




 本文介绍了k近邻(kNN)算法的基本思想,包括使用训练集中的k个最近邻进行分类决策。讨论了距离度量、k值选择对结果的影响,并强调了特征归一化的重要性,如线性函数归一化和零均值归一化,以提高模型精度和收敛速度。
本文介绍了k近邻(kNN)算法的基本思想,包括使用训练集中的k个最近邻进行分类决策。讨论了距离度量、k值选择对结果的影响,并强调了特征归一化的重要性,如线性函数归一化和零均值归一化,以提高模型精度和收敛速度。
概述
k近邻是一种简单的分类、回归方法,于1968年提出。这里简要介绍k近邻的思想。
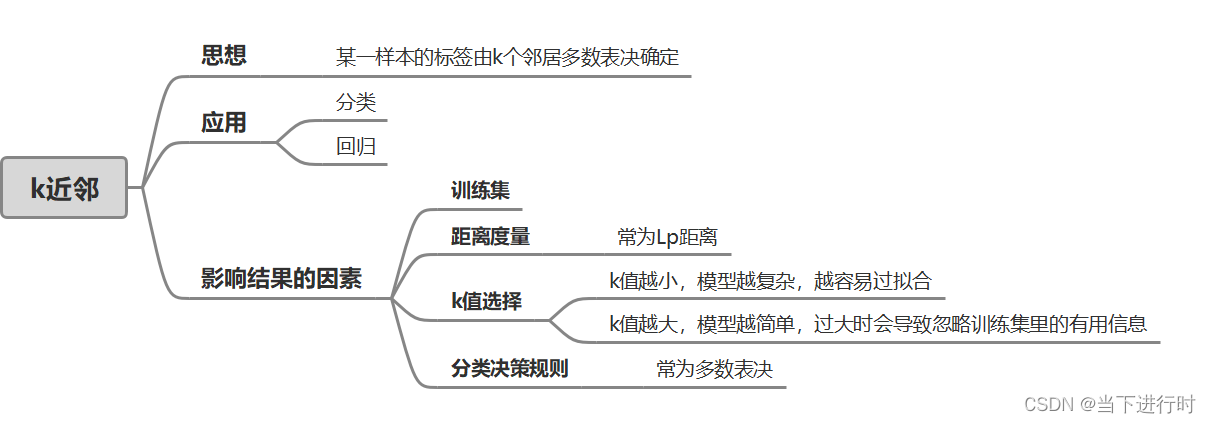
一、k近邻的思想
给定一个打好标签的训练集,对一个新的样本,在训练集中找到离
最近的k个邻居样本,这k个样本中多数属于的那个类就作为
的类。
k近邻这种多数表决的思想并么有一个显式的学习过程。而且k近邻只是简单地对训练数据进行了“记忆”,基于训练集对特征空间进行划分,属于非泛化的机器学习方法。
这里给出一个二维空间下,k=3的分类例子:

训练数据集里共有红色和蓝色两类样本,当要给一个未知的样本(绿色星星)进行分类时,选取特征空间中离它最近的三个样本,即两个红色样本和一个蓝色样本,少数服从多数,这个未知样本就被归类为红色。
二、影响k近邻结果的因素
&n
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2639
2639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









