







1.基础知识
Hadoop的架构
核心,Hadoop主要有两个层次,即:加工/计算层(MapReduce)和存储层(Hadoop分布式文件系统)
除了上面提到的两个核心组件,Hadoop的框架还包括以下两个模块:
Hadoop通用:这是Java库和其他Hadoop组件所需的实用工具
Hadoop YARN :这是作业调度和集群资源管理的框架
Hadoop Streaming 是一个实用程序,它允许用户使用任何可执行文件(例如shell实用程序)作为映射器和/或reducer创建和运行作业
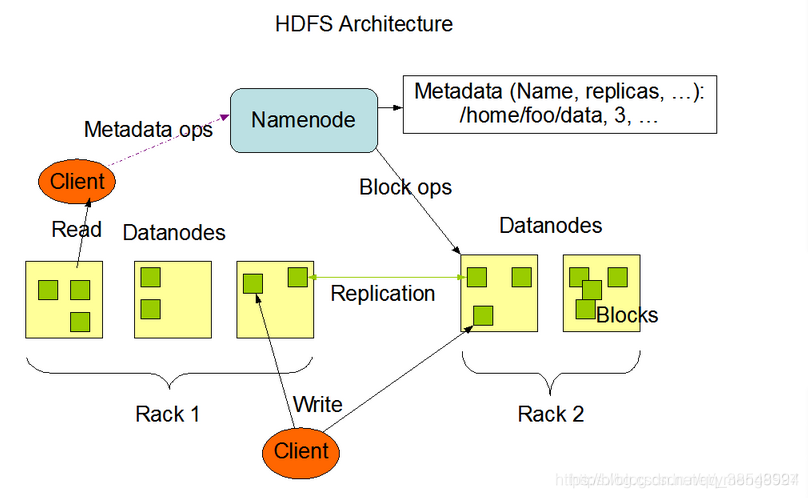
上图中展现了整个HDFS三个重要角色:NameNode、DataNode和Client
NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等
NameNode会将文件系统的Meta-data存储在内存中
这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等
DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data
同时周期性地将所有存在的Block信息发送给NameNode。Client就是需要获取分布式文件系统文件的应用程序





#2 搭建实验环境
实验环境:rhel7.5
| 主机信息 | 作用 |
|---|---|
| server1(172.25.8.5) | hadoop |
| 真机(172.25.8.250) | 测试 |
#1 在真机上重新创建一个快照并且导入,保证实验环境干干净净
[root@foundation8 images]# qemu-img create -f qcow2 -b rhel7.5-1.qcow2 hadoop1
#2 用真机连接server5
#3 从真机上给server1发送jdk和hadoop的安装包
Hadoop是Java开发的,因此需要在服务器上安装相对应的JDK
ps:Linux默认自带JDK–openJDK–>Hadoop集群千万不要使用这个
将hadoop安装包上传到服务器
ps:实际开发中如需要其他安装包,请去官网下载

到此为止,基本的实验环境已经搭建完毕
#3 搭建单机版实现过程:
1.查看安装包是否被发送过来

2.创建一个hadoop用户
将其hadoop相关安装包都放在hadoop用户家目录下


3.解压压缩包,并且做软连接方便操作
#切换用户



4.编写环境变量

#5 写入java命令绝对路径方便命令使用
#使更改生效
[hadooop@server5 ~]# source .bash_profile
显示当前所有java进程pid的命令
[hadoop@server5 bin]# pwd
/home/hadoop/java/bin
[hadoop@server5 bin]# jps
1124 Jps
编辑文件,声明java
hadoop对应目录

ps:hadoop1.x版本是没有 yarn hadoop2.x之后提供的yarn
[hadoop@server5 bin]# cd ../../hadoop/etc/hadoop
[hadoop@server5 hadoop]# vim hadoop-env.sh





