






 本文深入剖析YOLOv1算法,一种实时目标检测的One-stage算法,对比faster-rcnn,强调其在帧数上的优势。文章详细解读YOLOv1的网络结构、滑动窗口策略、损失函数改进及训练细节。
本文深入剖析YOLOv1算法,一种实时目标检测的One-stage算法,对比faster-rcnn,强调其在帧数上的优势。文章详细解读YOLOv1的网络结构、滑动窗口策略、损失函数改进及训练细节。
算法介绍
我最近一直在看YOLOv1算法,通过论文博客,大概花了一周左右深入理解这个算法的思想。
YOLOv1是典型的One-stage算法,出现在faster-rcnn之后,为了解决目标检测算法实时性问题,以下是该算法与其他算法的性能对比:
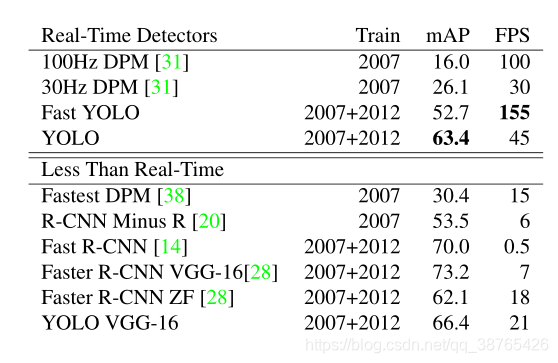
虽然YOLOv1算法的mAP不如faster-rcnn,可是帧数比faster-rcnn高不少,而且快速版本的YOLOv1帧数更是高达155。
下面是yolov1误差分析:
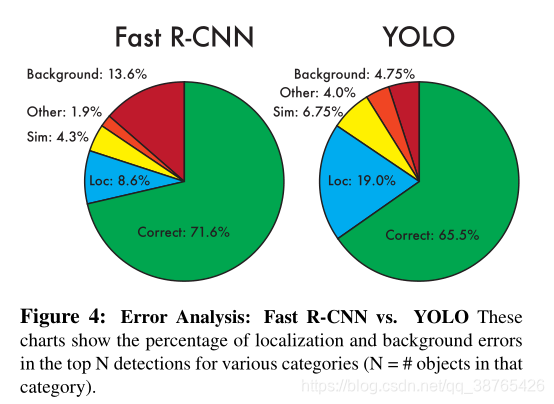
faster-rcnn对于背景的误判比YOLOv1严重的多,而对于位置的误差刚好相反。
算法分析
-
思想分析
YOLOv1算法是优秀的目标检测算法,思路是通过end-to-end网络。
输入图片的大小为448x448x3 ,经过滑动窗口后变成7x7的区域,每个区域有两个bounding boxes,如果目标的中心在7x7=49个子区域内中的一个,那么那个子区域就用来单独预测这个目标,这也造成了一个缺陷,因为每个子区域只有两个bounding boxes,所以最多预测两个目标,整张图片只能预测772=98个目标。 -
结构分析
YOLOv1算法采用了与VGG类似的结构,以下是结构信息:
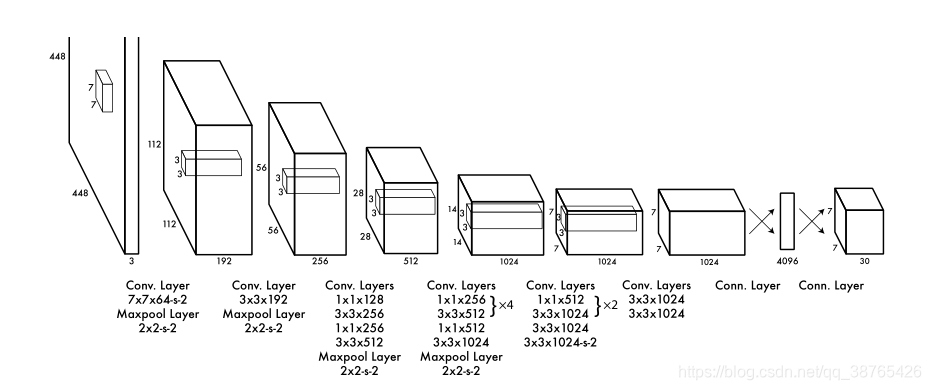
原作者是ImageNet分类任务中,用一半的分辨率进行预训练,所以输入图片为224x224x3的图片,先经过64个7x7的卷积层,然后经过2x2最大池化层(Max-pooling),输出结果为112x112x64的特征图片。解释一下为什么是112x112x64图片:
输入时224x224x3,经过64个7x7的卷积层,特征图就会变成224x224x64,也就是224x224x192,经过2x2的池化层,则输出的结果为112x112x64。关于卷积操作我一开始不是很理解,后来明白了。卷积时,一个卷积核会对每一层都进行卷积操作,然后相加,最后取激活函数得到的,最后生成一张特征图。所以有多少个卷积核特征图就有多少层。详细情况请看张雨石大佬博客,发布于2014-11-29 16:20:41
神经网络然后经过3x3x192卷积层,经过2x2的最大池化层后输出56x56x 192的特征图。然后就是一步步的卷积,在这就不复述了。
在这里解释一下为什么要加入1x1的卷积层。论文中说交替的1x1卷积层是为了减少前一层的特征空间。还有一个作用是可以跨通道的交互和信息整合。详细情况如下
1x1卷积核的作用经过一系列的卷积层处理得到7x7x1024的特征图。后面衔接了一个4096的全链接层后,最后输出的是一个7x7 x30个向量的网络。7x7代表的是7x7个滑动窗口,每个滑动窗口有30个参数,分别代表着
参数1-4:中心点x1,y1 长宽w1,h1
参数5 :置信度1
参数6-9:中心点x2,y2 长宽w2,h2
参数10:置信度2
参数11-30:20个种类
也就是YOLOv1算法每个滑动窗口只能预测两个目标,一共预测7* 7 *2=98个目标。
算法思想
写到这里大家一定还是特别懵逼,为啥输入的图片经过这么一系列网络就输出7x7x30的输出,每个输出就可以预测目标了。
所以我来说一下这个算法的思想,我们做目标检测,无非就两步:
1.目标捕捉
2.目标特征提取及识别
前者目标捕捉有很多方法,YOLOv1算法使用的是滑动窗口策略,而rcnn是采用的ss算法。
后者目标特征提取及识别就是卷积层和全连接层来实现的。
先讲一下滑动窗口策略,首先对输入图像 进行不同窗口大小的滑窗由左到到右,由上到下的滑动。每次滑动的时候对当前滑窗执行分类器,进行判断。如果该窗口有比较大的分类概率,就认为检测得到了目标。对不同的滑动窗口进行检测后,我们会得到不同滑窗的物体标记,这些滑窗会出现很多重叠部分,最后采用非极值抑制(Non-Maximum Suppression,NMS)进行筛选,最终经过NMS后获得检测的物体。
滑动窗口策略理论上取足量的滑动窗口进行分类,就能够获得目标图片所有的目标物体,但是他存在致命的缺陷,就是运算速度太慢了,设想一下每个滑动窗口都要进行一次分类器,为了取得所有输入图像的目标,我们会进行大量的大小互异滑动窗口遍历,然后进行神经网络运算,所需要的时间会根据图像大小爆炸式增加。
YOLOv1算法并没有采取这样的滑动窗口的策略,而是采取了类似的滑动窗口策略。讲这个之前我先要说一下卷积神经网络的平移不变性,简单来说卷积加池化等于平移不变性。
举个小例子,输入图片左下角有一个人脸,经过卷积后,人脸的特征(眼睛,鼻子)也位于特征图的左下方。
然后我们说一下感受野,看下面这张图
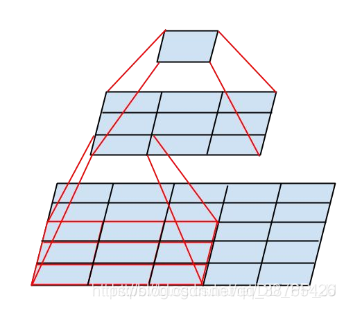
由图可知,我们对输入图像进行3x3的卷积操作,在他的特征图(feacture map)上每个值对应的是下面9个值进行卷积操作的和,也就是经过3x3卷积操作后,这一层特征图所对应的感受野就是3x3,如果由两个卷积核堆叠起来的的话,由图可知感受野为5x5,也就是最上面那张1x1的特征图融合了5x5图像的特征。
下面是感受野在训练中的变化情况

