







 本文介绍词嵌入的基本概念,通过CBOW模型实现Word2Vec,并使用t-SNE进行词向量的可视化展示,揭示词义相似性的空间关系。
本文介绍词嵌入的基本概念,通过CBOW模型实现Word2Vec,并使用t-SNE进行词向量的可视化展示,揭示词义相似性的空间关系。
一、前言
本篇博客将介绍一种语言模型词嵌入的一种常用方法,并通过案例简要实现自己的word2vec,并可视化的显示出来。具体一点说就是将一篇文章转化为若干单词,并将这些单词通过CBOW这种词嵌入的方式来训练出来每一个单词的词向量,然后再将这个高维的词向量经过t-SNE降维映射到二维平面中,最后通过matplotlib的有关方法显式的显示出来每一个单词在空间中的相对位置。
二、有关概念
在神经网络中通过一个描述词分布关系的方法来实现语义的理解,我们之前所熟知的描述词的方法是one_hot方法,这种方法可以用一个简单的栗子来假设:我们有两千个不同的单词,我们现在需要用数据来描述每一个单词所包含的信息,我们先把这些单词按照词频的大小先后排序,然后把每一个单词改写为两千维的向量,并把向量的初值设置为0,最后再根据所排的序号给每一个单词在不同的维度下把对应位置的0值改写为1值,这样就得到了one_hot方法下的词向量信息,但是2000个单词需要四百万(2000×2000)个数据量的一个极大的稀疏矩阵来表示,这显然是不合时宜的。
这个时候就需要另外一种能衡量词与词的上下文信息和描述词向量的方法,这种方法就是word embedding,它将one_hot词向量中的每一个元素由整型修改为浮点型,使之变为整个实数范围的表示,然后将原来稀疏的巨大维度压缩嵌入到一个更小的维度空间内。这种更小,其度量范围一般是在原来的十分之一到一百分之一之间,通过这种方法所描述的词向量只需要4万到40万个的参数信息就可以近似的表示出来,而不是通过one_hot方法的四百万。
word embedding方法是建立在分布假说基础上的,即假设词的语义由其上下文决定,上下文相似的词,其语义也相似。它通过具体的一种模型来刻画目标词与其上下文之间的关系。这种模型既可以是CBOW模型,也可以是Skip-Gram模型,这两种模型都作为word2vec中的算法集合中的一员,相对而言CBOW和负采样的方式实现起来相对简单一些,本篇则使用这种方法来训练自己的word2vec。
CBOW的核心思想就是根据某个词的前面的n个词或者前后n个词来计算某个词出现的概率。
三、具体实现
1.首先装分词库,可以直接对整篇文章做分词处理
在终端中使用pip install jieba 命令安装本次使用的分词库
2.准备样本数据集
这里使用的是《龙族1》的部分片段做样本放入代码的同级目录下
# _*_ coding:utf-8 _*_
import numpy as np
import tensorflow as tf
import random
import collections
from collections import Counter
import jieba
from sklearn.manifold import TSNE
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['font.family']='STSong'
mpl.rcParams['font.size']=20
training_file='龙族1火之晨曦.txt'
#获取中文content
def get_ch_labels(txt_file):
labels=""
with open(txt_file,'rb') as f:
for label in f:
#print(label)
labels=labels+label.decode('utf-8')
return labels
#分词
def fenci(training_data):
#分词对象
seg_list=jieba.cut(training_data)
#词与词之间加空格
training_ci=" ".join(seg_list)
#用空格切分字符串
training_ci=training_ci.split()
#构建numpy数组
training_ci=np.array(training_ci)
#reshape array
training_ci=np.reshape(training_ci,[-1,])
return training_ci
#构建词典
def build_dataset(words,n_words):
"""Process raw inputs into a dataset."""
