




一、前言
本项目和接下来的几篇博文将会围绕着此次拿到的花卉图片数据使用各种不同的深度神经网络做分类处理,本篇内容可能会显得比较神经质。整个编写和整理的过程博主预测还是很有意思的,我们规定整个的training_epochs=5000,batch_size=10,learning_rate=0.01,梯度下降方式选择AdamOptimizer的方式,参数初始化都选择为mean=0,stddev=0.01的参数初始化方式。然后本篇和接下来的几篇共同见证在这些参数一致的时候,不同网络模型的准确率的异同。
二、获取数据
首先不得不感叹python和爬虫的强大,在爬取图片的数据中发生了一点小插曲,事情是这样的,我是在今年二月份学的爬虫并做了几个小项目,其中有一个就是爬取图片,本次使用的就是当月所遗留下来的”黄金屋“(时间是一把杀猪刀啊)我现在写估计是要花很大一翻功夫的,然后在运行所爬取的图片数据的时候,读取到某一张图片时发生的错误就导致了程序的中止,我猜想是该图片一定是个不正常的广告,既然发生了异常,那么该数据也一定不是对的,那么就该果断舍弃之,于是就不得不感谢自己对python基础的掌握了。这里使用了异常处理的相关代码,直接匹配错误的基类,也就是说对于该报错段所有的错误都接受然后打印出错误信息,或者直接pass也是OK的。
其次通过爬虫也能检验出计算机组成原理中的所学,CPU的处理速度大于内存的存取速度大于硬盘(博主用的是比较便宜的固态)的存取速度的,当博主爬完某一分类的一千余张图片之后,硬盘中的图片也只是有三百余张的图片,当然这里博主暂停了程序的运行,等待所有的图片都保存进硬盘内(大概十几分钟)才中止的。
当然这里的程序不是特别的智能,这里需要每次输入单个检索关键词,多个检索关键词仅需加入一个外层循环和文件处理的相关内容。为了实时的获取不出什么问题博主还是全程跟随代码的进度监督爬取收集的。
然后通过爬虫获取到的数据并不是特别的好,需要数据清洗,博主清洗的方式就是手工人眼模糊处理,标准化什么的需要在代码中添加,后面会有说明。
最后,简单介绍一下此次小项目的数据集,为了达到20分类的目的,此次将爬取20类每类1000张图片,总共20000张图片,不得不吐槽一下整理数据集的繁琐,获取每一分类的数据集都大概耗时半小时,20分类就耗费了约10个小时的时间。
三、数据预处理
首先博主写了一个关于图片信息转换为数组文本信息的代码,具体是按照如下方法实现的。
1.获取分类数量
def get_classify_num(data_path):
"""
Read the number of classifications
:param data_path:
:return:
"""
return len(os.listdir(data_path))为了精简代码的运行时间,博主这里只是在同级DATA的同级目录放置了两个分类的文件夹和文件夹内的数据。
2.定义用于每一分类的图片转换函数
def images_transform(image_dir_path,size=(300,300),channels=3):
'''
Picture conversion
:param image_path:
:param size:
:param channels:
:return:
'''
list_images=os.listdir(image_dir_path)
list_image_tensors=[]
print(os.getcwd())
for i in range(len(list_images)):
#file_contents=tf.read_file(list_images[i])
#读取图片信息
file_contents=tf.gfile.FastGFile(list_images[i],'rb').read()
#将二进制图片信息解码
image_tensor=tf.image.decode_jpeg(file_contents,channels=channels)
#将图片进行标准化
image_tensor=tf.image.resize_images(image_tensor,size=size,method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
list_image_tensors.append(image_tensor)
#返回转化后的tensor列表
return list_image_tensors3.用于判断存放文本信息的目录是否存在
#判断DATA_TEXT是否存在,不存在则创建该目录
def text_folder_is_exit(text_folder):
if os.path.exists(text_folder):
print(os.listdir('./'))
else:
os.mkdir(text_folder)
print(os.listdir('./'))4.用于保存图片为文本信息的方法
def save_image_message(save_tensor,text_folder,classify_name,data_path='DATA'):
#进入DATA的同级目录
os.chdir('../')
text_folder_is_exit(text_folder)
os.chdir(text_folder)
text_folder_is_exit(classify_name)
os.chdir(classify_name)
#将tensor reshape为二维数组(1000,270000)
save_tensor=tf.reshape(save_tensor,shape=(-1,270000))
#将tensor转换为numpy数组
save_array=save_tensor.eval()
#保存array为text文件
np.savetxt(classify_name+'.txt',save_array)
os.chdir('../../'+data_path)5.判断文件是否保存