独立操作debug,运行了一个程序




到此为止,基本的单机版搭建已经完毕,接下来实现伪分布式的搭建
#4.搭建伪分布式的实现过程:
#1 创建一个用户和设置密码

[root@server5 ~]# su - hadoop
[hadoop@server5 ~]#
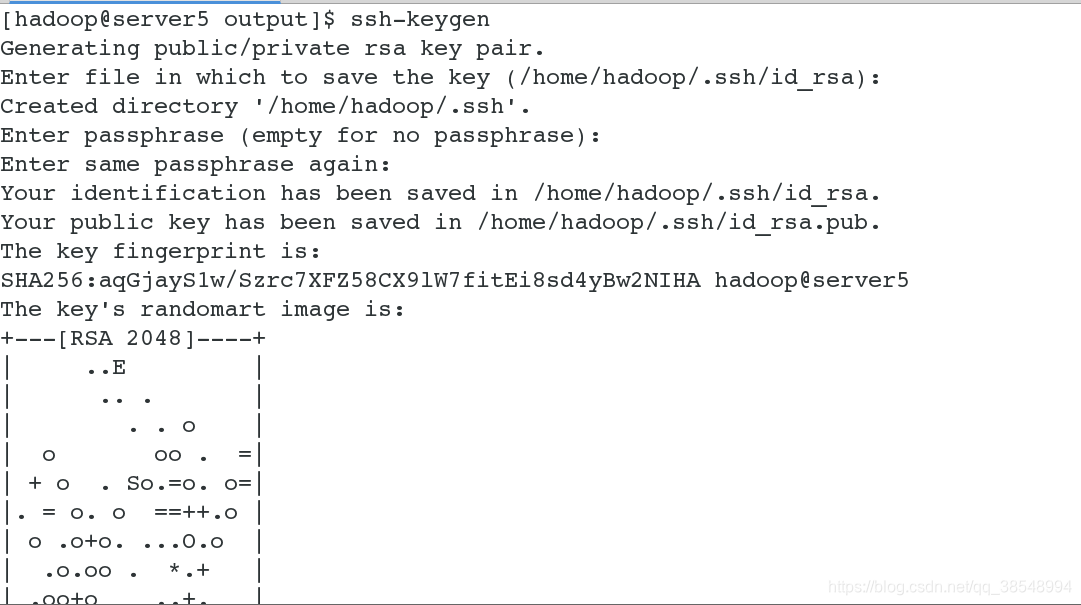
#2 做本机的免密,因为此时的伪分布式也是在一台节点上实现的
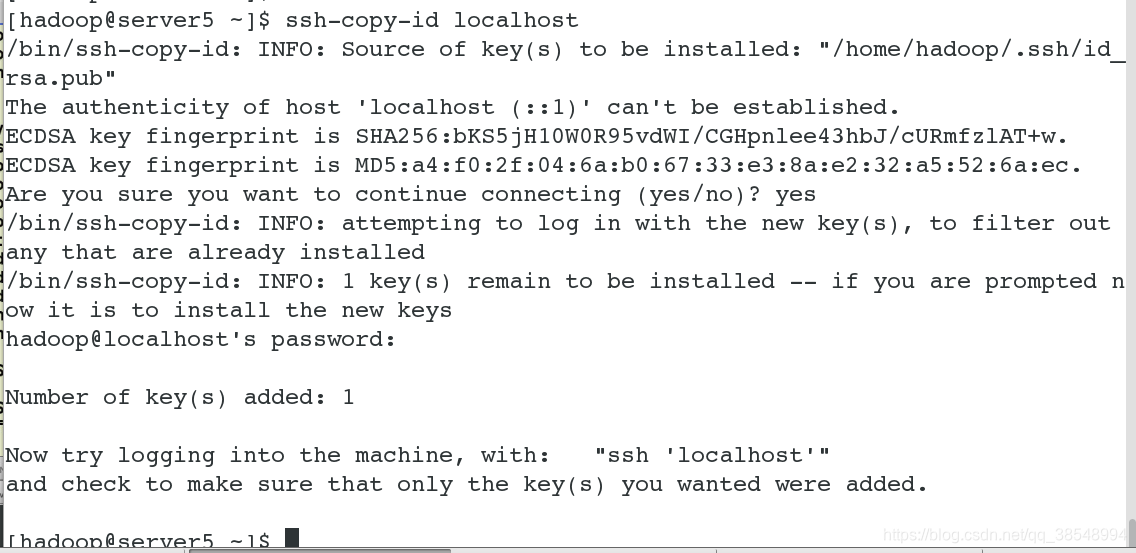
#3验证免密是否成功
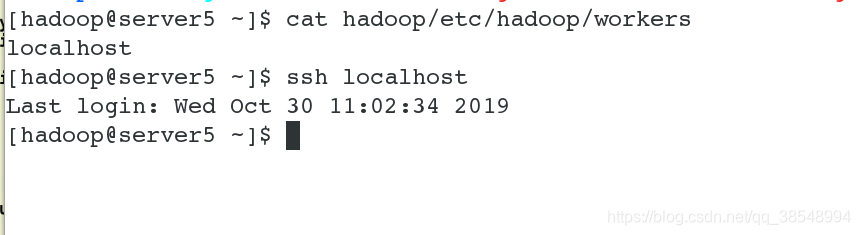
#4 此时的workers文件里面既可以写localhost,也可以写ip地址
为了后续实验方便,在这里我写ip地址

