







hook_fn(module, grad_input, grad_output) -> Tensor or None
它的输入变量分别为:模块,模块输入端的梯度,模块输出端的梯度。需要注意的是,这里的输入端和输出端,是站在前向传播的角度的,而不是反向传播的角度。例如线性模块:o=W*x+b,其输入端为 W,x 和 b,输出端为 o。
如果模块有多个输入或者输出的话,grad_input和grad_output可以是 tuple 类型。对于线性模块:o=W*x+b ,它的输入端包括了W、x 和 b 三部分,因此 grad_input 就是一个包含三个元素的 tuple。
这里注意和 forward hook 的不同:
1.在 forward hook 中,input 是 x,而不包括 W 和 b。
2.返回 Tensor 或者 None,backward hook 函数不能直接改变它的输入变量,但是可以返回新的 grad_input,反向传播到它上一个模块。
Talk is cheap,下面看示例代码:
import torch
from torch import nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.fc1 = nn.Linear(3, 4)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(4, 1)
self.initialize()
def initialize(self):
with torch.no_grad():
self.fc1.weight = torch.nn.Parameter(
torch.Tensor([[1., 2., 3.],
[-4., -5., -6.],
[7., 8., 9.],
[-10., -11., -12.]]))
self.fc1.bias = torch.nn.Parameter(torch.Tensor([1.0, 2.0, 3.0, 4.0]))
self.fc2.weight = torch.nn.Parameter(torch.Tensor([[1.0, 2.0, 3.0, 4.0]]))
self.fc2.bias = torch.nn.Parameter(torch.Tensor([1.0]))
def forward(self, x):
o = self.fc1(x)
o = self.relu1(o)
o = self.fc2(o)
return o
total_grad_out = []
total_grad_in = []
def hook_fn_backward(module, grad_input, grad_output):
print(module) # 为了区分模块
# 为了符合反向传播的顺序,我们先打印 grad_output
print('grad_output', grad_output)
# 再打印 grad_input
print('grad_input', grad_input)
# 保存到全局变量
total_grad_in.append(grad_input)
total_grad_out.append(grad_output)
model = Model()
modules = model.named_children()
for name, module in modules:
module.register_backward_hook(hook_fn_backward)
# 这里的 requires_grad 很重要,如果不加,backward hook
# 执行到第一层,对 x 的导数将为 None,某英文博客作者这里疏忽了
# 此外再强调一遍 x 的维度,一定不能写成 torch.Tensor([1.0, 1.0, 1.0]).requires_grad_()
# 否则 backward hook 会出问题。
x = torch.Tensor([[1.0, 1.0, 1.0]]).requires_grad_()
o = model(x)
o.backward()
print('==========Saved inputs and outputs==========')
for idx in range(len(total_grad_in)):
print('grad output: ', total_grad_out[idx])
print('grad input: ', total_grad_in[idx])
运行后的输出为:
Linear(in_features=3, out_features=4, bias=True) input (tensor([[1., 1., 1.]], requires_grad=True),) output tensor([[ 7., -13., 27., -29.]], grad_fn=<AddmmBackward>) ReLU() input (tensor([[ 7., -13., 27., -29.]], grad_fn=<AddmmBackward>),) output tensor([[ 7., 0., 27., 0.]], grad_fn=<ThresholdBackward0>) Linear(in_features=4, out_features=1, bias=True) input (tensor([[ 7., 0., 27., 0.]], grad_fn=<ThresholdBackward0>),) output tensor([[89.]], grad_fn=<AddmmBackward>) ==========Saved inputs and outputs========== input: (tensor([[1., 1., 1.]], requires_grad=True),) output: tensor([[ 7., -13., 27., -29.]], grad_fn=<AddmmBackward>) input: (tensor([[ 7., -13., 27., -29.]], grad_fn=<AddmmBackward>),) output: tensor([[ 7., 0., 27., 0.]], grad_fn=<ThresholdBackward0>) input: (tensor([[ 7., 0., 27., 0.]], grad_fn=<ThresholdBackward0>),) output: tensor([[89.]], grad_fn=<AddmmBackward>)
读者可以自己用笔算一遍,验证正确性。需要注意的是,对线性模块,其grad_input 是一个三元组,排列顺序分别为:对 bias 的导数,对输入 x 的导数,对权重 W 的导数。
注意事项
register_backward_hook只能操作简单模块,而不能操作包含多个子模块的复杂模块。如果对复杂模块用了 backward hook,那么我们只能得到该模块最后一次简单操作的梯度信息。对于上面的代码稍作修改,不再遍历各个子模块,而是把 model 整体绑在一个 hook_fn_backward上:
model = Model()model.register_backward_hook(hook_fn_backward)
输出结果如下:
Model(
(fc1): Linear(in_features=3, out_features=4, bias=True)
(relu1): ReLU()
(fc2): Linear(in_features=4, out_features=1, bias=True)
)
grad_output (tensor([[1.]]),)
grad_input (tensor([1.]), tensor([[1., 2., 3., 4.]]), tensor([[ 7.],
[ 0.],
[27.],
[ 0.]]))
