







 本文介绍了一个包含20种花卉分类的数据集及其使用VGG16网络进行训练的过程。数据集由20000张图片组成,每种花卉1000张。文章分享了训练代码及遇到的问题解决方案。
本文介绍了一个包含20种花卉分类的数据集及其使用VGG16网络进行训练的过程。数据集由20000张图片组成,每种花卉1000张。文章分享了训练代码及遇到的问题解决方案。
一、前言
首先附上整理之后的20种花卉分类数据集链接,第一部分,第二部分,第三部分,由于csdn对上传资源的限制,故共分为3个下载链接来使用,再次简要的介绍一下博主所整理的数据集,该数据集为20分类的花卉数据集合,分别为:杜鹃花、风信子、桂花、荷花、菊花、康乃馨、洛神花、玫瑰、梅花、茉莉花、牡丹、蒲公英、牵牛花、桃花、勿忘我、罂粟花、樱花、郁金香、月季和紫罗兰,每一种类别有1000张图片,20分类则有20000张图片。
其次要说明的是上一篇的数据处理的代码有一部分有瑕疵,后经过博主的微调现在可以正常使用了,在写完这一系列的内容之后博主会将相关代码和文件放到码云上面去,以供学习和交流。
然后要说明的是上一篇的数据保存方式的解决办法,为了能看到中间结果,博主将数据集的输入从20000*300*300*3改为了20000*224*224*3,保存的中间结果的文本数据减小到了原来的1/2。然后生成的文本数据信息是酱紫的:
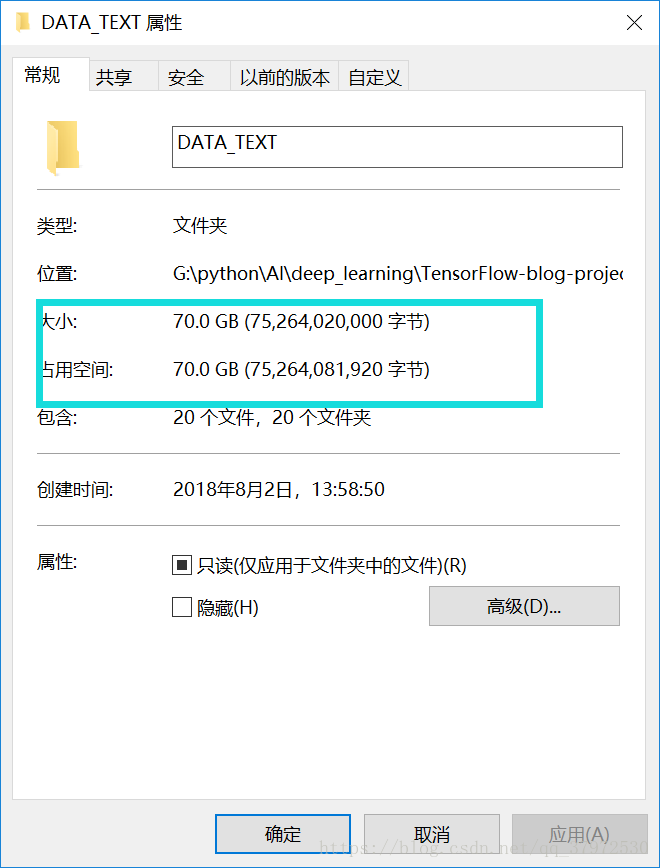
这个大小占了当前固态盘符的4/5,所以大家在运行的时候需慎重考虑之。
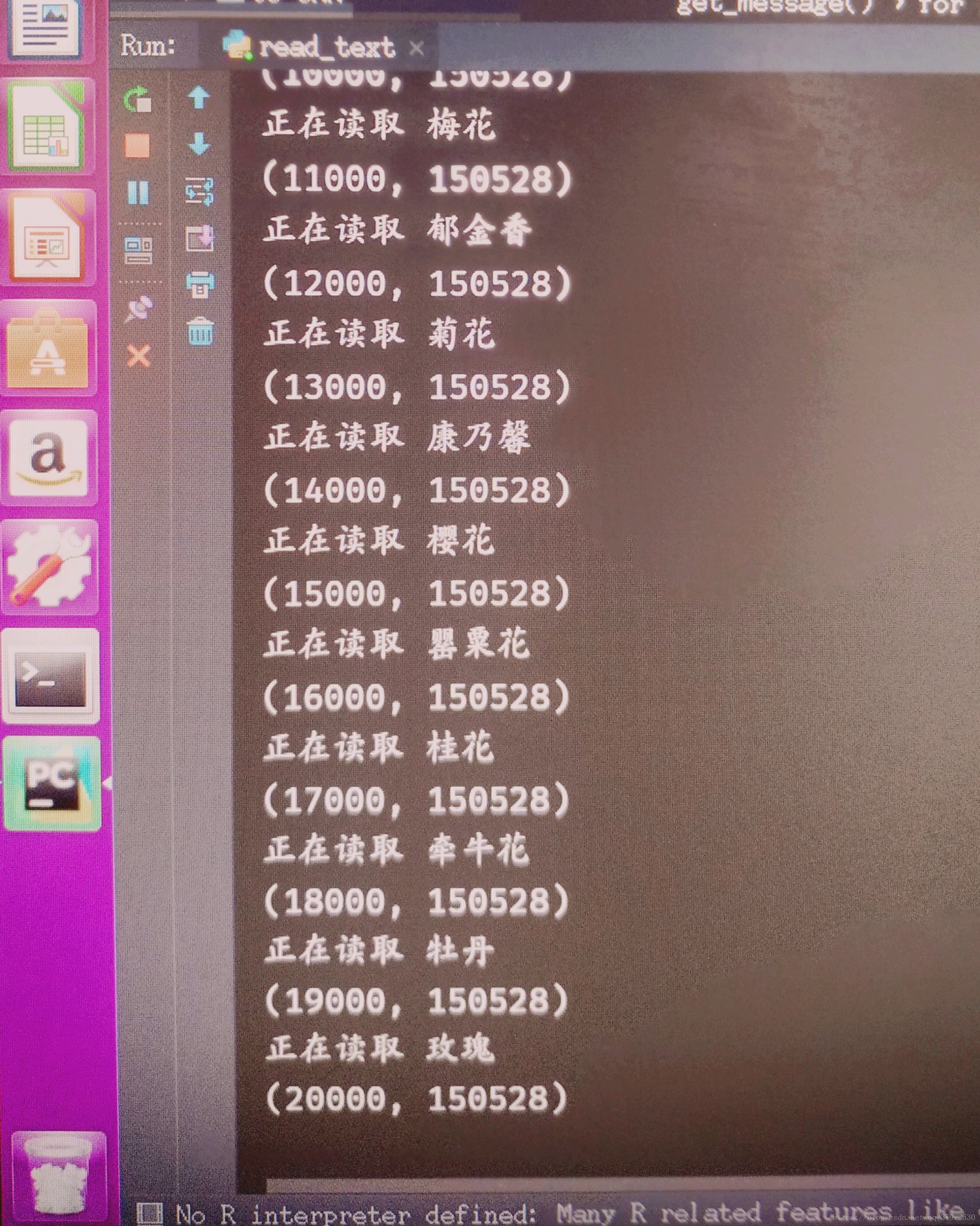
最后在数据读取的过程中,依然有问题出现,由于数据量比较大,在读取到一定大小的时候会报Memory Error的报错信息,这个博主后来更换成工作站运行解决的,请读者自行把握文内的参数。最后贴图给大家展示一下数据集的信息,简要计算一下输入:X的数据个数为20000*224*224*3=3010560000,超过30亿个数据信息,大致需要11G以上的显存或者内存,想想还是挺好玩的。
二、任务目标
1.构建vgg16的网络
2.总共的训练迭代次数为5000次
3.可以保存和重载中间模型,并最终保存两种文件格式的模型文件
4.得到测试集的准确率信息,作为模型的评估指标
三、任务主要内容
任务简化说明:由于本次计算的计算量比较大,等工作站计算出来之后会在后面的文章中贴出来运行结果并说明运行时间,本次所展示的是仅保留两个txt文本,在博主PC机上的训练。也就是做一个二分类的训练,来过一遍流程。20分类的训练仅仅需要修改相关的参数即可。
#vgg_net.py文件中
1.导包
import read_text
import tensorflow as tf
import numpy as np
