







终于更新了,实在太忙了
Imitation Learning
5.1 Recap
We have covered so far :
- Traditional robotics method
- Kinematic, planning, control
-
Pose estimation and camera geometries
-
6DoF pose estimation for instance, category, unknown object
-
Camera calibration, 2D to 3D projection
-
Get the geometric information of the object and environment
-
Grasping
- Traditional grasping pipeline
- Learning-based grasping
- 2D plannar, 6DoF, multi-finger grasping
5.2 Intro to Imitation Learning
在机器人技术的背景下,示范学习 (LfD)、示范编程 (PbD) 和模仿学习 (IL) 是密切相关的范式,都涉及到使机器人能够学习任务或从人类演示中派生控制器。虽然这些术语通常可以互换使用,但根据上下文的不同,它们在重点或范围上可能有细微的差别。
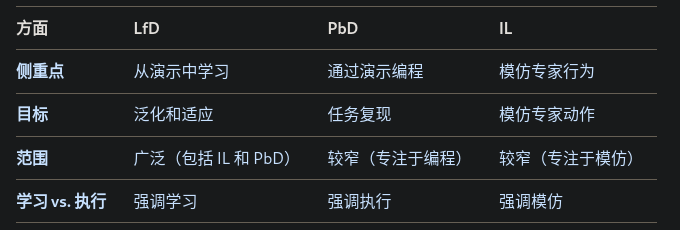
著名的工作ACT, DP

T
• Given: expert demonstration data, or demonstrator
• Goal: learn a policy that mimics the expert
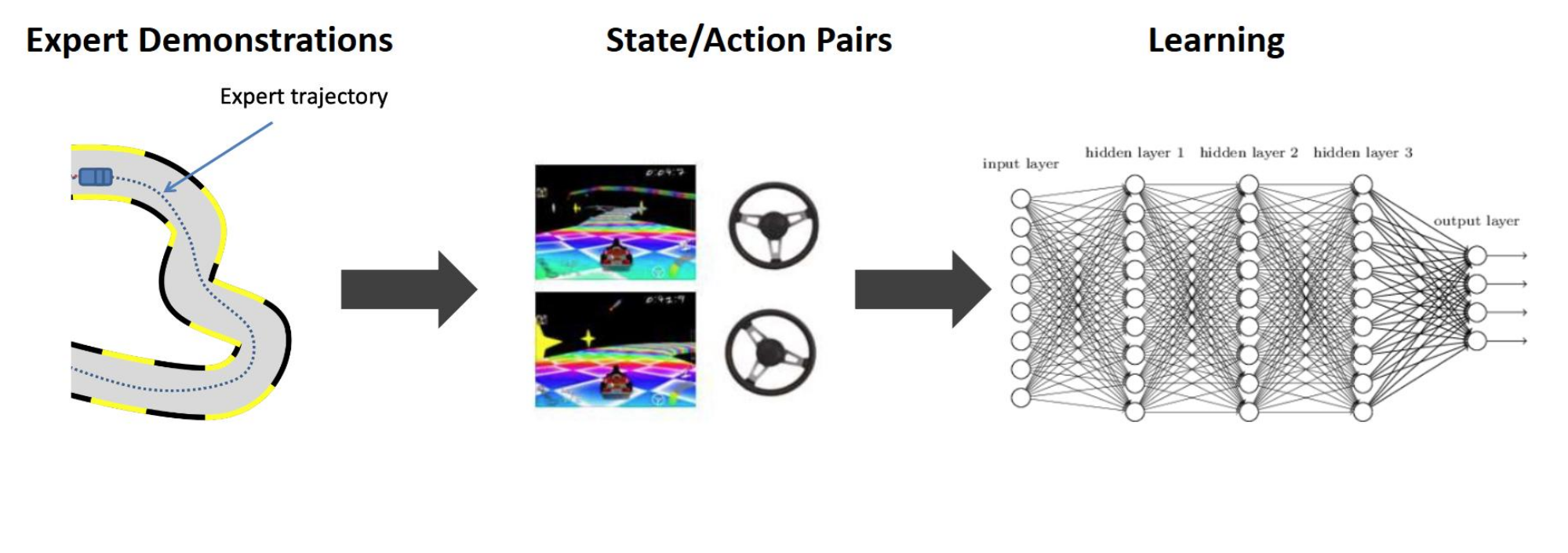
Learn a control policy from dataset
Autonomous driving:
• Input: vector space, or image, or BEV
• Output : trajectory, or control output
Robotic manipulation (act)
• Input: image, joint state
• Output: sequence of joint command.
