






KNN
如何衡量相似(距离)
不同属性之间的比较
- 标称属性
- 属性值匹配
- 属性值不匹配
- 0 − 1 0-1 0−1 函数
- 序数属性
- 可以考虑量化序数属性
- d = ∣ p − q ∣ n − 1 d = \frac{|p-q|}{n-1} d=n−1∣p−q∣
- 区间或者比率属性
- 属性值差的绝对值
- 属性值比率
- d = ∣ p − q ∣ d = |p-q| d=∣p−q∣
- s = − d , s = 1 1 + d , s = 1 − d − min d max d − min d s = -d,s = \frac{1}{1+d},s = 1 - \frac{d - \min d}{\max d - \min d} s=−d,s=1+d1,s=1−maxd−mindd−mind
距离
距离公理,度量
- 非负性 d ( a , b ) ≥ 0 d(a,b) \geq 0 d(a,b)≥0
- 到自身的距离为0 d ( a , a ) = d ( b , b ) = 0 d(a,a) = d(b,b) = 0 d(a,a)=d(b,b)=0
- 对称性 d ( a , b ) = d ( b , a ) d(a,b) = d(b,a) d(a,b)=d(b,a)
- 三角不等式 d ( a , b ) ≤ d ( a , k ) + d ( b , k ) d(a,b) \leq d(a,k) + d(b,k) d(a,b)≤d(a,k)+d(b,k)
欧氏距离 ( E u c l i d e a n D i s t a n c e ) (Euclidean\ Distance) (Euclidean Distance)
x a = ( x a 1 , . . . , x a n ) , x b = ( x b 1 , . . . , x b n ) x_a = (x_{a1},...,x_{an}),x_b = (x_{b1},...,x_{bn}) xa=(xa1,...,xan),xb=(xb1,...,xbn)
⇒ d ( a , b ) = ( x a 1 − x b 1 ) 2 + . . . + ( x a n − x b n ) 2 \Rightarrow d(a,b) = \sqrt{(x_{a1} - x_{b1})^2+...+(x_{an} - x_{bn})^2} ⇒d(a,b)=(xa1−xb1)2+...+(xan−xbn)2
曼哈顿距离 ( M a n h a t t a n D i s t a n c e ) (Manhattan\ Distance) (Manhattan Distance)
d ( a , b ) = ∣ x a 1 − x b 1 ∣ + . . . + ∣ x a n − x b n ∣ d(a,b) = |x_{a1}-x_{b1}|+...+|x_{an}-x_{bn}| d(a,b)=∣xa1−xb1∣+...+∣xan−xbn∣
闵可夫斯基距离 ( M i n k o w s k i D i s t a n c e ) (Minkowski\ Distance) (Minkowski Distance)
- 普通的闵可夫斯基距离
d ( a , b ) = ( ∣ x a 1 − x b 1 ∣ p + . . . + ∣ x a n − x b n ∣ p ) 1 p d(a,b) = (|x_{a1}-x_{b1}|^p+...+|x_{an}-x_{bn}|^p)^{\frac{1}{p}} d(a,b)=(∣xa1−xb1∣p+...+∣xan−xbn∣p)p1
其中 p p p 为一个整数 - 加权闵可夫斯基距离
d ( a , b ) = ( w 1 ∣ x a 1 − x b 1 ∣ p + . . . + w n ∣ x a n − x b n ∣ p ) 1 p d(a,b) = (w_1|x_{a1}-x_{b1}|^p+...+w_n|x_{an}-x_{bn}|^p)^{\frac{1}{p}} d(a,b)=(w1∣xa1−xb1∣p+...+wn∣xan−xbn∣p)p1
其中 p p p 为一个整数
可以发现,欧氏距离以及曼哈顿距离都是闵可夫斯基距离的一个特例
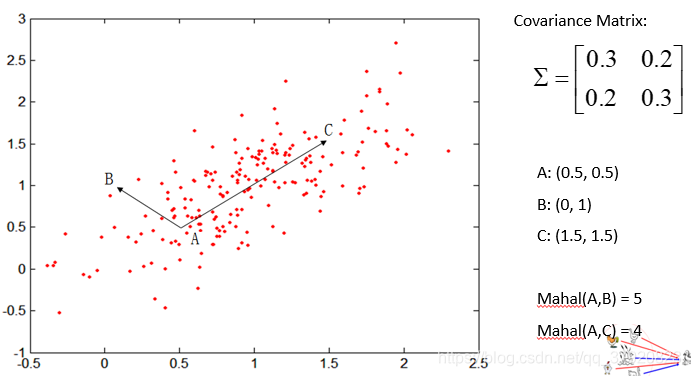
马氏距离 ( M a h a l a n o b i s D i s t a n c e ) (Mahalanobis\ Distance) (Mahalanobis Distance)
d
(
a
,
b
)
=
(
a
−
b
)
Σ
−
1
(
a
−
b
)
T
d(a,b) = (a-b)\Sigma^{-1}(a-b)^T
d(a,b)=(a−b)Σ−1(a−b)T
其中
Σ
\Sigma
Σ 是数据的协方差矩阵
Σ
j
,
k
=
1
n
−
1
∑
i
=
1
n
(
X
i
j
−
X
ˉ
j
)
(
X
i
k
−
X
ˉ
k
)
\Sigma_{j,k} = \frac{1}{n-1}\sum_{i=1}^n(X_{ij} - \bar X_j)(X_{ik} - \bar X_k)
Σj,k=n−11i=1∑n(Xij−Xˉj)(Xik−Xˉk)
相当于引入了对方向上的方差进行惩罚的机制。
一些不满足距离或度量的评估标准
- 集合
- d ( A , B ) = s i z e ( A − B ) d(A,B) = size(A - B) d(A,B)=size(A−B)