import re
from tensorflow.python.framework import graph_util2.从文本中读取数据
def get_data(text_dir='DATA_TEXT'):
X_train,X_test,Y_train,Y_test=read_text.get_message(text_dir=text_dir)
return X_train,X_test,Y_train,Y_test3.重定义变量初始化函数,可以在后期更加便捷的初始化参数
def get_variable(name,shape=None,dtype=tf.float32,initializer=tf.random_normal_initializer(mean=0,stddev=0.01,seed=32)):
return tf.get_variable(name,shape,dtype=dtype,initializer=initializer)4.定义网络模型
def train():
#定义占位符
X=tf.placeholder(tf.float32,shape=[None,150528],name='X_input')
Y=tf.placeholder(tf.float32,shape=[None,2],name='Y_input')
pre = vgg16_net(X, Y)
# 计算损失函数
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pre, labels=Y))
# 定义优化器
train = tf.train.AdamOptimizer(learning_rate=0.01).minimize(loss)
equal = tf.equal(tf.argmax(pre, axis=1), tf.argmax(Y, axis=1))
# 正确率
accuracy = tf.reduce_mean(tf.cast(equal, tf.float32))
init = tf.global_variables_initializer()
training_epochs=5000
batch_size=5
display_step=1
save_epoch_num=20
with tf.Session() as sess:
#train,loss,accuracy=train_update(x,y)
# 变量初始化
sess.run(init)
X_train,X_test,Y_train,Y_test=get_data(text_dir='DATA_TEXT')
#X_train,X_test,Y_train,Y_test=X_train.tolist(),X_test.tolist(),Y_train.tolist(),Y_test.tolist()
