







 本文介绍了VGG模型,它源于牛津大学的Visual Geometry Group,常用于人脸识别和图像分类。VGG网络结构固定步长,滤波器大小为3x3或1x1,从VGG11到VGG19不等,包含多个卷积和全连接层。随后,文章提到了Unet模型,这是一个像素级分类的语义分割模型,适合自动驾驶场景的检测。Unet通过结合下采样和上采样路径来实现精确的图像分割。
本文介绍了VGG模型,它源于牛津大学的Visual Geometry Group,常用于人脸识别和图像分类。VGG网络结构固定步长,滤波器大小为3x3或1x1,从VGG11到VGG19不等,包含多个卷积和全连接层。随后,文章提到了Unet模型,这是一个像素级分类的语义分割模型,适合自动驾驶场景的检测。Unet通过结合下采样和上采样路径来实现精确的图像分割。
1.VGG
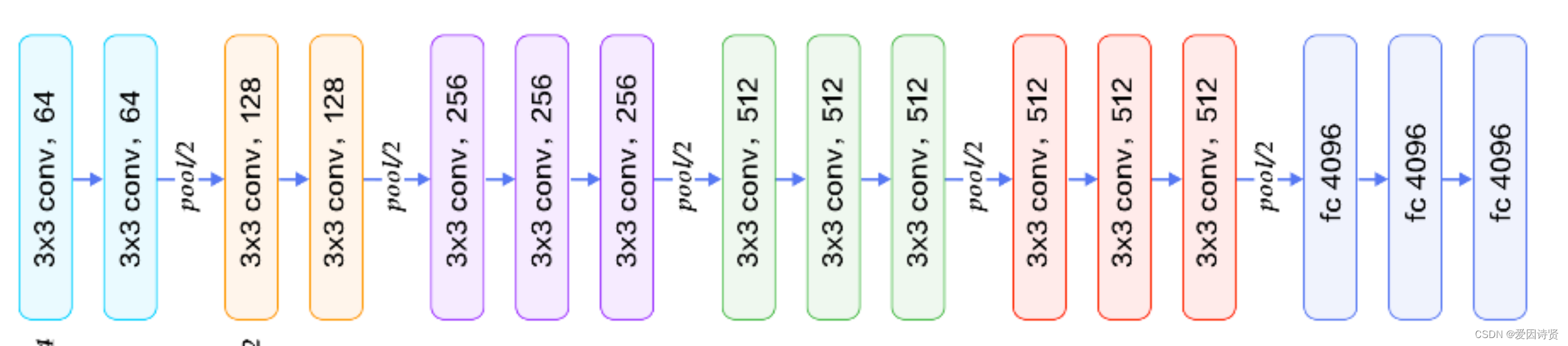
VGG全称是Visual Geometry Group属于牛津大学科学工程系,其发布了一些列以VGG开头的卷积网络模型,可以应用在人脸识别、图像分类等方面,VGG的输入被设置为大小为224x244的RGB图像。为训练集图像上的所有图像计算平均RGB值,然后将该图像作为输入输入到VGG卷积网络。使用3x3或1x1滤波器,并且卷积步骤是固定的。有3个VGG全连接层,根据卷积层+全连接层的总数,可以从VGG11到VGG19变化。最小VGG11具有8个卷积层和3个完全连接层。最大VGG19具有16个卷积层+3个完全连接的层。此外,VGG网络后面没有每个卷积层后面的池化层,也没有分布在不同卷积层下的总共5个池化层。