==========Saved inputs and outputs==========
grad output: (tensor([[1.]]),)
grad input: (tensor([1.]), tensor([[1., 2., 3., 4.]]), tensor([[ 7.],
[ 0.],
[27.],
[ 0.]]))
我们发现,程序只输出了 fc2 的梯度信息。
除此之外,有人还总结(吐槽)了 backward hook 在全连接层和卷积层表现不一致的地方(Feedback about PyTorch register_backward_hook · Issue #12331 · pytorch/pytorch)
1.形状
1.1在卷积层中,weight 的梯度和 weight 的形状相同
1.2在全连接层中,weight 的梯度的形状是 weight 形状的转秩(观察上文中代码的输出可以验证)
2.grad_input tuple 中各梯度的顺序
2.1在卷积层中,bias 的梯度位于tuple 的末尾:grad_input = (对feature的导数,对权重 W 的导数,对 bias 的导数)
2.2在全连接层中,bias 的梯度位于 tuple 的开头:grad_input=(对 bias 的导数,对 feature 的导数,对 W 的导数)
3.当 batchsize>1时,对 bias 的梯度处理不同
3.1在卷积层,对 bias 的梯度为整个 batch 的数据在 bias 上的梯度之和:grad_input = (对feature的导数,对权重 W 的导数,对 bias 的导数)
3.2在全连接层,对 bias 的梯度是分开的,bach 中每条数据,对应一个 bias 的梯度:grad_input = ((data1 对 bias 的导数,data2 对 bias 的导数 ...),对 feature 的导数,对 W 的导数)
Guided Backpropagation
通过上文的介绍,我们已经掌握了PyTorch 中各种 hook 的使用方法。接下来,我们将用这个技术写一小段代码(从 kaggle 上扒的,稍作了一点修改),来可视化预训练的神经网络。
Guided Backpropagation 算法来自 ICLR 2015 的文章:
Striving for Simplicity: The All Convolutional Net。
其基本原理和大多数可视化算法类似:通过反向传播,计算需要可视化的输出或者feature map 对网络输入的梯度,归一化该梯度,作为图片显示出来。梯度大的部分,反映了输入图片该区域对目标输出的影响力较大,反之影响力小。借此,我们可以了解到神经网络作出的判断,到底是受图片中哪些区域所影响,或者目标 feature map 提取的是输入图片中哪些区域的特征。Guided Backpropagation 对反向传播过程中 ReLU 的部分做了微小的调整。
我们先回忆传统的反向传播算法:假如第 l 层为 ReLU,那么前向传播公式为:
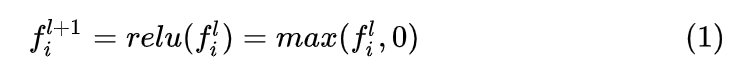
当输入 ReLU 的值大于0时,其输出对输入的导数为 1,当输入 ReLU 的值小于等于 0 时,其输出对输入的导数为 0。根据链式法则,其反向传播公式如下:
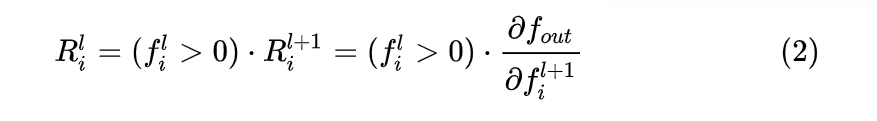
即 ReLU 层反向传播时,只有输入大于 0 的位置,才会有梯度传回来,输入小于等于 0 的位置不再有梯度反传。
Guided Backpropagation 的创新在于,它反向传播时,只传播梯度大于零的部分,抛弃梯度小于零的部分。这很好理解,因为我们希望的是,找到输入图片中对目标输出有正面作用的区域,而不是对目标输出有负面作用的区域。其公式如下:
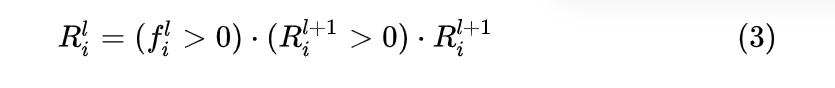
下面是代码部分:
import torch
from torch import nn
class Guided_backprop():
def __init__(self, model):
self.model = model
self.image_reconstruction = None
self.activation_maps = []
self.model.eval()
self.register_hooks()
def register_hooks(self):
def first_layer_hook_fn(module, grad_in, grad_out):
# 在全局变量中保存输入图片的梯度,该梯度由第一层卷积层
# 反向传播得到,因此该函数需绑定第一个 Conv2d Layer
self.image_reconstruction = grad_in[0]
def forward_hook_fn(module, input, output):
# 在全局变量中保存 ReLU 层的前向传播输出
# 用于将来做 guided backpropagation
self.activation_maps.append(output)
def backward_hook_fn(module, grad_in, grad_out):
# ReLU 层反向传播时,用其正向传播的输出作为 guide
# 反向传播和正向传播相反,先从后面传起
grad = self.activation_maps.pop()
# ReLU 正向传播的输出要么大于0,要么等于0,
# 大于 0 的部分,梯度为1,
# 等于0的部分,梯度还是 0
grad[grad > 0] = 1
# grad_in[0] 表示 feature 的梯度,只保留大于 0 的部分
positive_grad_in = torch.clamp(grad_in[0], min=0.0)
