









 本文探讨了维度灾难问题以及为解决此问题提出的两种主要方法:监督降维的LDA和无监督降维的PCA。PCA通过坐标变换和最小化重构误差来寻找数据的主要成分,而SVD等价于PCA,两者都涉及求解矩阵的特征值。在PCA中,低维表示最大化方差,使得数据在各个维度上分散且不相关。LDA则侧重于最大化类别间的方差。博客还介绍了PCA和SVD的算法流程及性质。
本文探讨了维度灾难问题以及为解决此问题提出的两种主要方法:监督降维的LDA和无监督降维的PCA。PCA通过坐标变换和最小化重构误差来寻找数据的主要成分,而SVD等价于PCA,两者都涉及求解矩阵的特征值。在PCA中,低维表示最大化方差,使得数据在各个维度上分散且不相关。LDA则侧重于最大化类别间的方差。博客还介绍了PCA和SVD的算法流程及性质。
PCA与SVD
本文属于查缺补漏,赶紧来复习一下
先贴上本文参考链接
后面公式涉及到大量矩阵打起来实在不方便,就贴图了
一、起因
其起因在于我们常说的维度灾难,许多学习的方法都会涉及到距离计算,而高维空间会给距离计算带来很多麻烦。
数据样本稀疏、距离计算困难等问题是所有机器学习方法共同面临的严重障碍,即我们常说的维度灾难
为解决该问题,主要提出了两种解决方法
监督降维方法: 线性判别分析 LDA
无监督降维方法: PCA
对应的评估方法: 比较前后学习器性能
注意事项: 常见的这些降维算法,主要还是基于距离来计算重构误差,需要对特征进行标准化来避免量纲对距离计算产生的影响
二、主成分分析 PCA
用起来很快乐,面试被问到立马痛苦了起来
一、坐标变换
我们期望能够将 N N N维的特征降维到 D D D,这里我们用 X X X表示 N N N维的特征矩阵, Z Z Z为降维后的特征矩阵, W W W为坐标变换矩阵
则有
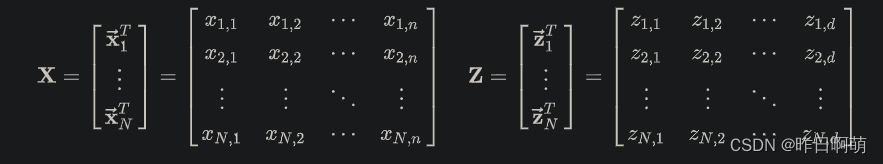
其中
Z
=
W
T
X
Z = W^{T} X
Z=WTX 对于
z
i
,
j
=
∑
w
i
∗
x
j
z_{i,j} = \sum{w_i*x_j}
zi,j=∑wi∗xj 即w的对应行乘以x的对应列再求和。
本质上就是通过线性组合原始特征,保留重要的信息,降低特征维度
二、重构误差
考虑对
z
z
z进行重构,重构后的样本为
x
^
=
W
z
\hat{x} = W z
x^=Wz
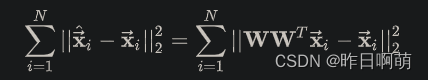
而我们PCA降维要求重构误差最小,因此可以变成求解如下的优化问题:
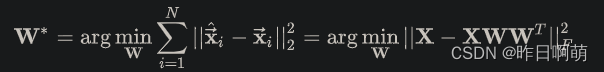
经过一系列简化(推到见参考链接)可以得到如下问题

同时满足约束
W
T
W
=
I
d
∗
d
W^TW = I_{d*d}
WTW=Id∗d
可以看到,我们要求解
W
W
W的本质就是求解
X
T
X
X^TX
XTX的特征值
只需要对矩阵 X T X X^TX XTX进行特征值分解,将求得的特征值排序,取前d个特征对应的单位特征向量构成坐标变化矩阵 W W W就可以了
如果样本数据进行了中心化, X T X X^TX XTX就是样本集的协方差矩阵。
如何做特征值分解?
对于
A
x
=
λ
x
Ax = \lambda x
Ax=λx,其中
λ
\lambda
λ为特征值,
x
x
x为特征向量
前提条件:方阵,满秩
将矩阵分解为
A
=
P
Λ
P
−
1
A = P\Lambda P^{-1}
A=PΛP−1,其中
P
P
P为矩阵
A
A
A的特征向量组成的矩阵。
Λ
\Lambda
Λ 为特征值组成的对角矩阵。
三、算法

四、性质

给定协方差矩阵
X
T
X
X^TX
XTX,通过坐标变化得到如上矩阵
可以看到,任意一对特征之间协方差为0,也就是说数据在每个维度上尽可能的分散,任意两个维度之间不相关。
PCA中,低维和高维空间必然不同,因为有n-d个最小特征值对应的特征向量被抛弃了
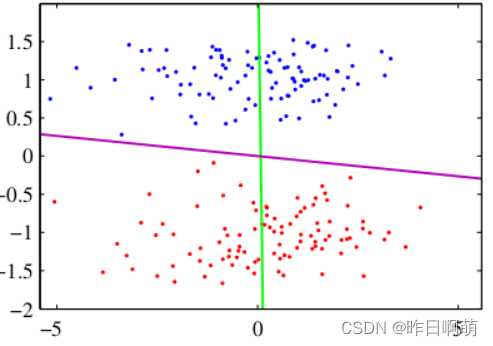
LDA也可以用于降维但是与PCA不同的是
LDA: 向类别区分最大的方向投影,如下图绿色线
PCA:向方差最大的方向头型,如下图紫色线
奇异值分解(SVD)
首先,我们有酉矩阵 U H U = U U H = I U^{H}U = UU^{H} = I UHU=UUH=I
一、奇异值分解
设X为
N
∗
n
N*n
N∗n阶矩阵,且
r
a
n
k
(
X
)
=
r
rank(X) = r
rank(X)=r 则存在
N
N
N阶酉矩阵
V
V
V和
n
n
n届酉矩阵
U
U
U,使得
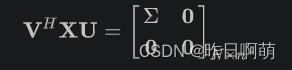
其中

因此,我们有如下表达式

更进一步可以得到

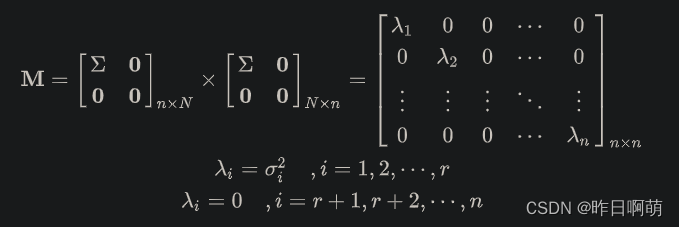
最后可以得到
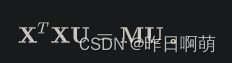
因此,SVD等价于PCA,核心都是求解 X T X X^{T}X XTX的特征值以及对应的单位特征向量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