ChauffeurNet
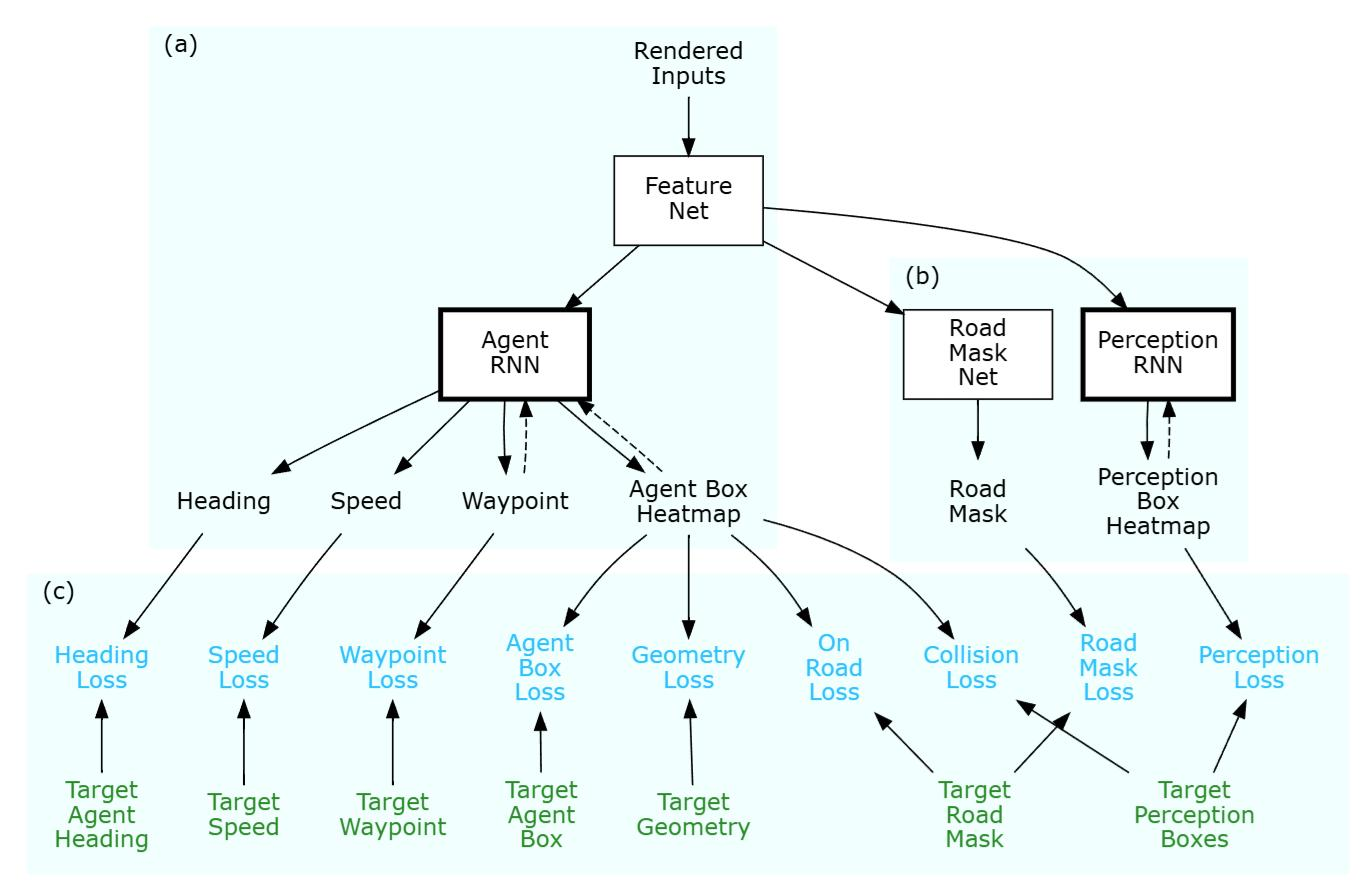
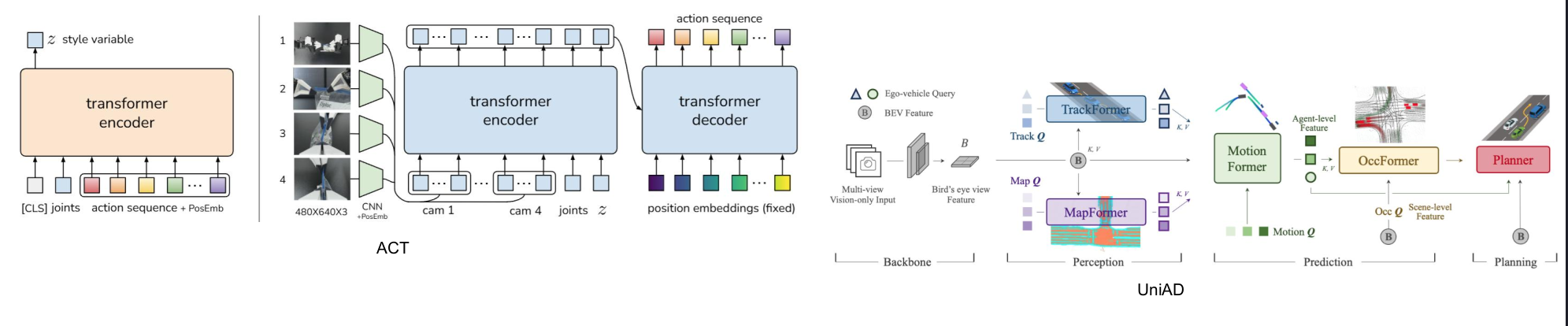
Learning Objective:
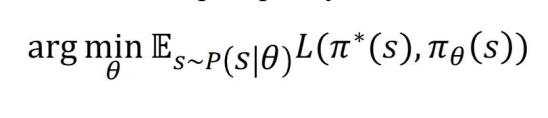
Behavior Cloning
• Simplistic supervised learning formulation
• Requires expert data (s, a)
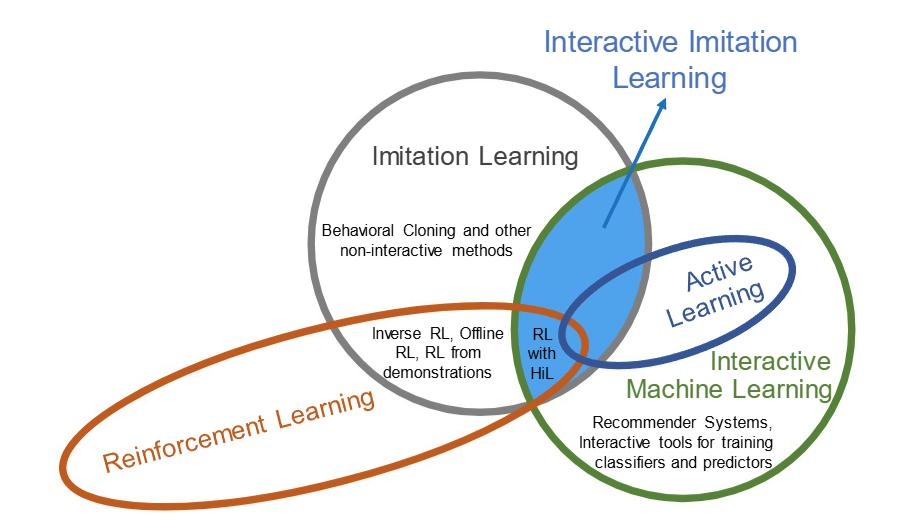
Interactive Imitation Learning
• Experts help to interactively generate policy and data
• Requires expert policy (in addition to the data)
• Dagger
Inverse Reinforcement Learning
• RL formulation