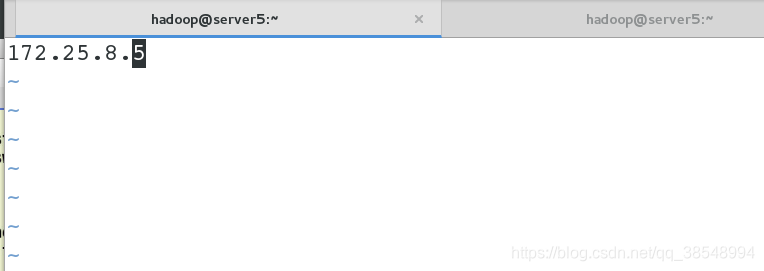
#5 设置slave节点为本机


#6 设置副本个数为1,因为此时只有本机一个节点开启datanode进程

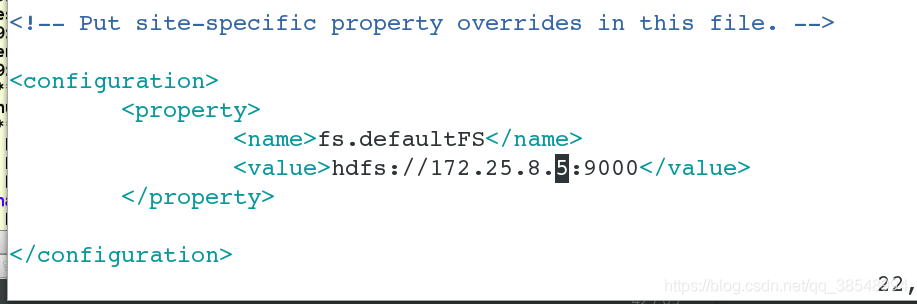
[hadoop@server5 hadoop]$ vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>http://172.25.8.5:9000</value>
</property>
</configuration>
#7 初始化


