









最优化
定义
就是寻找参数W,能够使得损失函数值最小。(简略,非数学上的定义)
方法
1、找到目标函数(知道目标函数是什么,是cross-entropy或者其它的损失函数,都行)
2、找到一个能让目标函数最优化的方法(梯度下降)(当梯度下降应用到神经网络时,会与机器学习的梯度下降不太一样,比如加入链式法则,反向传播算法如何应对比较大的深层/浅层神经网络)
3、利用这个方法求解
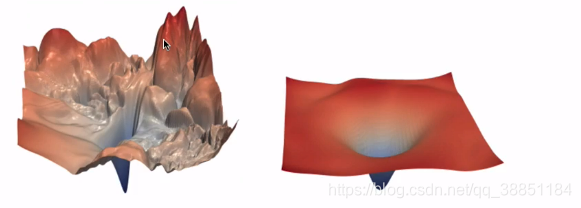
当梯度下降到了神经网络,就不再是凸函数了,也不会是下图右边的碗状,而是“地形图”:
神经网络的链式法则与反向传播算法
这节内容需要用到高等数学:导数等知识。链式法则则符合函数求导。反向传播即将结果+链式法则的这个过程。
一些常用的函数及其导数:

逻辑回归的推导计算图过程
前向传播过程:

1、函数表达式
2、预测
3、确定损失函数
假设有两个特征,那么前向传播如下图所示:

反向传播:利用链式法则进行求导,更新权重参数的过程。
计算J关于Z的导数的计算公式:

逻辑回归前向与反向传播简单计算的代码实现
假设简单的模型为 y = sigmoid(w1x1+w2x2+b),我们一开始给几个随机的输入值和权重,带入来计算一遍。其中,在点x1,x2=(-1,-2)时,目标值为1,假设一个初始化w1,w2,b=(2,-3,-3)。用代码实现上述过程:
import numpy as np
# 1 初始化的权重
x=[-1,-2]
w=[2,-3,-3]
y=1
# 2 进行预测+sigmoid函数+交叉熵损失函数计算 也就是 前向传播
y_pred = w[0]*x[0] + w[1]*x[1] + w[2]
y_pred = 1.0/(1+np.exp(-y_pred))
loss = -np.sum(y*np.log(y_pred) + (1-y)*np.log(1-y_pred))
print(loss) # 0.3132616875182228
# 3 反向传播计算
dz = y_pred - y
dw1 = dz*x[0]
dw2 = dz*x[1]
db = dz
# 4 更新参数 重新计算损失函数
w1 = [w[0]-dw1,w[1]-dw2,w[2]-db]
y_pred1 = w1[0]*x[0] + w1[1]*x[1] + w1[2]
y_pred1 = 1.0/(1+np.exp(-y_pred1))
loss1 = -np.sum(y*np.log(y_pred1) + (1-y)*np.log(1-y_pred1))
print(loss1) # 0.07070702524974655
通过结果可以看到,只是进行了一次梯度下降的循环,损失函数就能减少这么多,也就是一直朝着我们所希望的方向进行发展。
向量化的实现
上述的情况都是一个样本,那么当我们有很多样本(m个)的时候,伪代码如下:
for i in m:
计算预测值
计算损失
损失求和
梯度求和
平均损失和梯度
这是一个可行的方法2,但是会存在缺陷:在实际中,我们有成上千万个样本,都要进行for循环来计算吗?我们需要充分利用计算机CPU并行处理的优点,在python的numpy包中,有很多方便的工具,可以去菜鸟教程查看,就不一一演示了。
实现单神经元的神经网络
这里使用一些数据集以向量化的形式进行实现,数据集放在百度网盘:
链接: https://pan.baidu.com/s/1UL5FOZ7K8-yPcpt_kx8hfA
密码: 6pdr
下面的代码为自定义的模型和数据处理流程,有些内容和API里封装的不一样,当然可以往下面的模型中增加更多的内容来丰富一下结果。(比如更改梯度下降方式,增加可视化损失函数)
先大概说明一下代码思路:
1、主函数部分:
加载数据集,并且对数据集进行处理,调用模型进行训练以及预测
2、模型部分:
- 1)初始化参数
- 2)进行参数优化(放在自定义优化函数optimize下)
- 3)进行预测
- 4)返回损失、权重、打印出预测信息等。
其中: - 1、自定义优化函数optimize:
进行前向传播+反向传播(由propagate函数完成),返回的是权重参数和损失,也可以自定义返回内容。 - 2、propagate函数:
进行矩阵运算,并且将矩阵运算结果通过Sigmoid函数映射,然后计算损失,返回的是梯度和损失。
代码如下:
import h5py
import numpy as np
# 载入数据集
def load_datasets():
train_data = h5py.File('datasets/train_catvnoncat.h5')
X_train = np.array(train_data['train_set_x'][:])
y_train = np.array(train_data['train_set_y'][:])
test_data = h5py.File('datasets/test_catvnoncat.h5')
X_test = np.array(test_data['test_set_x'][:])
y_test = np.array(test_data['test_set_y'][:])
classes = np.array(test_data['list_classes'][:])
y_train = y_train.reshape((1, y_train.shape[0]))
y_test = y_test.reshape((1, y_test.shape[0]))
return X_train, X_test, y_train, y_test, classes
# 初始化
def initialize_with_zeros(shape):
w = np.zeros((shape,1))
b = 0
return w, b
def Sigmoid(x):
s = 1.0/(1+np.exp(-x))
return s
# 进行梯度下降
def propagate(w, b, X, Y):
# 前向传播、计算损失
A = Sigmoid(np.dot(w.T, X) + b)
m = 64*64*3
loss = - 1/m * np.sum( Y * np.log(A) + (1-Y) * np.log(1-A))
#反向传播
dz = A-Y
dw = 1/m * np.dot(X,dz.T)
db = 1/m * np.sum(dz)
grads = {
'dw':dw,
'db':db
}
return grads, loss
# 优化
def optimize(w, b, X, Y, iterations, learning_rate):
# 将每一次的损失记录下来,(可以记录也可以不记录)
losses = []
for i in range(iterations):
# 每一次迭代,都进行一次 前向传播+反向传播
grads, loss = propagate(w,b,X,Y)
dw = grads['dw']
db = grads['db']
w = w - learning_rate * dw
b = b - learning_rate * db
if i%100 == 0:
losses.append(loss)
print(('损失结果 %d: %f' % (i, loss)))
params = {'w':w,
'b':b}
grads = {'dw':dw,
'db':db
}
return params, grads, losses
def predict(w,b,X):
'''
:param w: 训练好的权重
:param b:
:param X: 数据集
:return: 预测结果
'''
m = X.shape[1]
Y = np.zeros((1,m))
w = w.reshape(X.shape[0],1)
# 进行预测
A = Sigmoid(np.dot(w.T, X) + b)
for i in range(A.shape[1]):
if A[0,i] < 0.5 :
Y[0,i] = 0
else:
Y[0,i] = 1
assert (Y.shape == (1,m))
return Y
# 训练的模型model
def model(X_train, X_test, y_train, y_test, iterations, learning_rate):
'''
:param X_train:
:param X_test:
:param y_train:
:param y_test:
:param iterations: 迭代次数
:param learning_rate: 学习率
:return:
'''
# 1 初始化参数
w, b = initialize_with_zeros(X_train.shape[0])
# 2 优化参数(权重 梯度下降),得到优化后的参数、梯度、损失
params, grads, losses = optimize(w,b,X_train,y_train,iterations=iterations,learning_rate=learning_rate)
# 3 进行预测
w = params['w']
b = params['b']
y_pred_train = predict(w,b,X_train)
y_pred_test = predict(w,b,X_test)
print('训练集准确率:{0}'.format(100 - np.mean(np.abs(y_pred_train-y_train))*100))
print('测试集准确率:{0}'.format(100 - np.mean(np.abs(y_pred_test-y_test))*100))
d = {
'cost': losses,
'w': w,
'b': b,
'learning_rate': learning_rate
}
return d
def main():
# 加载数据集
X_train, X_test, y_train, y_test, classes = load_datasets()
print(X_train.shape)
# 数据形状修改以及归一化
X_train = X_train.reshape(X_train.shape[0], -1).T
X_test = X_test.reshape(X_test.shape[0], -1).T
X_train = X_train/255.
X_test = X_test/255.
# 模型训练以及预测
d = model(X_train, X_test, y_train, y_test, iterations=2000, learning_rate=0.09)
return
if __name__ == '__main__':
main()
结果:
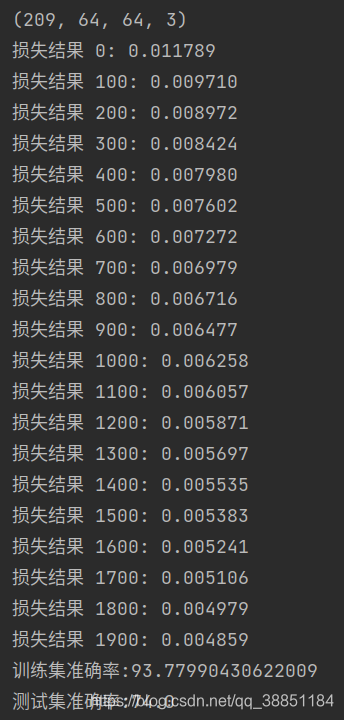
可以看出来损失结果由最初的0.01变到最后的0.004,在训练集上达到93%的准确率。由于我们是使用了单个神经元,就能达到测试集73%,如果使用更多神经元,再加上防止过拟合机制,那么这个模型会更好。
总结
要熟悉一下内容:
1、链式法则优化
2、梯度下降
3、向量化计算


















 6935
6935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











