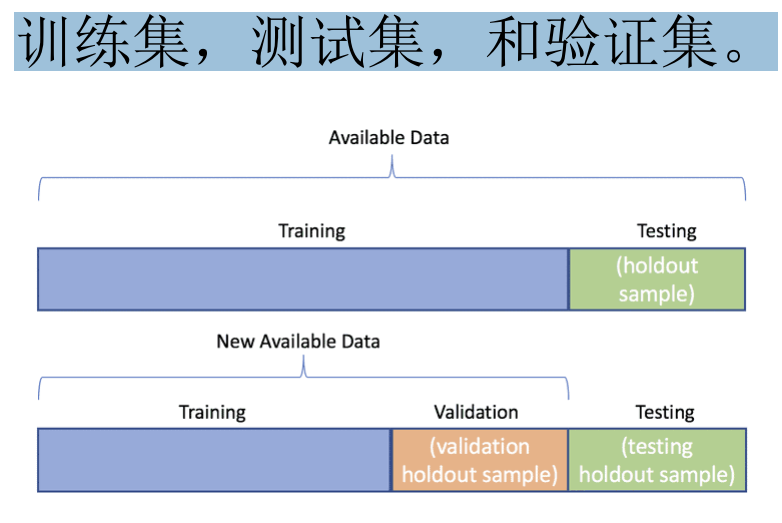
训练、验证、测试的关系
先用一个不恰当的比喻来说明3种数据集之间的关系:
- 训练集相当于上课学知识
- 验证集相当于课后的的练习题,用来纠正和强化学到的知识
- 测试集相当于期末考试,用来最终评估学习效果
训练集(Training Dataset)是用来训练模型使用的。
当我们的模型训练好之后,我们并不知道他的表现如何。这个时候就可以使用验证集(Validation Dataset)来看看模型在新数据(验证集和测试集是不同的数据)上的表现如何。同时通过调整超参数,让模型处于最好的状态。
当我们调好超参数后,就要开始「最终考试」了。我们通过测试集(Test Dataset)来做最终的评估。

















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









