







简介
1 神经网络复杂度
1.1 时间复杂度
1.2 空间复杂度
2 学习率策略
2.1 指数衰减
2.2 分段常数衰减
3 激活函数
3.1 sigmoid
3.2 tanh
3.3 ReLU
3.4 Leaky ReLU
3.5 softmax
3.6 建议
4 损失函数
4.1 均方误差损失函数
4.2 交叉熵损失函数
4.3 自定义损失函数
5 欠拟合与过拟合
6 优化器
6.1 SGD
6.1.1 vanilla SGD
6.1.2 SGD with Momentum
6.1.3 SGD with Nesterov Acceleration
6.2 AdaGrad
6.3 RMSProp
6.4 AdaDelta
6.5 Adam
6.5 优化器选择
6.6 优化算法的常用tricks
1 神经网络复杂度

1.1 时间复杂度
即模型的运算次数,可用浮点运算次数或者乘加运算次数衡量.
1.2 空间复杂度
空间复杂度(访存量),严格来讲包括两部分:总参数量 + 各层输出特征图。
参数量:模型所有带参数的层的权重参数总量;
特征图:模型在实时运行过程中每层所计算出的输出特征图大小。
2 学习率策略

学习率,表征了参数每次更新的幅度。
2.1 指数衰减
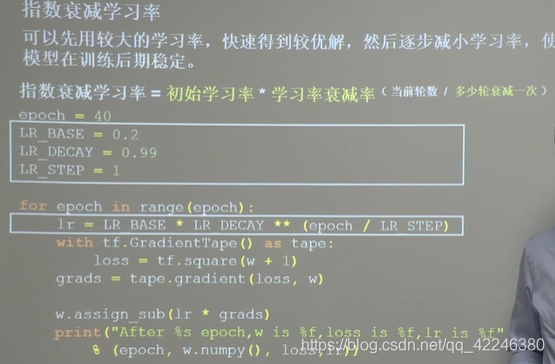
2.2 分段常数衰减
分段常数衰减可以让调试人员针对不同任务设置不同的学习率,进行精细调参,在任意步长后下降
任意数值的learning rate,要求调试人员对模型和数据集有深刻认识.
3 激活函数
激活函数是用来加入非线性因素的,因为线性模型的表达能力不够。引入非线性激活函数,可使深层神经网络的表达能力更加强大。
优秀的激活函数应满足:
非线性: 激活函数非线性时,多层神经网络可逼近所有函数
可微性: 优化器大多用梯度下降更新参数
单调性: 当激活函数是单调的,能保证单层网络的损失函数是凸函数
近似恒等性: . 当参数初始化为随机小值时,神经网络更稳定
激活函数输出值的范围:
激活函数输出为有限值时,基于梯度的优化方法更稳定
激活函数输出为无限值时,建议调小学习率
常见的激活函数有:sigmoid,tanh,ReLU,Leaky ReLU,PReLU,RReLU, ELU(Exponential Linear Units),softplus,softsign,softmax等,下面介绍几个典型的激活
函数:
3.1 sigmoid
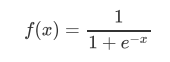
函数图像
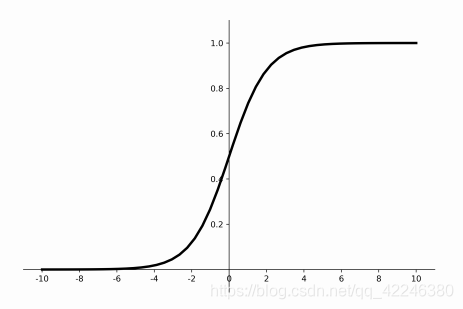
倒数图像
优缺点

3.2 tanh
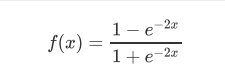
函数图像
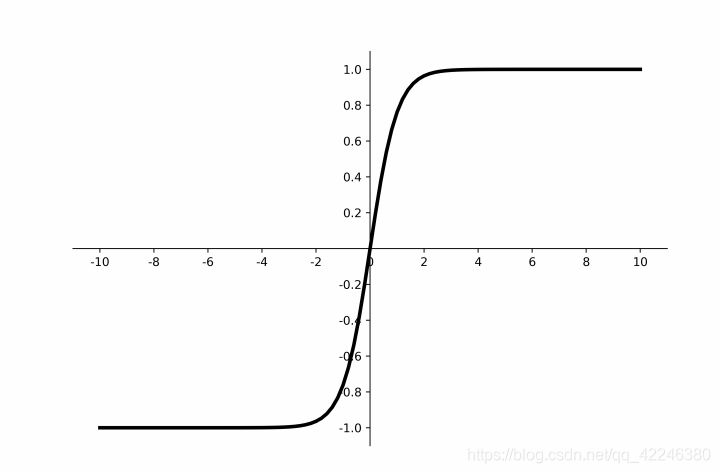
倒数图像
优缺点