# 创建新的输入端梯度
new_grad_in = positive_grad_in * grad
# ReLU 不含 parameter,输入端梯度是一个只有一个元素的 tuple
return (new_grad_in,)
# 获取 module,这里只针对 alexnet,如果是别的,则需修改
modules = list(self.model.features.named_children())
# 遍历所有 module,对 ReLU 注册 forward hook 和 backward hook
for name, module in modules:
if isinstance(module, nn.ReLU):
module.register_forward_hook(forward_hook_fn)
module.register_backward_hook(backward_hook_fn)
# 对第1层卷积层注册 hook
first_layer = modules[0][1]
first_layer.register_backward_hook(first_layer_hook_fn)
def visualize(self, input_image, target_class):
# 获取输出,之前注册的 forward hook 开始起作用
model_output = self.model(input_image)
self.model.zero_grad()
pred_class = model_output.argmax().item()
# 生成目标类 one-hot 向量,作为反向传播的起点
grad_target_map = torch.zeros(model_output.shape,
dtype=torch.float)
if target_class is not None:
grad_target_map[0][target_class] = 1
else:
grad_target_map[0][pred_class] = 1
# 反向传播,之前注册的 backward hook 开始起作用
model_output.backward(grad_target_map)
# 得到 target class 对输入图片的梯度,转换成图片格式
result = self.image_reconstruction.data[0].permute(1,2,0)
return result.numpy()
def normalize(I):
# 归一化梯度map,先归一化到 mean=0 std=1
norm = (I-I.mean())/I.std()
# 把 std 重置为 0.1,让梯度map中的数值尽可能接近 0
norm = norm * 0.1
# 均值加 0.5,保证大部分的梯度值为正
norm = norm + 0.5
# 把 0,1 以外的梯度值分别设置为 0 和 1
norm = norm.clip(0, 1)
return norm
if __name__=='__main__':
from torchvision import models, transforms
from PIL import Image
import matplotlib.pyplot as plt
image_path = './cat.png'
I = Image.open(image_path).convert('RGB')
means = [0.485, 0.456, 0.406]
stds = [0.229, 0.224, 0.225]
size = 224
transform = transforms.Compose([
transforms.Resize(size),
transforms.CenterCrop(size),
transforms.ToTensor(),
transforms.Normalize(means, stds)
])
tensor = transform(I).unsqueeze(0).requires_grad_()
model = models.alexnet(pretrained=True)
guided_bp = Guided_backprop(model)
result = guided_bp.visualize(tensor, None)
result = normalize(result)
plt.imshow(result)
plt.show()
print('END')
程序中用到的图为:

运行结果为:

从图中可以看出,小猫的脑袋部分,尤其是眼睛、鼻子、嘴巴和耳朵的梯度很大,而背景等部分,梯度很小,正是这些部分让神经网络认出该图片为小猫的。
Guided Backpropagation 的缺点是对 target class 不敏感,设置不同的 target class,最终可能得到的 gradient map 差别不大。基于此,有 Grad-CAM (Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization) 等更高级的优化方法,限于篇幅不做介绍。
总结
本文介绍了 PyTorch 中的 hook 技术, 从针对 Tensor 的 hook,到针对 Module 的 hook,最终详细解读了利用 hook 技术可视化神经网络的代码。感谢大家的阅读,还望各位不吝批评指教。
本文为SIGAI原创

















 3692
3692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