#8 可以发现,初始化之后会在/tmp这个目录下面生成一些临时目录以及进程的pid文件

#9 开启服务

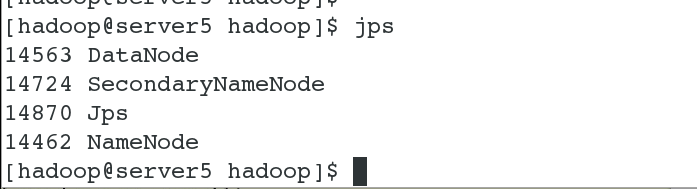
#10 此时datanode和namenode进程均开启在本节点上
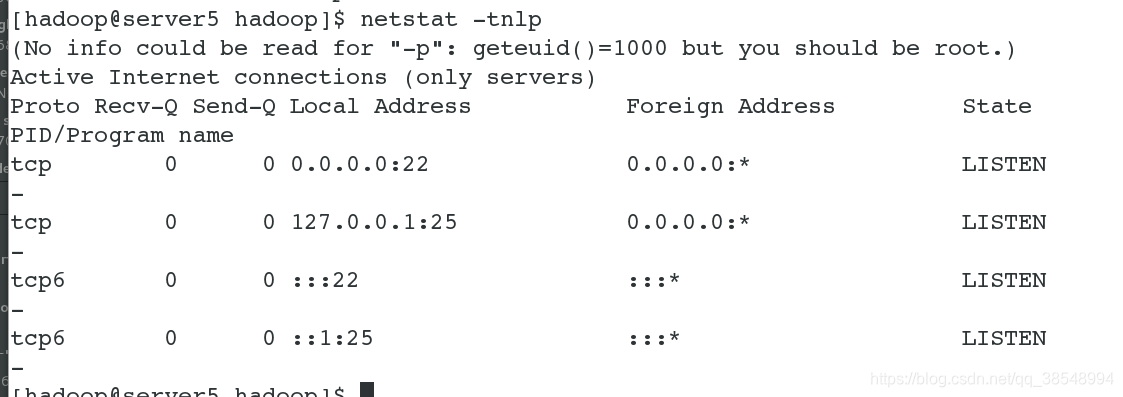
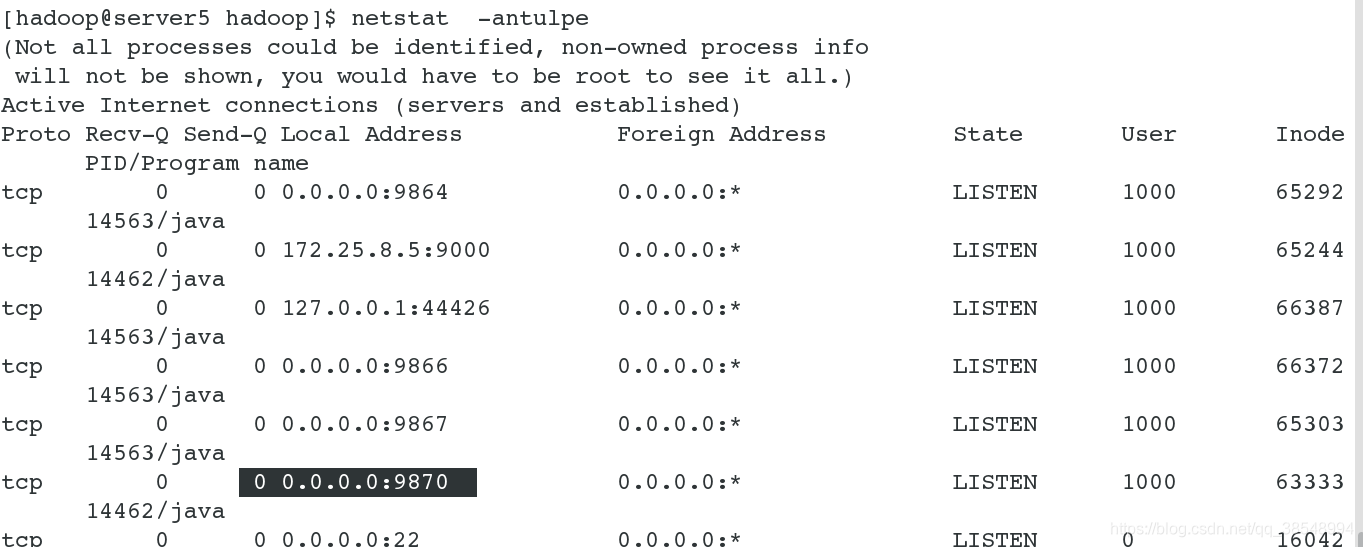