3.3 ReLU
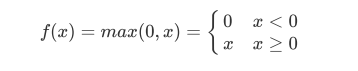
函数图像
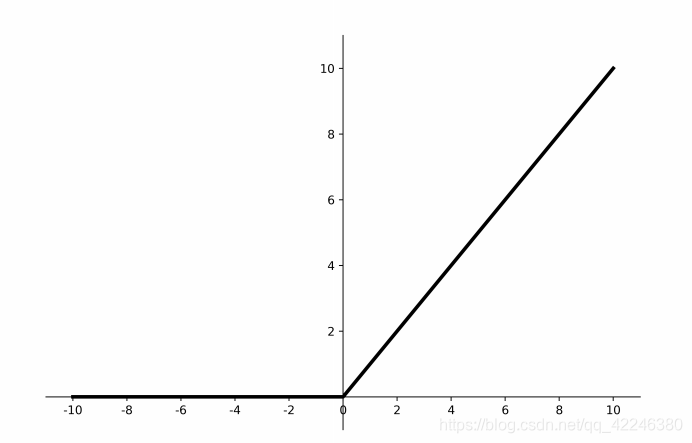
倒数图像
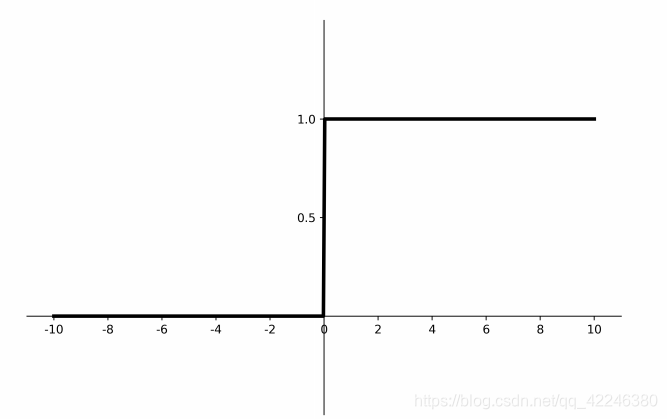
优缺点


3.4 Leaky ReLU
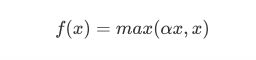
函数图像
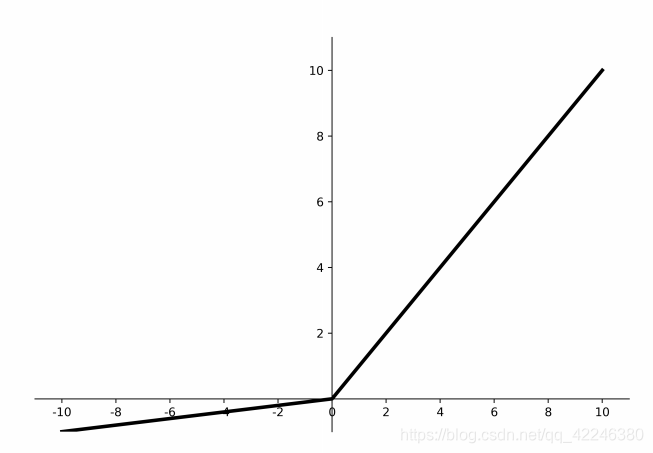
倒数图像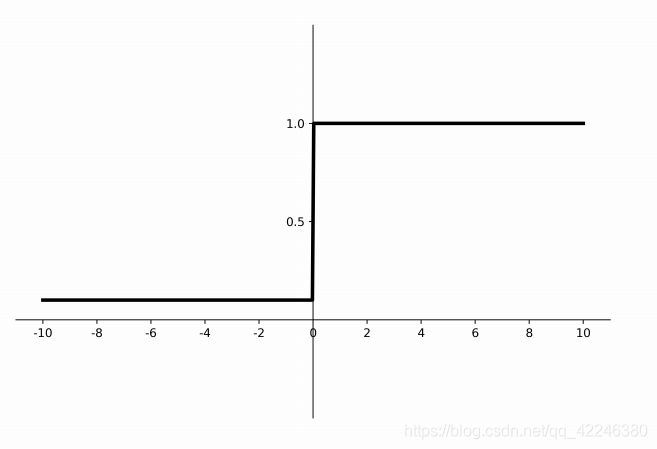
优缺点

3.5 softmax
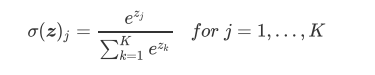
作用
对神经网络全连接层输出进行变换,使其服从概率分布,即每个值都位于[0,1]区间且和为1
3.6 建议