X_train_shape=X_train.shape
X_test_shape=X_test.shape
#计算每个epoch的batch_size次数
train_epoch_size=int(X_train_shape[0]/batch_size)
test_epoch_size=int(X_test_shape[0]/batch_size)
#定义模型保存对象
saver=tf.train.Saver()
#重载保存的中间模型
result=[0]
#查看模型状态
ckpt=tf.train.get_checkpoint_state('./model')
#加载模型
if ckpt and ckpt.model_checkpoint_path:
print("model restoring")
saver.restore(sess,ckpt.model_checkpoint_path)
print(ckpt.model_checkpoint_path)
pattern=re.compile('\d+')
result=pattern.findall(ckpt.model_checkpoint_path)
print(result[0])
for epoch in range(training_epochs-int(result[0])):
for i in range(train_epoch_size):
#获取下一批次的训练集数据
train_batch_x=X_train[i*batch_size:(i+1)*batch_size]
train_batch_y=Y_train[i*batch_size:(i+1)*batch_size]
#模型训练
sess.run(train,feed_dict={X:train_batch_x,Y:train_batch_y})
loss_=sess.run(loss,feed_dict={X:train_batch_x,Y:train_batch_y})
accuracy_=sess.run(accuracy,feed_dict={X:train_batch_x,Y:train_batch_y})
if i%display_step==0:
print("epoch:%d,step:%d,损失函数值为:%.6f,训练集当前准确率为%.3f" % (epoch + int(result[0]), i, loss_, accuracy_))
test_accuracy_=0
for j in range(test_epoch_size):
#获取下一批次的测试集数据