#11 查看端口的开启情况
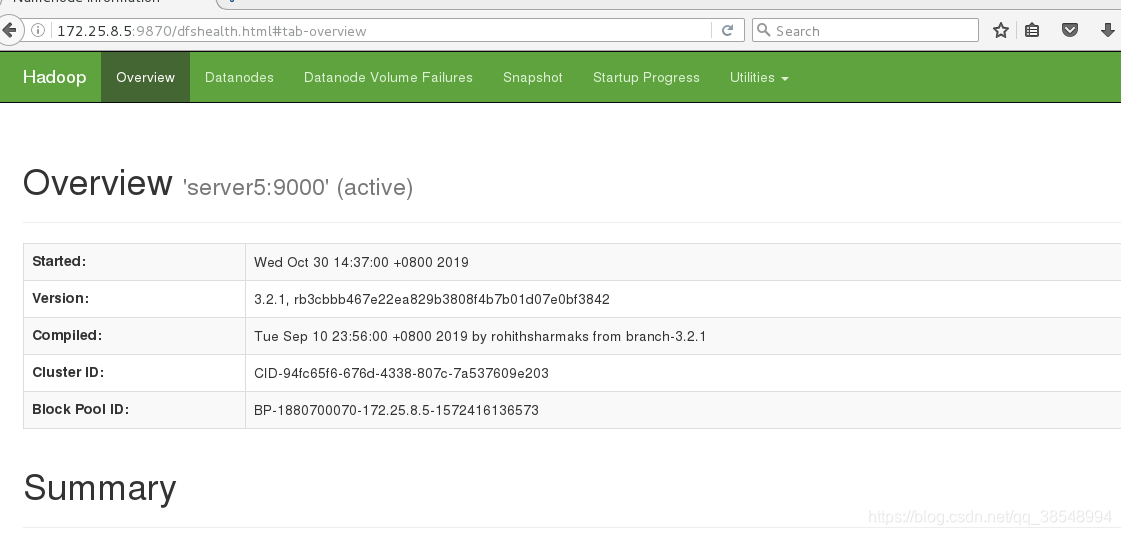
#12 测试,在真机上做好解析之后进行测试,在浏览器上输入:172.25.8.5:9870
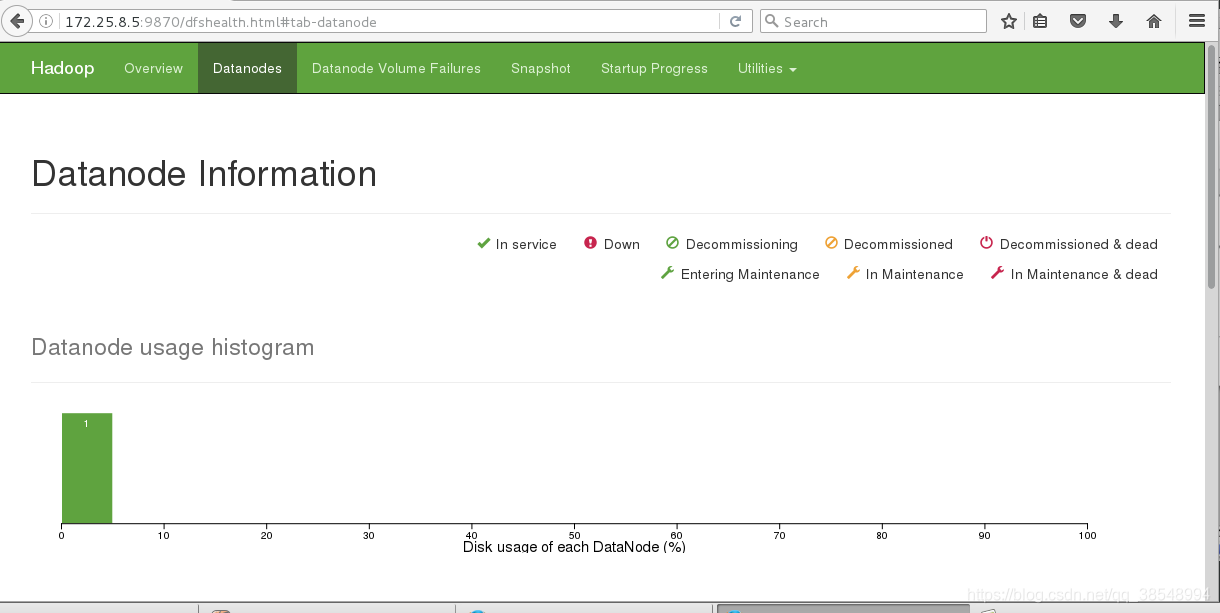
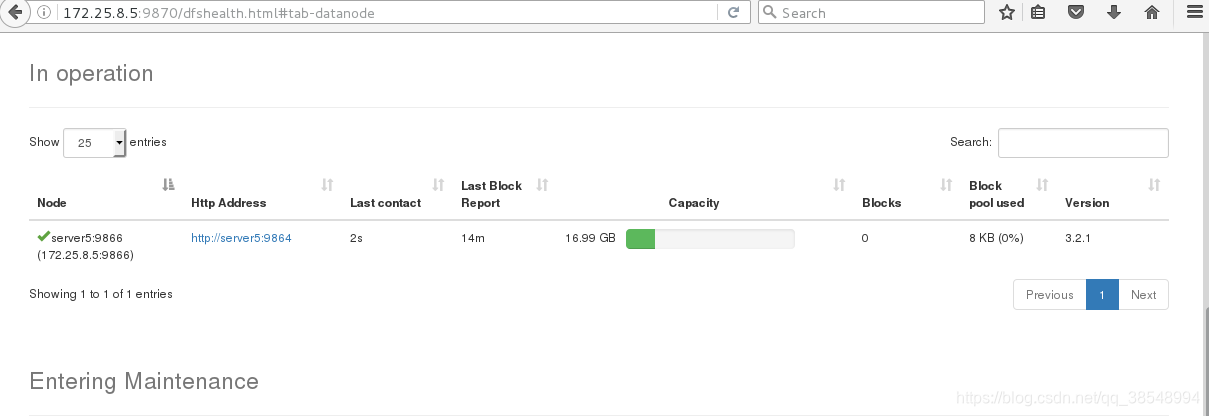
#13查看一些主机的信息,在线还是不在线