count=[['UNK',-1]]
#统计前n_words个单词的出现的次数并依次排列
count.extend(collections.Counter(words).most_common(n_words-1))
dictionary={}
for word,_ in count:
#正向索引,如 '路明'=23
dictionary[word]=len(dictionary)
data=[]
unk_count=0
#遍历单词表,统计出未定义单词数量,并把已定义单词所对应的数值入列表
for word in words:
if word in dictionary:
index=dictionary[word]
else:
index=0
unk_count+=1
data.append(index)
#count[['UNK',unk_count]]
count[0][1]=unk_count
print(count[0][1])
#定义反向词典 如 '23'='路明'
reversed_dictionary=dict(zip(dictionary.values(),dictionary.keys()))
#print([reversed_dictionary[i] for i in range(20)])
#data为词典数字列表,count为未在词典中的单词数量,dictionary为正向词典,reversed_dictionary为反向词典
return data,count,dictionary,reversed_dictionary
ch_labels=get_ch_labels(training_file)
print("总字数:{}".format(len(ch_labels)))
training_ci=fenci(ch_labels)
print("总词数:{}".format(len(training_ci)))
training_label,count,dictionary,reversed_dictionary=build_dataset(training_ci,3000)
words_size=len(dictionary)
print("字典词数",words_size)
#显示前十个词对应的索引信息
print('Sample data',training_label[:10],[reversed_dictionary[i] for i in training_label[:10]])
3.获取下一批次数据
data_index=0
#生成下一个批次的数据
def generate_batch(data,batch_size,num_skips,skip_window):
'''
:param data: training_label 词典数字列表
:param batch_size: batch_size
:param num_skips:一次生成标签的数量 值为2时表示,当前字的前后两个字作为标签
:param skip_window:取词窗口
:return:
'''
global data_index
#python assert断言是声明其布尔值必须为真的判定,如果发生异常就说明表达式为假。若表达式为假,则会触发异常
assert batch_size % num_skips== 0
assert num_skips <=2*skip_window
batch=np.ndarray(shape=(batch_size),dtype=np.int32)
labels=np.ndarray(shape=(batch_size,1),dtype=np.int32)
#skip window =1 所以每一个样本由前skip_window + 当前target + 后skip_window 构成
span=2*skip_window+1
#创建双边队列
buffer=collections.deque(maxlen=span)
#判断最后一位是否越界
if data_index+span>len(data):
data_index=0
#在队列最右边添加元素 数量为span
buffer.extend(data[data_index:data_index+span])
data_index+=span
#//表示整数除法,/表示浮点数除法
for i in range(batch_size//num_skips):
target=skip_window #target在buffer中的索引值为skip_window
targets_to_avoid=[skip_window]
for j in range(num_skips):
#两次循环遍历一遍batch_size
while target in targets_to_avoid:
target=random.randint(0,span-1)
targets_to_avoid.append(target)
#此是讲中间的一个字作为输入,将其前面和后面的字作为标签,组成一组batch_size
batch[i*num_skips+j]=buffer[skip_window]