感受在平面中并不是平均分布的,而是以中心点进行发散,对中间的特征提取强,而对边缘特征提取弱。
介绍完卷积神经网络不变性和感受野后,我们来正式了解一下作者的滑动窗口策略。
作者设计了一个24层卷积层和两个全连接层的网络,24层卷积网络用于特征提取,而两层全链接网络用于特征提取后分类。由卷积神经网络平移不变性可知,最后一层卷积输出的是7x7x1024的特征图与原图一一对应,相当于对原图进行7x7的切分,由于卷积操作感受野可知,提取的特征并不是单独的每个区域,而是以每个区域为中心发散提取特征,提取的区域比传统滑动窗口要大得多。
YOLOv1算法仅仅只需要进行一次运算就可以提取完特征,而传统的滑动窗口每滑动一次就需要经过一次分类器。
ss算法我就不说了
然后将3x3x1024分别连接全链接层,进行分类训练,最后生成7x7x30的结构,每个参数代表的意思我在上文已经说了。
重要补充
我已经大概说了一下整个算法的结构和思想,在这里补充一下其他的小细节。
激活函数:
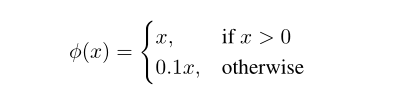
没啥好说的。
我们着重看一下损失函数