#14 建立数据目录,上传数据
[hadoop@server5 hadoop]$ bin/hdfs dfs -mkdir -p /user/hadoop #创建/user/hadoop目录
[hadoop@server5 hadoop]$ bin/hdfs dfs -put input #将input文件进行上传
[hadoop@server5 hadoop]$ bin/hdfs dfs -ls input
[hadoop@server5 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount input output
[hadoop@server5 hadoop]$ bin/hdfs dfs -cat output/*
[hadoop@server5 hadoop]$ bin/hdfs dfs -get output

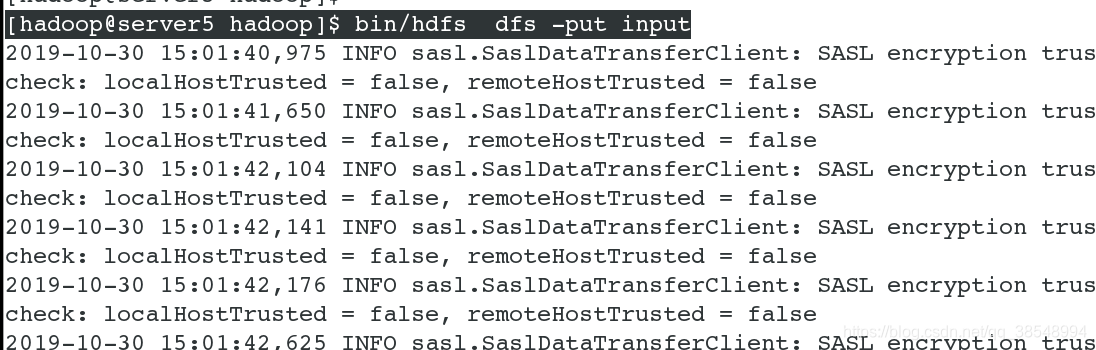
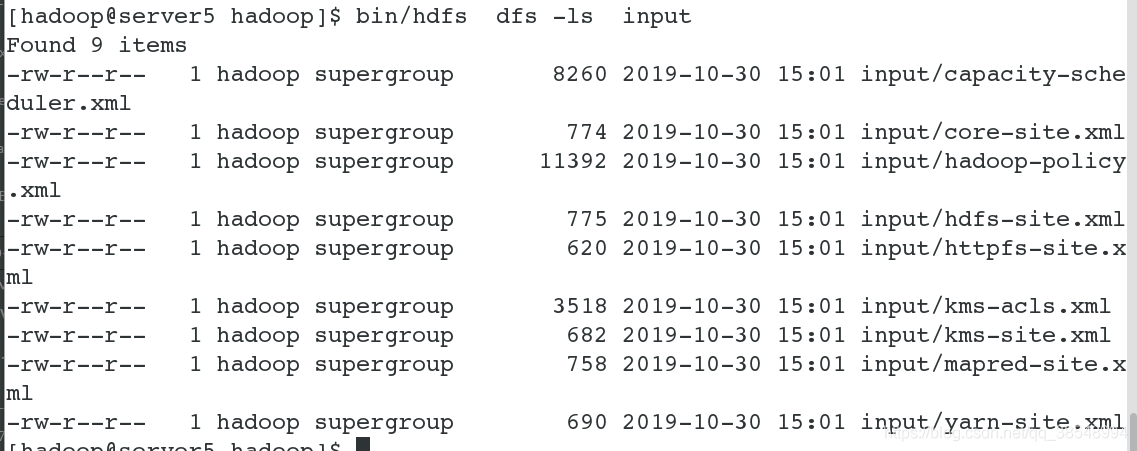
#15 在浏览器里面可以看到刚刚上传上去的文件
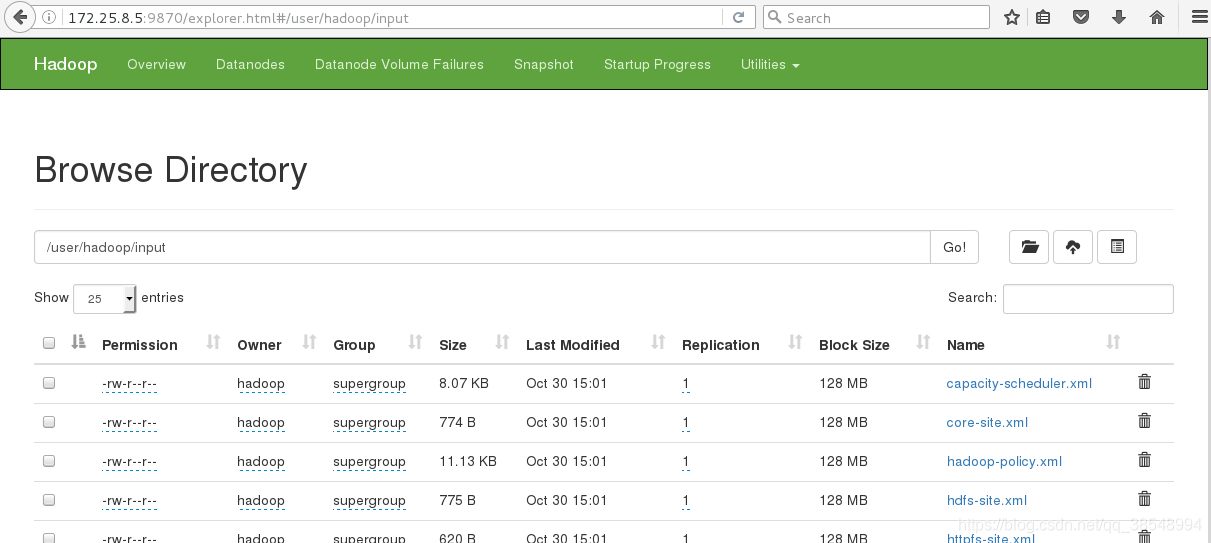
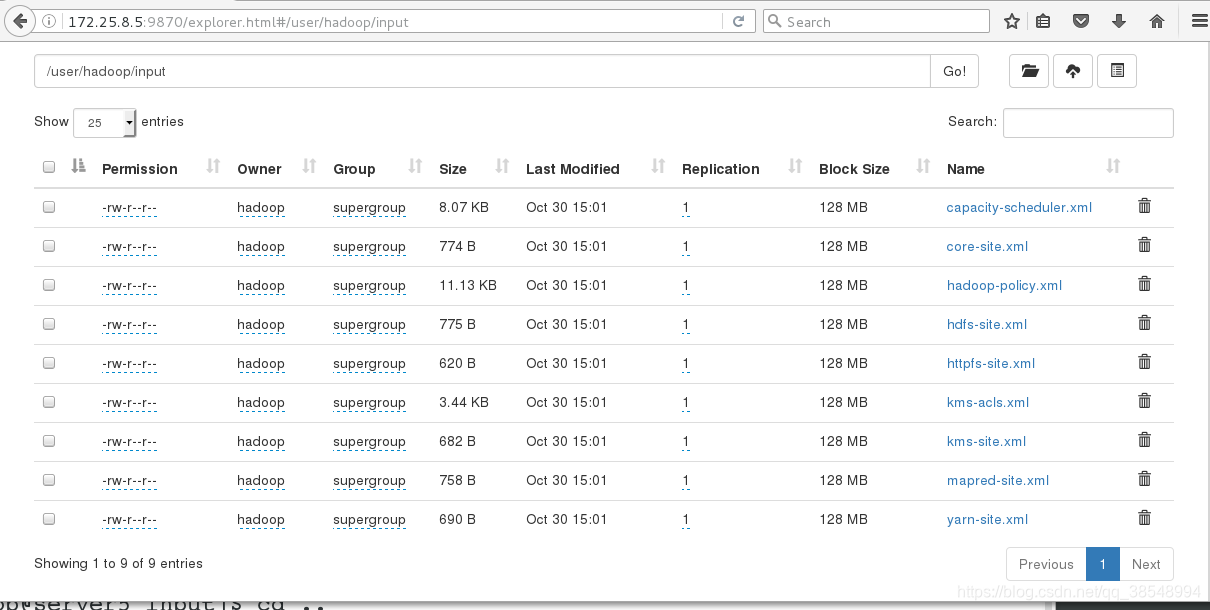
在图形化界面里面直接删除,因为没有文件的权限,无法删除
#删除配置文件,对于浏览器的查看毫无影响