- d ( A , B ) = s i z e ( A − B ) + s i z e ( B − A ) d(A,B) = size(A - B) + size(B - A) d(A,B)=size(A−B)+size(B−A)
- 时间
- $d(t_1,t_2) = \begin{Bmatrix}
t_2-t_1 & 如果 t_1 \leq t_2 \
24+(t_2 - t_1) & 如果t_1 \geq t_2
\end{Bmatrix} $
- $d(t_1,t_2) = \begin{Bmatrix}
- 简单匹配系数
(
S
i
m
p
l
e
M
a
t
c
h
i
n
g
C
o
e
f
f
i
c
e
n
t
)
(Simple\ Matching\ Coefficent)
(Simple Matching Coefficent)
- SMC = n u m b e r o f m a t c h e s n u m b e r o f a t t r i b u t e s = M 11 + M 00 M 11 + M 00 + M 10 + M 01 \frac{number\ of\ matches}{number\ of\ attributes} = \frac{M_{11} + M_{00}}{M_{11} + M_{00}+M_{10} + M_{01}} number of attributesnumber of matches=M11+M00+M10+M01M11+M00
-
J
a
c
c
a
r
d
C
o
e
f
f
i
c
e
n
t
Jaccard\ Coefficent
Jaccard Coefficent
- J = M 11 M 11 + M 00 + M 10 + M 01 J = \frac{M_{11}}{M_{11} + M_{00}+M_{10} + M_{01}} J=M11+M00+M10+M01M11
余弦相似度
d ( a , b ) = a ⋅ b ∣ ∣ a ∣ ∣ ∗ ∣ ∣ b ∣ ∣ d(a,b) = \frac{a·b}{||a||*||b||} d(a,b)=∣∣a∣∣∗∣∣b∣∣a⋅b
不同属性的距离综合评估
- 对于不同属性通常会用不同的距离标准去衡量。
- 不同属性的重要性也可能不同
- 可以采取不同属性的距离进行加权求和的形式来解决这个问题
K N N KNN KNN
简单介绍
- 将个类训练样本划分为若干子类
- 在每一个子类中确定代表点
- 常见使用质心或者质心周围的点作为代表点
- 计算未知样本与这些代表点的距离,最近的作为决策结果
- 由于决策受代表点的影响很大,所以有可能导致错误率升高
代表点的选取
- 增加代表点的数量会使分类器效果增加吗?
- 将所有样本作为代表点。新样本与哪
k
k
k 个代表点最相似就基于投票多数类别决策。
- y ′ = a r g max y ∑ ( x i , y i ) ∈ D k I ( v = y i ) y' = arg\max\limits_y\sum_{(x_i,y_i)\in D_k}I(v = y_i) y′=argymax∑(xi,yi)∈DkI(v=yi)
- 通过对每一个最近邻的距离进行加权
- y ′ = a r g max y ∑ ( x i , y i ) ∈ D k w i ∗ I ( v = y i ) y' = arg\max\limits_y\sum_{(x_i,y_i)\in D_k}w_i*I(v = y_i) y′=argymax∑(xi,yi)∈Dkwi∗I(v=yi)
- w i = 1 d ( x ′ , x i ) 2 w_i = \frac{1}{d(x',x_i)^2} wi=d(x′,xi)21
对于 k k k 值大小的讨论
- k k k 值太小,则模型对噪声敏感程度大
- k k k 值太大,则可能误分类样例
- 使用交叉验证法选取最优 k k k 值
尺度变换非常重要
K D KD KD 树
- 对 k k k 维空间中的实例点进行存储以便于进行快速检索的树形数据结构
- 二叉树
- 是对 k k k 维空间的一种划分,划分边界垂直于坐标轴。
- 每一个节点对应于一个矩形区域
- 如果使用中位数作为切分点,那么得到的
k
d
kd
kd 树是平衡的
- 平衡的 k d kd kd 树效率未必是最优的
构造过程
- 构造根节点,选择 x 1 x_1 x1 为坐标轴,以样本在这个维度上的中位数进行划分,切分方向垂直于坐标轴。在根节点处保存对应的实例
- 对于深度为 j j j 的节点,选择 x l , l = j ( m o d k ) + 1 x_l,l = j(mod k) +1 xl,l=j(modk)+1 作为坐标轴,以该节点中的样本在维度上的中位数进行划分;在节点处保存实例。重复直至划分后的区域没有样本。
搜索过程
- 首先找到包含目标点的叶结点作为当前最近点:兄根节点出发,递归向下访问,每一次访问比较对应维度的大小,进入左节点或者右节点。
- 从叶节点出发回退
- 如果当前节点保存的样本距离比当前最近点的距离还小,则更新当前最近点。
- 当前最近点一定存在于该节点的某个子节点的区域,所以检查该节点的父节点的另一子节点的区域中是否有更近的点
- 如果有,则移动到另一个节点。递归进行搜索
- 如果没有,向上回退,递归搜索。
- 回退至根节点时,搜索结束。返回当前最近点。
当维数较大时, k d kd kd 树的搜索效率降低,只有当 N N N 远大于 2 D 2^D 2D 时,效率优势明显。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









