







 本文档介绍了企业级Hadoop大数据平台中HDFS的分布式实现,包括搭建多节点实验环境,讨论节点伸缩的重要性,详细阐述在线添加节点的步骤,以及HDFS保证数据安全的机制。内容涵盖Hadoop的容错性、高吞吐量特性和分布式处理的优势,同时提及了HDFS的副本策略、安全模式和权限管理。
本文档介绍了企业级Hadoop大数据平台中HDFS的分布式实现,包括搭建多节点实验环境,讨论节点伸缩的重要性,详细阐述在线添加节点的步骤,以及HDFS保证数据安全的机制。内容涵盖Hadoop的容错性、高吞吐量特性和分布式处理的优势,同时提及了HDFS的副本策略、安全模式和权限管理。
#1 搭建实验环境
实验环境:rhel7.5
| 主机信息 | 作用 |
|---|---|
| server5(172.25.8.5) | Namenode(master) |
| server6(172.25.8.6) | Datanode(slave) |
| server7(172.25.8.7) | Datanode(slave) |
| 真机(172.25.8.250) | 测试 |
Hadoop篇章的第二篇实现了单机版的hadoop分布式文件系统,接下来在多个节点上实现;
hadoop的分布式的实现是为了:将其Datanode与Namenode分离开;
#1 创建两个新的快照,并且用真机连接
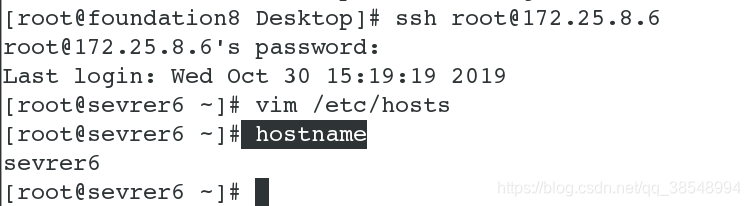
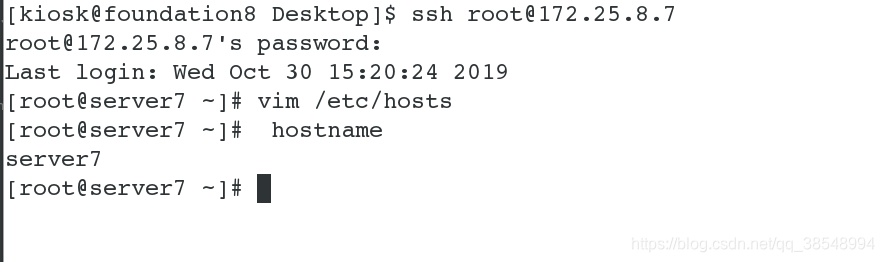
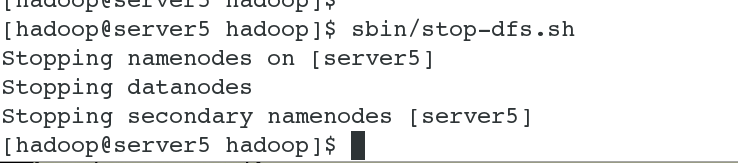
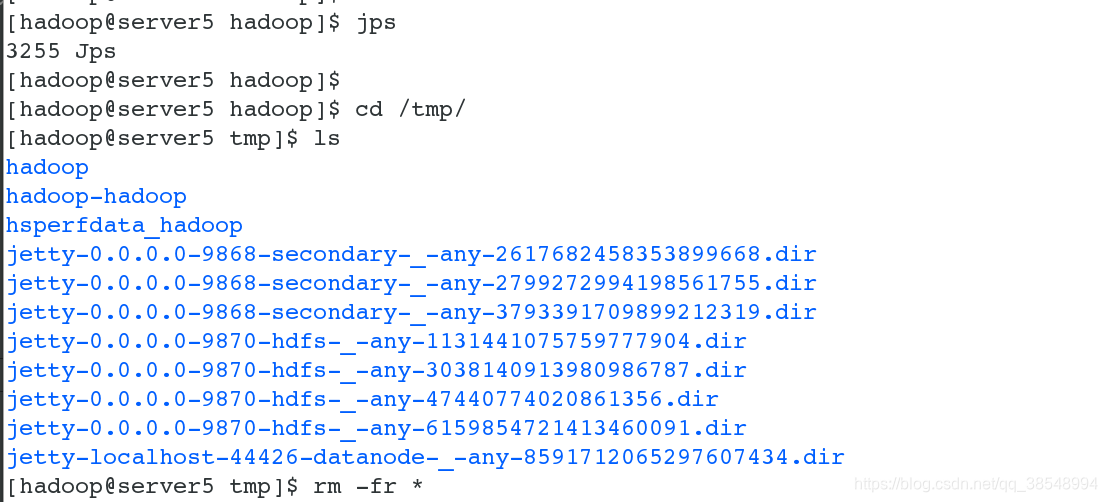
#2 首先关闭dfs服务,并且删除之前生成文件

#3 在三个节点上均安装nfs服务并且开启服务







#4 在server5上(master节点)上配置nfs服务,设置共享目录,并且开启服务(nfs服务已经在第二步已经开启了)



<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