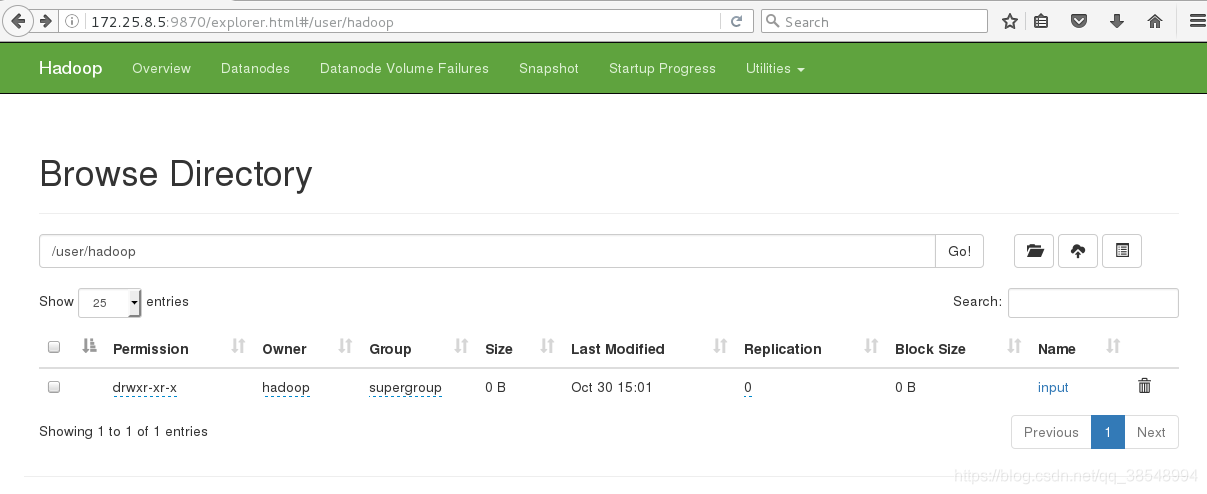
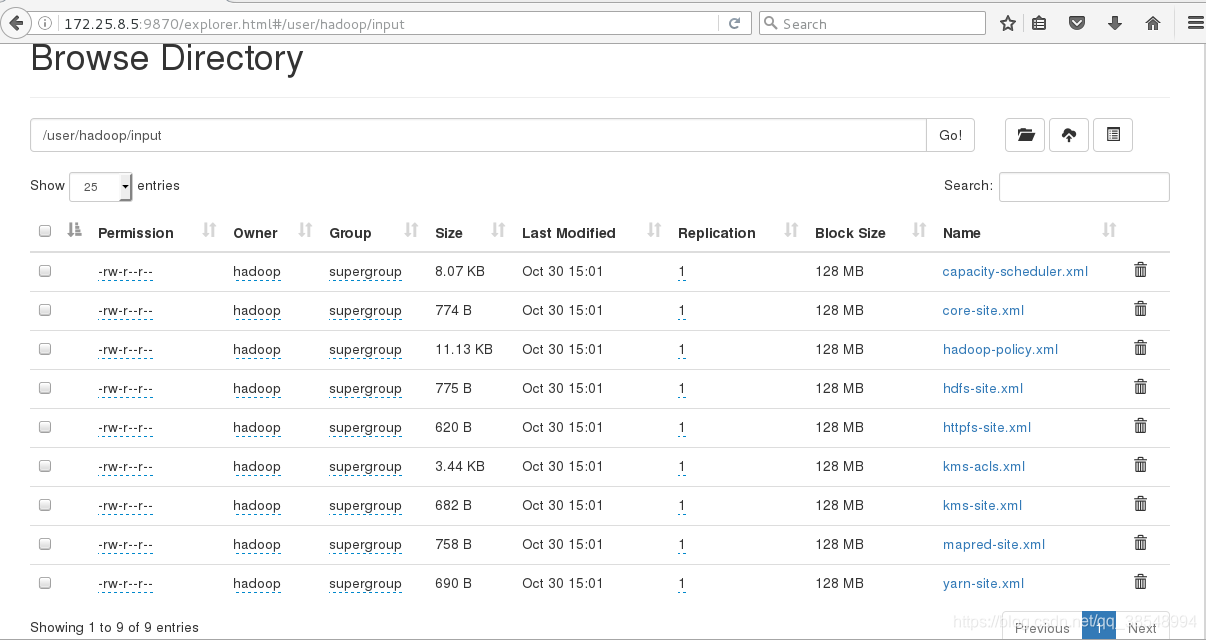
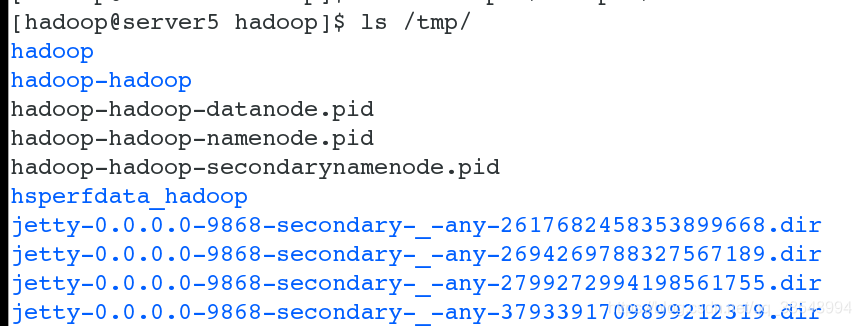
#15 创建上传input output