labels[i*num_skips+j,0]=buffer[target]
if data_index==len(data):
#指向最后一个,则从头开始计
buffer=data[:span]
data_index=span
else:
#在buffer的最右边添加一个元素
buffer.append(data[data_index])
data_index+=1
#防止越界
data_index=(data_index+len(data)-span)%len(data)
return batch,labels
batch,labels=generate_batch(training_label,batch_size=8,num_skips=2,skip_window=1)
#测试函数
for i in range(8):
print(batch[i],reversed_dictionary[batch[i]],'->',labels[i,0],reversed_dictionary[labels[i,0]])
4.定义模型结构
batch_size=128
embedding_size=128
skip_window=1 #左右的词数量
num_skips=2 #一个input生成两个标签
valid_size=16
valid_window=words_size//2 #取样数据的分布范围
valid_examples=np.random.choice(valid_window,valid_size,replace=False) #0-words_size/2 中的数取1500个。不能重复
num_sampled=64 #负采样个数
'''
定义模型变量
初始化图,为输入、标签、验证数据定义占位符,定义词嵌入变量embeddings为每个字定义128维的向量,并初始化维-1~1之间的均匀分布随机数。
tf.nn.embedding_lookup是将输入的train_inputs转成对应的128维向量embed,定义nce_loss要使用的nce_weight和nce_biases
'''
tf.reset_default_graph()
train_inputs=tf.placeholder(tf.int32,shape=[batch_size])
train_labels=tf.placeholder(tf.int32,shape=[batch_size,1])
valid_dataset=tf.constant(valid_examples,dtype=tf.int32)
with tf.device('/cpu:0'):
#查找embeddings 3000个字,每个128向量 须将所有的词全部随机初始化
embeddings=tf.Variable(tf.random_uniform([words_size,embedding_size],-1.0,1.0))
#embed为train_inputs映射好的词向量,并且反向传播更新embeddings的过程也会在该方法中完成
embed=tf.nn.embedding_lookup(embeddings,train_inputs)
#计算nce的loss值
#使用nce_loss计算的loss可以保证softmax时的运算速度不被words_size过大问题所影响,
#在nce中每次会产生num_sampled(64)个负样本参与概率运算。
nce_weights=tf.Variable(tf.truncated_normal([words_size,embedding_size],
stddev=1.0/tf.sqrt(np.float32(embedding_size))))
nce_biases=tf.Variable(tf.zeros([words_size]))
#定义损失函数和优化器
loss=tf.reduce_mean(
tf.nn.nce_loss(weights=nce_weights,biases=nce_biases,
labels=train_labels,inputs=embed,
num_sampled=num_sampled,num_classes=words_size)
)
optimizer=tf.train.GradientDescentOptimizer(learning_rate=1.0).minimize(loss)
#计算minibatch examples 和所有 embddings 的 cosine相似度
#该相似度similarity 通过向量间夹角余弦计算
#当cosθ为1时,表明夹角为0,即两个向量的方向完全一样。所以当cosθ的值越小,表明两个向量的方向越不一样,相似度越低
norm=tf.sqrt(tf.reduce_sum(tf.square(embeddings),1,keep_dims=True))
normalized_embeddings=embeddings/norm
valid_embeddings=tf.nn.embedding_lookup(normalized_embeddings,valid_dataset)