作者对于损失函数进行了改进,一共分为三个部分
第一部分:
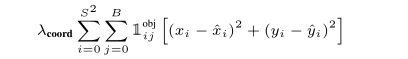
这是位置的损失函数,使用了sum-squared 损失函数
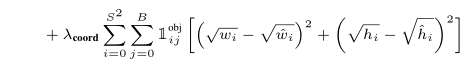
这是目标长宽的损失函数,为什么不也选择sum-squared损失函数呢?
而在损失函数内加根号,这是因为sum-squared损失函数在大的boxes
和小的boxes的作用是一样的,但是大的boxes的小误差可能比小的boxes大误差更大,这会导致对于小的boxes预测偏差很大。为了解决这个问题引入平方根。如下图
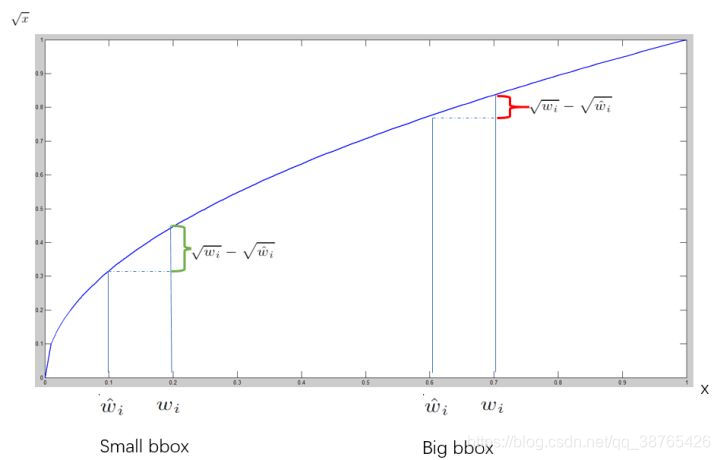
由上图可知,对于该损失函数对于大的boxes位置信息的抑制力比小的boxes的抑制能力更强,从而加强对于小boxes的预测精度。
由于很多cell里面并没有目标,所以confidence会置零,这会导致压倒含有目标的cell的梯度。这会导致模型不稳定,从而导致训练前期发散。为了处理这样的状况,我们增加目标框的预测的损失函数,减少不包含物体的boxes的置信度预测的损失函数
所以我们取coord为5,而noobj为0.5
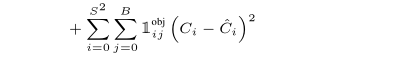
代表的是有object的boxes的confidence的损失函数
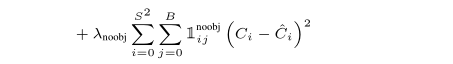
代表着不含有object的boxes的confidence
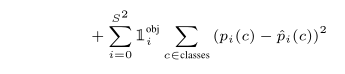
代表着种类预测的损失函数
一个网格预测多个box,希望的是每个box predictor专门负责预测某个object。具体做法就是看当前预测的box与ground truth box中哪个IoU大,就负责哪个。这种做法称作box predictor的specialization。
下面这句话来自于原论文。


如果是的话值就为1,不是的话那么值为0。
大概就怎么回事,我也是第一次学,可能依然有些地方理解的不够透彻,或者理解有错误。希望能指正!
博客里面有部分引用图解YOLOv1
如果还是不解可以看这个大佬的论文!

















 9235
9235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