• Reward learning
MDP: Overview

5.3 Behavior Cloning
T : Mimic the expert with collected data (s, a*)
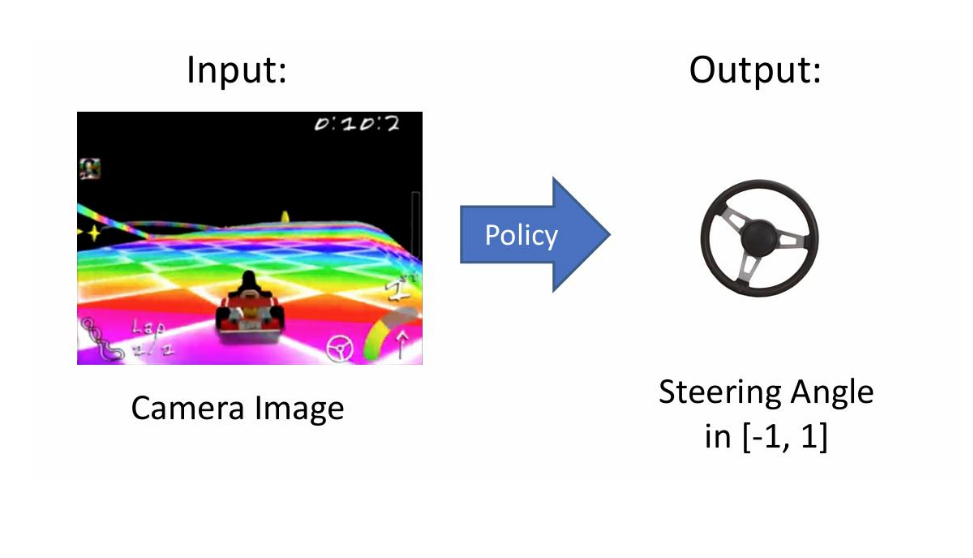
object;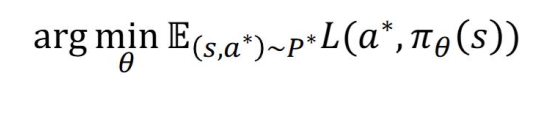
Learning
• Minimize Loss of collected expert trajectory (s, a*)
p Policy:
• Action from given state s
π θ ( s ) , o r π ( s ) \pi_{\theta}(s), or \pi(s) πθ<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 128
128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