similarity=tf.matmul(valid_embeddings,normalized_embeddings,transpose_b=True)
5.启动session 创建模型
#启动session,训练模型
num_steps=30001
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
average_loss=0
for step in range(num_steps):
batch_inputs,batch_labels=generate_batch(training_label,batch_size,num_skips,skip_window)
# print(batch_inputs.shape)
# print(batch_labels.shape)
feed_dict={train_inputs:batch_inputs,train_labels:batch_labels}
_,loss_val=sess.run([optimizer,loss],feed_dict=feed_dict)
average_loss+=loss_val
# emv=sess.run(embed,feed_dict={train_inputs:[69,1494]})
# print("emv--------------------",emv[0])
if step%2000==0:
if step >0:
average_loss/=2000
print('Average loss at step ',step,':',average_loss)
average_loss=0
#将验证数据输入模型中,找出与其相近的词。这里使用了argsort函数,是将数组中的值从小到大排列后,
#返回每个值对应的索引 sim是求当前词与词典中没个词的夹角余弦,值越大则代表相似度越高
if step%10000==0:
sim=similarity.eval(session=sess)
for i in range(valid_size):
valid_word=reversed_dictionary[valid_examples[i]]
top_k=8 #取排名最靠前的8个词
nearest=(-sim[i,:].argsort()[1:top_k+1])
log_str='Nearest to %s:'%valid_word
for k in range(top_k):
close_word=reversed_dictionary[-nearest[k]]
log_str='%s,%s'%(log_str,close_word)
print(log_str)
final_embeddings=normalized_embeddings.eval()
6.绘制降维图像
def plot_with_labels(low_dim_embs,labels,filename='tsne.png'):
assert low_dim_embs.shape[0] >= len(labels),'More labels than embeddings'
plt.figure(figsize=(18,18)) # in inches
for i ,label in enumerate(labels):
x,y=low_dim_embs[i,:]
plt.scatter(x,y)
plt.annotate(label,xy=(x,y),xytext=(5,2),textcoords='offset points',ha='right',va='bottom')
plt.savefig(filename)
try:
tsne=TSNE(perplexity=30,n_components=2,init='pca',n_iter=5000)
plot_only=80 #输出100个词
low_dim_embs=tsne.fit_transform(final_embeddings[:plot_only, :])
labels=[reversed_dictionary[i] for i in range(plot_only)]
plot_with_labels(low_dim_embs,labels)
except BaseException:
print('error happened')
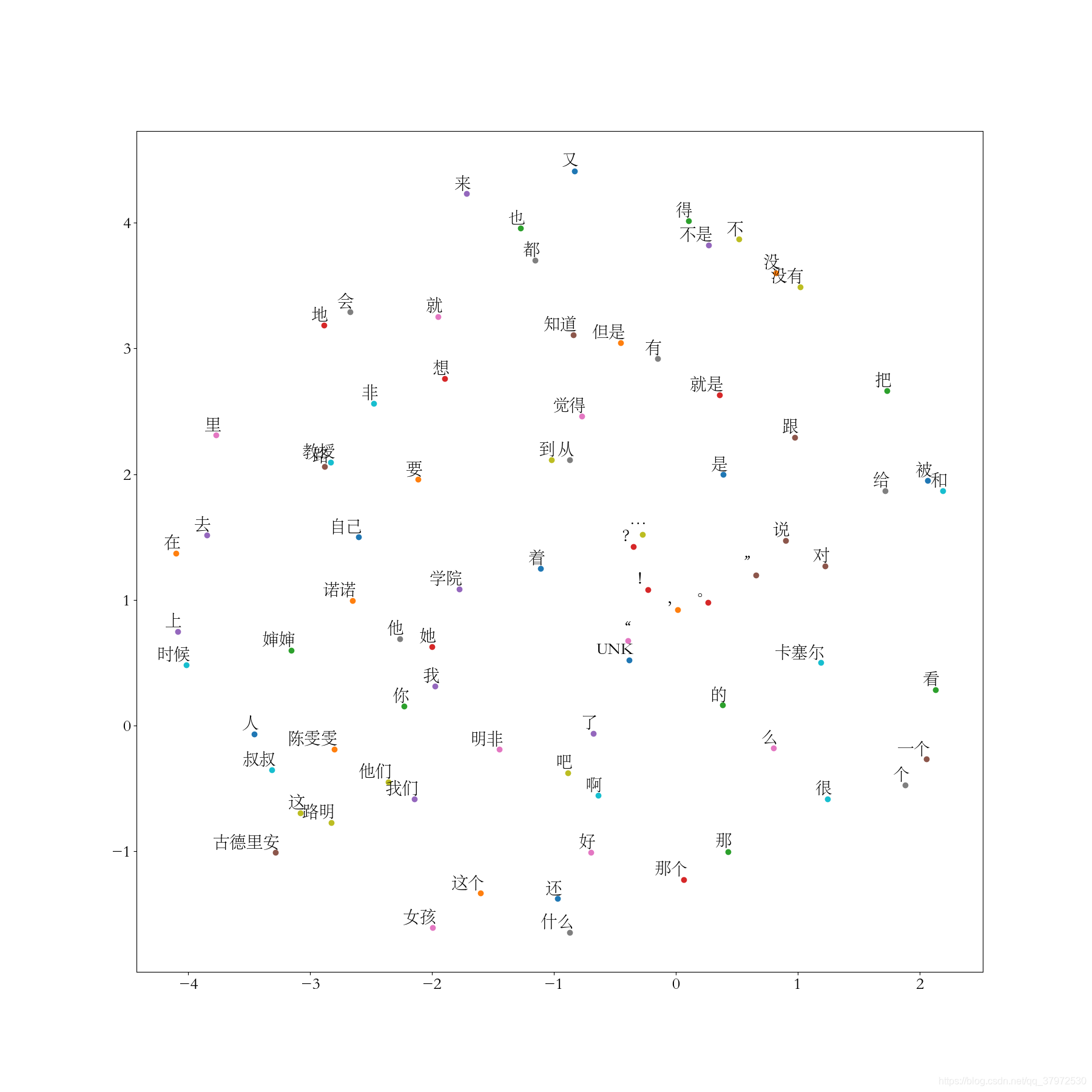 如图所示,意义相近的单词他们的相对位置也越近。
如图所示,意义相近的单词他们的相对位置也越近。
四、总结与分析
1.本篇所贴代码并不是博主所写,仅仅在理解的水平上注明了少量注释和改动,原文在李金洪所编著的《深度学习之TensorFlow入门、原理与进阶实战》代码9-26,有需要的可以借鉴原文内容。
2.经过这几个月的学习,发现博主所观,尽是皮毛,有部分写过的代码很容易就可以找出错误所在,若对观者产生了错误的理解,还望海涵。

















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