#测试: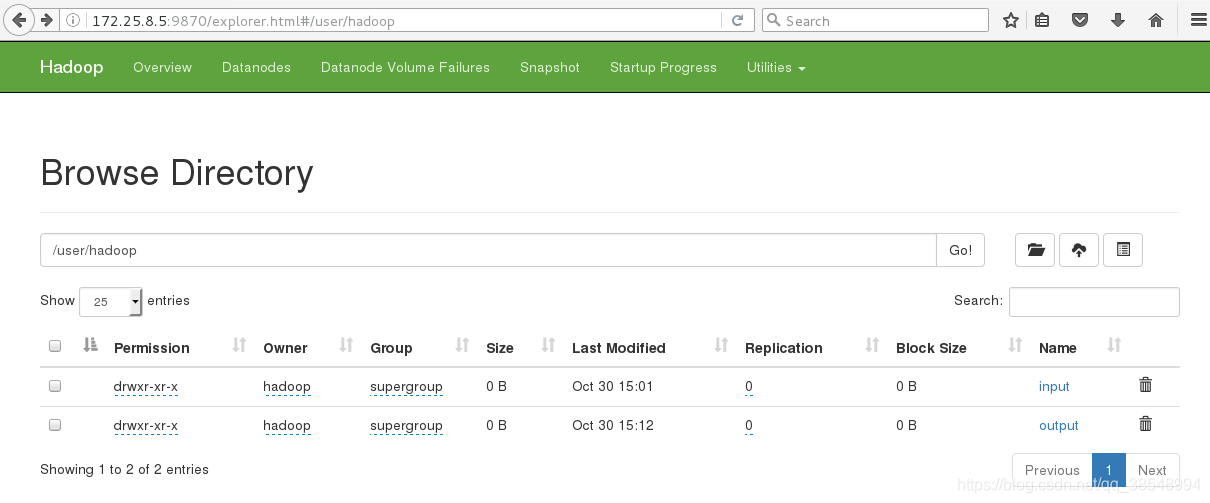
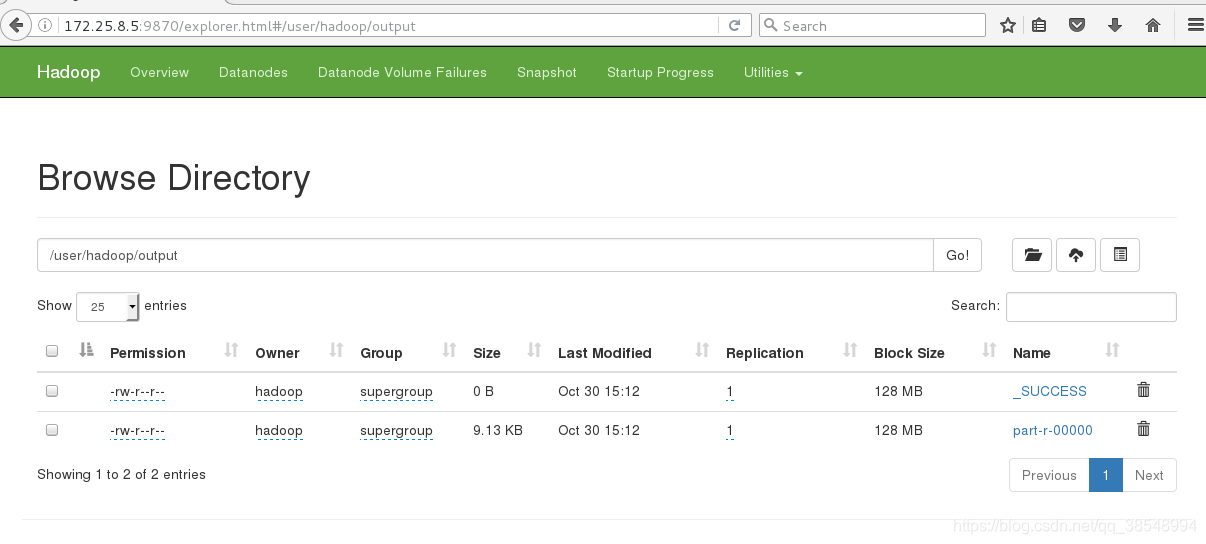



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