test_batch_x,test_batch_y=X_test[i*batch_size:i*batch_size+batch_size],Y_test[i*batch_size:i*batch_size+batch_size]
#计算准确率
test_accuracy_+=sess.run(accuracy,feed_dict={X:test_batch_x,Y:test_batch_y})
test_accuracy_=test_accuracy_/test_epoch_size
print("测试集准确率为%.3f"%test_accuracy_)
if (epoch+1)%save_epoch_num==0:
#.ckpt模型保存
saver.save(sess,'./model/model',global_step=epoch+1+int(result[0]))
print("{} model had saved in ./model/model".format(epoch+1+int(result[0])))
#.pb模型文件保存方式
constant_graph=graph_util.convert_variables_to_constants(sess,sess.graph_def,["output"])
with tf.gfile.FastGFile('pb_path/graph.pb',mode='wb') as file:
file.write(constant_graph.SerializerToString())#train.py文件中
1.导包
import numpy as np
import tensorflow as tf
import image_to_text
import vgg_net
2.定义主函数和运行代码
def main():
#图片转文本信息
#此处因为要用二分类进行测试,所以就不进行检验数据文件的存在性了
#sess = tf.InteractiveSession()
#traverse_in_data('DATA', 'DATA_TEXT')
vgg_net.train()
if __name__ =='__main__':
main()四、分析与总结
1.因为博主希望保留较高的数据集信息,所以就把数据设置的比较大,因而这个模型训练出来需要机器的配置相对较高,并且所耗费的时间也是比较长的。
2.因为训练集的结果会在之后的博客中说明,这里就贴一下刚开始训练的一张截图,证明代码的可行性。
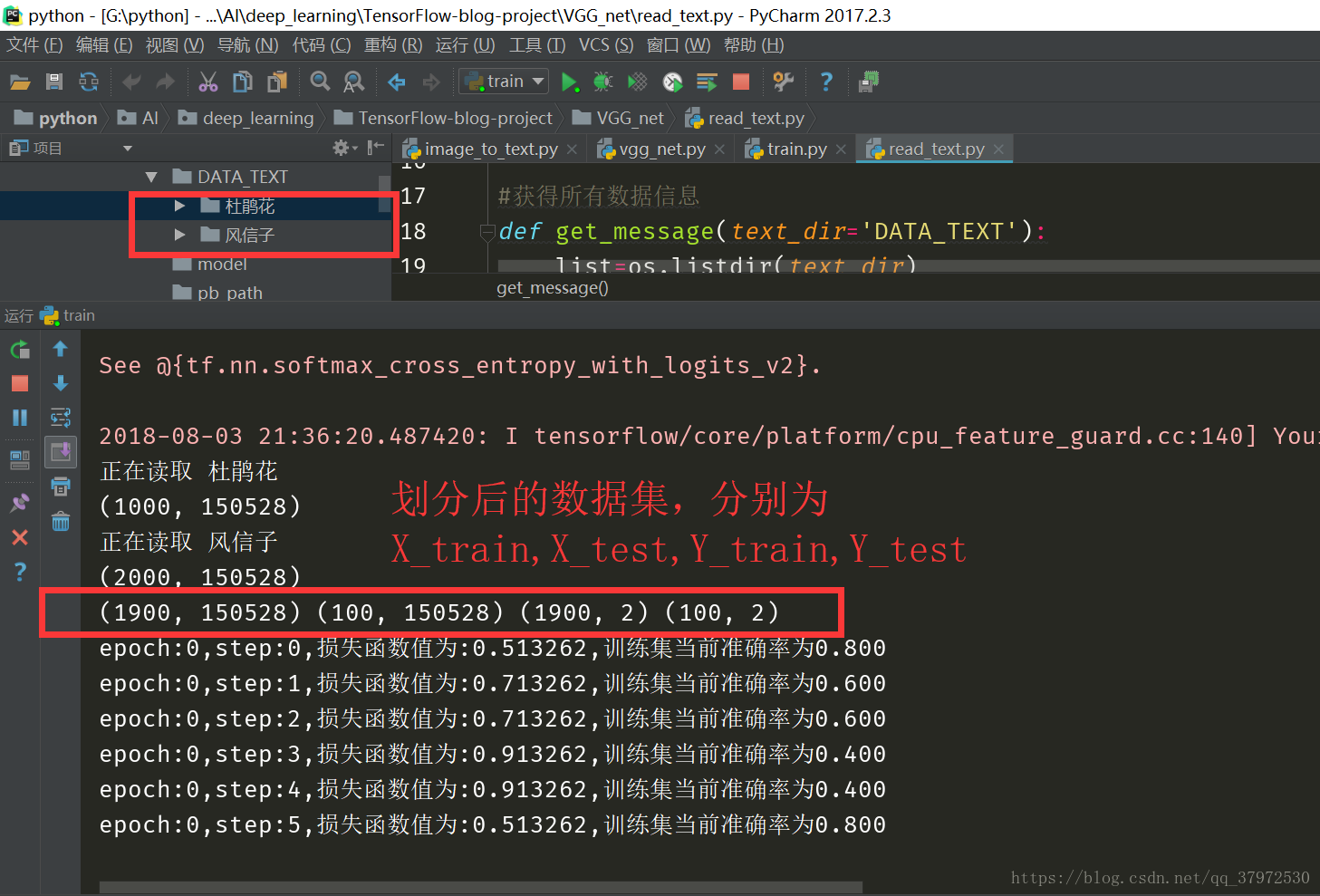
3.如果有什么具体的问题可以在下面留言,希望可以与大家共同交流与学习。

















 4380
4380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