4 损失函数
神经网络模型的效果及优化的目标是通过损失函数来定义的。回归和分类是监督学习中的两个大
类
4.1 均方误差损失函数

4.2 交叉熵损失函数

4.3 自定义损失函数
5 欠拟合与过拟合
欠拟合的解决方法:
增加输入特征项
增加网络参数
减少正则化参数
过拟合的解决方法:
数据清洗
增大训练集
采用正则化
增大正则化参数
6 优化器

6.1 SGD

6.1.1 vanilla SGD 
6.1.2 SGD with Momentum

6.1.3 SGD with Nesterov Acceleration

6.2 AdaGrad

6.3 RMSProp

6.4 AdaDelta
6.5 Adam  6.6 优化器选择
6.6 优化器选择
很难说某一个优化器在所有情况下都表现很好,我们需要根据具体任务选取优化器。一些优化器在
计算机视觉任务表现很好,另一些在涉及RNN网络时表现很好,甚至在稀疏数据情况下表现更出色。
总结上述,基于原始SGD增加动量和Nesterov动量,RMSProp是针对AdaGrad学习率衰减过快
的改进,它与AdaDelta非常相似,不同的一点在于AdaDelta采用参数更新的均方根(RMS)作为分
子。Adam在RMSProp的基础上增加动量和偏差修正。如果数据是稀疏的,建议用自适用方法,即
Adagrad, RMSprop, Adadelta, Adam。RMSprop, Adadelta, Adam 在很多情况下的效果是相似
的。随着梯度变的稀疏,Adam 比 RMSprop 效果会好。总的来说,Adam整体上是最好的选择。
然而很多论文仅使用不带动量的vanilla SGD和简单的学习率衰减策略。SGD通常能够达到最小
点,但是相对于其他优化器可能要采用更长的时间。采取合适的初始化方法和学习率策略,SGD更加可
靠,但也有可能陷于鞍点和极小值点。因此,当在训练大型的、复杂的深度神经网络时,我们想要快速
收敛,应采用自适应学习率策略的优化器。
如果是刚入门,优先考虑Adam或者SGD+Nesterov Momentum。
算法没有好坏,最适合数据的才是最好的,永远记住:No free lunch theorem。
6.7 优化算法的常用tricks
- 首先,各大算法孰优孰劣并无定论。如果是刚入门,优先考虑SGD+Nesterov Momentum或者
Adam.(Standford 231n : The two recommended updates to use are either SGD+Nesterov Momentum or Adam) 2. 选择你熟悉的算法——这样你可以更加熟练地利用你的经验进行调参。 - 充分了解你的数据——如果模型是非常稀疏的,那么优先考虑自适应学习率的算法。
- 根据你的需求来选择——在模型设计实验过程中,要快速验证新模型的效果,可以先用Adam进
行快速实验优化;在模型上线或者结果发布前,可以用精调的SGD进行模型的极致优化。 - 先用小数据集进行实验。有论文研究指出,随机梯度下降算法的收敛速度和数据集的大小的关系
不大。(The mathematics of stochastic gradient descent are amazingly independent of the training set size. In particular, the asymptotic SGD convergence rates are independent from the sample size.)因此可以先用一个具有代表性的小数据集进行实验,测试
一下最好的优化算法,并通过参数搜索来寻找最优的训练参数。 - 考虑不同算法的组合。先用Adam进行快速下降,而后再换到SGD进行充分的调优。
- 充分打乱数据集(shuffle)。这样在使用自适应学习率算法的时候,可以避免某些特征集中出
现,而导致的有时学习过度、有时学习不足,使得下降方向出现偏差的问题。在每一轮迭代后对训
练数据打乱是一个不错的主意。 - 训练过程中持续监控训练数据和验证数据上的目标函数值以及精度或者AUC等指标的变化情况。
对训练数据的监控是要保证模型进行了充分的训练——下降方向正确,且学习率足够高;对验证数
据的监控是为了避免出现过拟合。 - 制定一个合适的学习率衰减策略。可以使用分段常数衰减策略,比如每过多少个epoch就衰减一
次;或者利用精度或者AUC等性能指标来监控,当测试集上的指标不变或者下跌时,就降低学习
率。 - Early stopping。如Geoff Hinton所说:“Early Stopping是美好的免费午餐”。你因此必须在训
练的过程中时常在验证集上监测误差,在验证集上如果损失函数不再显著地降低,那么应该提前结
束训练。 - 算法参数的初始值选择。 初始值不同,获得的最小值也有可能不同,因此梯度下降求得的只是局
部最小值;当然如果损失函数是凸函数则一定是最优解。由于有局部最优解的风险,需要多次用不
同初始值运行算法,关键损失函数的最小值,选择损失函数最小化的初值。

















 9418
9418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