结构图如下:
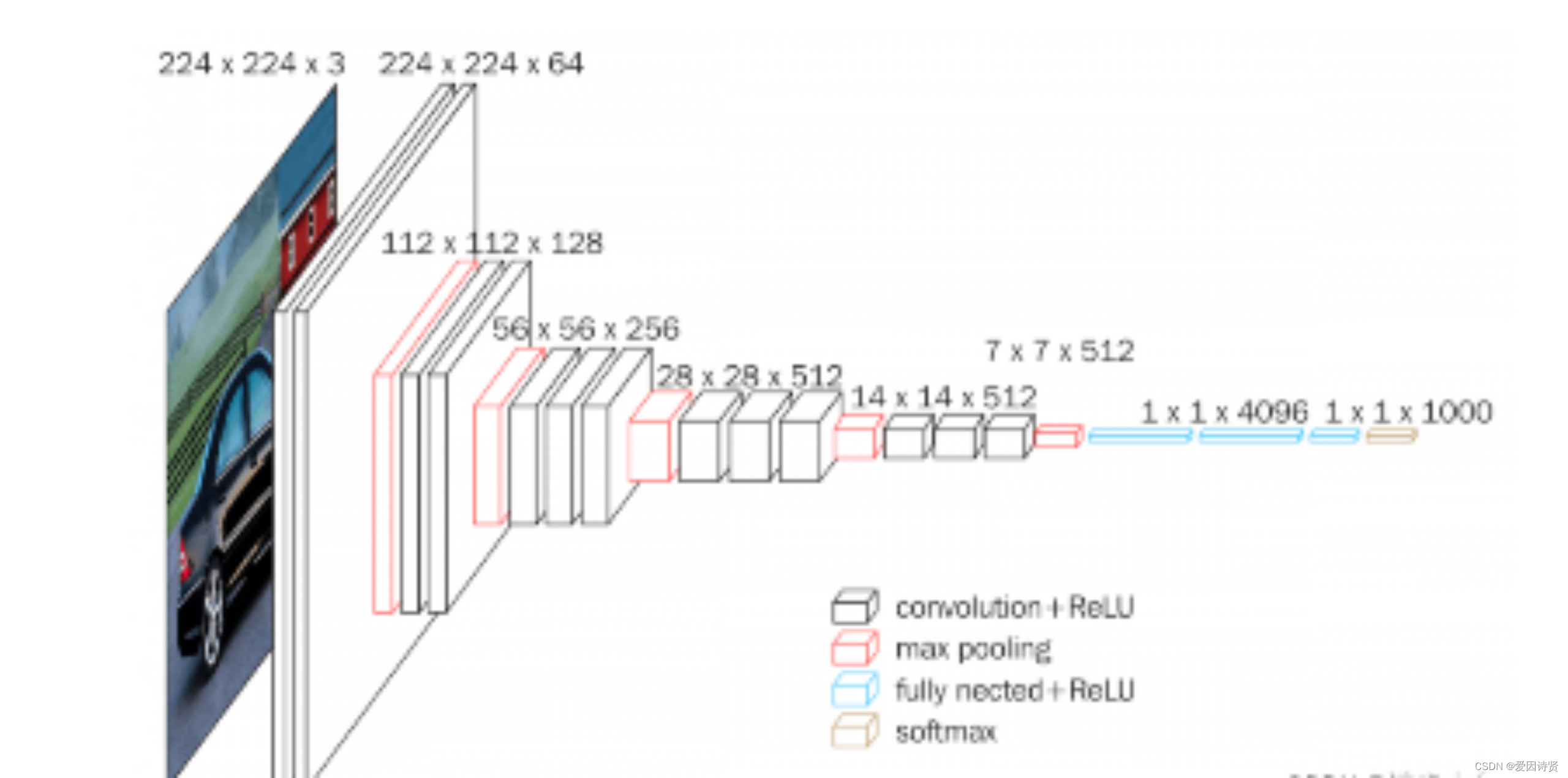
架构图
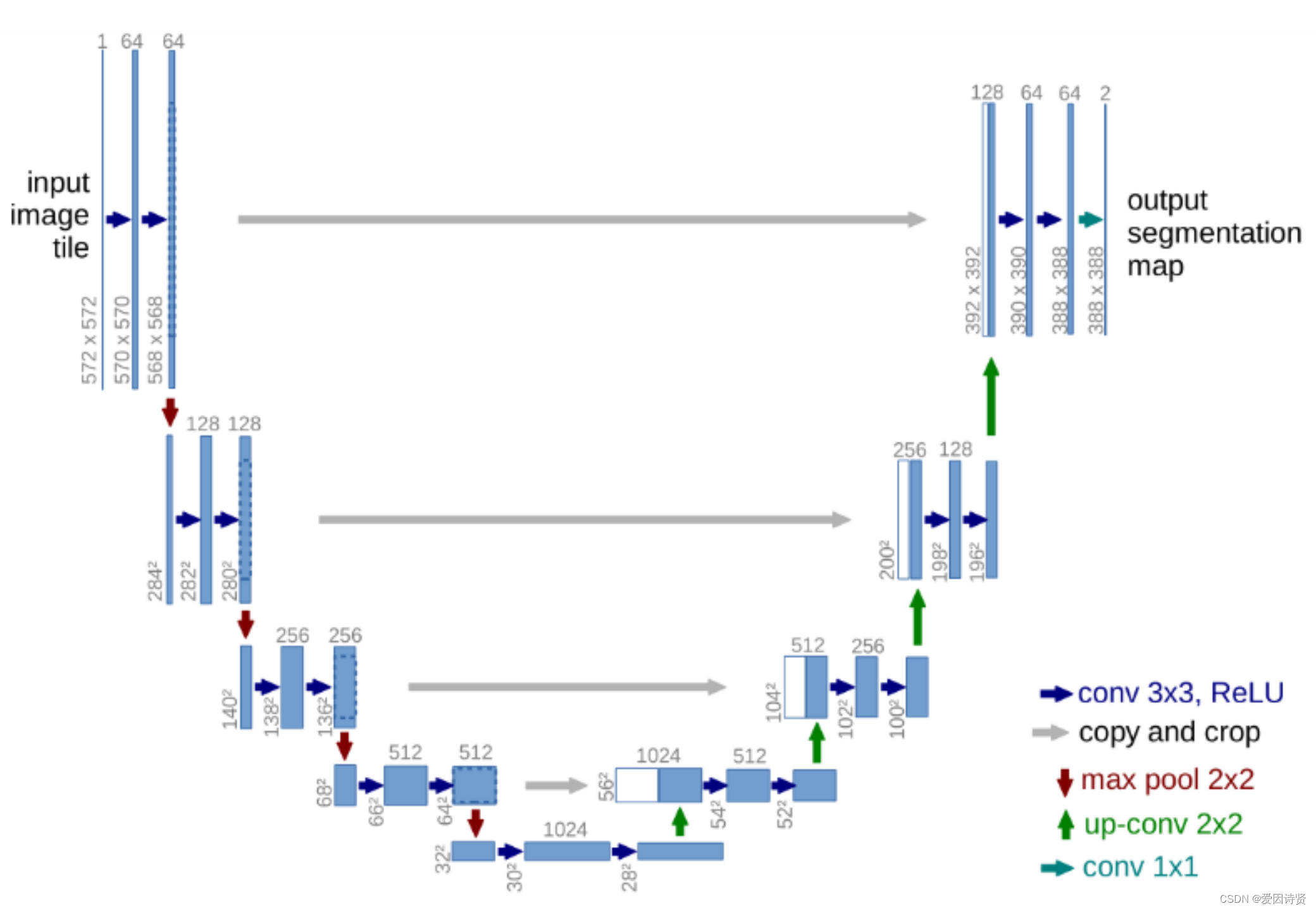
2.Unet模型:
Unet是一个优秀的语义分割模型,其主要执行过程与其它语义分割模型类似。与CNN不同的之处在于CNN是图像级的分类,而unet是像素级的分类,其输出的是每个像素点的类别
主要代码如下:
def get_vgg_encoder(input 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2142
2142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