def judge_message_is_exist(text_folder,classify_name,data_path='DATA'):
os.chdir('../../'+text_folder)
#判断classify_name是否已经创建过文件夹
judge_=os.path.exists(classify_name)
os.chdir('../'+data_path)
return judge_通过这个函数可以精简第二次运行时的等待时间
6.遍历保存图片信息
#遍历图片
def traverse_in_data(data_path,text_folder):
'''
Traversing and changing the data
:param data_path:
:return:
'''
#获取数据集中的分类列表
list_data=os.listdir(data_path)
#获取数据集的分类数量
classify_num=get_classify_num(data_path)
#判断文本目录是否存在
text_folder_is_exit(text_folder)
#改变os的作用域
os.chdir(data_path)
for i in range(classify_num):
os.chdir(list_data[i])
#保存数据为文件
if judge_message_is_exist(text_folder,list_data[i]) :
print("{}数组已保存".format(list_data[i]))
else:
os.chdir(list_data[i])
# 遍历当前目录下的所有图片,返回一个转化后的tensor(1000,300,300,3)
resize_image_tensors = images_transform('./', size=(300, 300), channels=3)
print("正在保存{}".format(list_data[i]))
save_image_message(resize_image_tensors,text_folder,list_data[i])
os.chdir('../../')7.到这里这部分的预处理的代码就可以运行了,运行其实很简单,无非是开启一个交互式的会话然后调用一下函数就可以了。
sess = tf.InteractiveSession()
traverse_in_data('DATA','DATA_TEXT')通过以上代码时可以在相应目录下面保存相应的文本文件的。如下图所示:
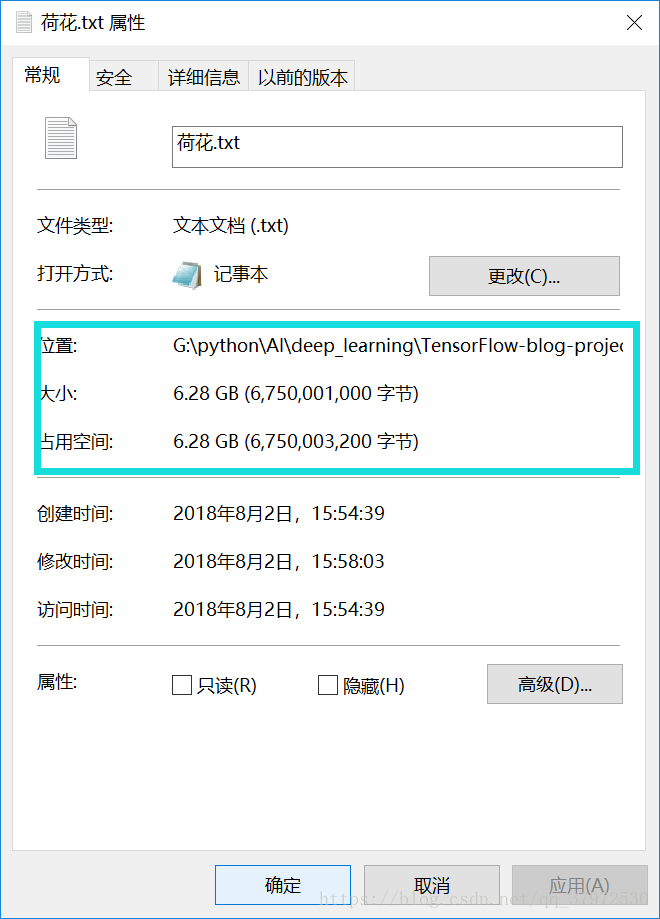
但是出乎意料的是,这样的一个文本文件非常大,所以可以预料的到在之后的读取中会花费非常多的IO开销,然后会导致电脑卡死等问题,这个方式在之后会进行修改,目前博主可以想得到的两种方式分别为减少图片的像素信息和更换存储方式为直接读取,这个会在接下来的介绍中提到具体的实现。下图是一个文本数据的信息,20分类的文本信息数据将是其的20倍,不得不令人咋舌。
既然有保存就得有相应的读取,接下来的代码就用于读取保存的文件,并通过相应的转换转换为我们所需要的格式。
1.导包(这里会需要两个机器学习库中方法)
import numpy as np
import tensorflow as tf
import os
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder2.定义读取单个类别的所有数据信息的方法
def get_a_category_message(classify_name,text_dir='DATA_TEXT'):
os.chdir(text_dir+'/'+classify_name)
array=np.loadtxt(classify_name+'.txt',dtype=np.float32)
os.chdir('../../')
return array3.获取所有的数据信息
def get_message(text_dir='DATA_TEXT'):
list=os.listdir(text_dir)
len_list=len(list)
X=[]
Y=[]
for i in range(len_list):
array=get_a_category_message(list[i])
X.append(array)
#获取x的数量
array_shape_0=array.shape[0]
for j in range(array_shape_0):
Y.append(i)
X=np.reshape(X,(-1,270000))
Y=np.reshape(Y,[-1])
Y=OneHotEncoder(sparse=True).fit_transform(Y).toarray()
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.05,random_state=36)
print(X_train.shape,X_test.shape,Y_train.shape,Y_test.shape)
return X_train,X_test,Y_train,Y_test这部分代码相对而言比较简单,因为就两个函数,也没有特别多的参数的调用,直接调用后一个函数即可运行,值得注意的一点是这里使用了机器学习中用于切分训练集和测试集的api,还有用于产生哑编码的api,对于像这种api的调用可以大大的优化我们的代码编写时间和效率。它的IO开销也不能不称之大,仅读取两个数据文本就耗费了20分钟,所以做相应的优化是毋庸置疑的。
四、分析与总结
本篇主要写的是对数据的预处理,具体网络模型的构建会在下面几篇的叙述中来比对和整理,由于数据集到目前为止还没有完全整理好,所以整理好的数据集将在下一篇中分享出来,并且此项目在这几篇编写完成之后会放到码云作为开源项目来参考与使用。

















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









