









参考:
面试题:InnoDB中B+树有几层?_Running-Waiting的博客-优快云博客_b+树有几层
mysql单表最多两千万条数据?
先说结论:一般B+树高大约为1~3层(通过主键索引查询,通常磁盘io数为1~3次),可容纳记录数约2000w条
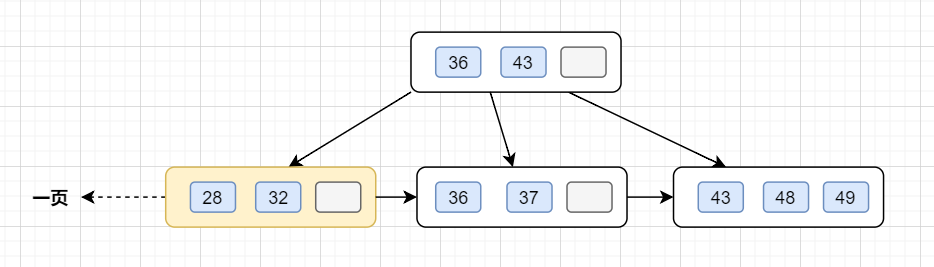
在 MySQL 中我们的 InnoDB 页的大小默认是 16k,当然也可以通过参数设置。
在查找数据时一次页的查找代表一次 IO,所以通过主键索引查询通常只需要 1~3 次 IO 操作即可查找到数据。
1、MySQL的InnoDB存储引擎的最小存储单元是页(大小默认是16k,可通过参数设置)。页可用于存放B+树叶节点数据,也可用于存放B+树非叶节点的 “键 + 指针”。
2、索引组织表通过非叶节点的 “二分查找” 法以及指针确定数据在下一层的哪个页中,进而再去叶节点的数据页中查找到所需数据。
一个非叶节点可容纳约1170个指针,这里假设一行记录数据大小为 1k,那么底层叶节点一页16k就能存16条记录。叶节点数 * 一个叶节点能存放的记录数 = 1170 * 16 = 18720条 记录数。具体推导过程如图: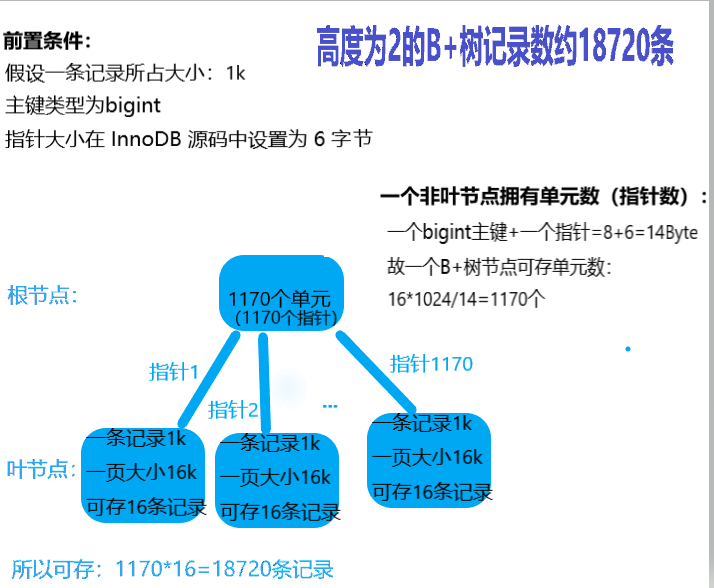
同理可得:高度为3的B+树能存的记录数为:1170*1170*16=21902400,2190w条记录,约2000w条记录。
为什么MySQL用B+树而不用B树呢?
因为B树不管叶子节点还是非叶子节点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少(有些资料也称为扇出),指针少的情况下要保存大量数据,只能增加树的高度,导致IO 操作变多,查询性能变低。
总结:
- B+树叶子和非叶子节点的数据页都是16k,且数据结构一致,区别在于叶子节点放的是真实的行数据,而非叶子节点放的是主键和下一个页的地址。
- B+树一般有两到三层,由于其高扇出,三层就能支持2kw以上的数据,且一次查询最多1~3次磁盘IO,性能也还行。
- 存储同样量级的数据,B树比B+树层级更高,因此磁盘IO也更多,所以B+树更适合成为MySQL索引。
- 索引结构不会影响单表最大行数,2kw也只是推荐值,超过了这个值可能会导致B+树层级更高,影响查询性能。
- 单表最大值还受主键大小和磁盘大小限制。

















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









