






1. Introduction
在机器人技术领域,处理复杂任务一直是一个重要的挑战。这些任务通常具有长时间跨度、上下文依赖性和精细的操作要求,可能需要多次尝试和重新工作。为了应对这些挑战,研究人员开发了多种机器人学习方法和视觉-语言-动作(VLA)模型。
机器人学习的挑战
长时间跨度任务:机器人需要执行一系列子任务,这些任务可能需要长时间才能完成。
上下文依赖性:任务的成功执行依赖于对环境的理解和上下文信息。
精细操作:机器人需要具备高精度的操作能力,例如抓取和操纵物体。
可能的失败和重新工作:在复杂任务中,机器人可能会遇到失败,并需要重新尝试。
分层框架
高层规划器(VLM/LLM):负责从人类指令中分解任务。
低层操作技能(Visuomotor Policy):执行具体的操作任务,一个模型可以用于多个操作任务。
控制器:负责轨迹优化、滤波和力控制。

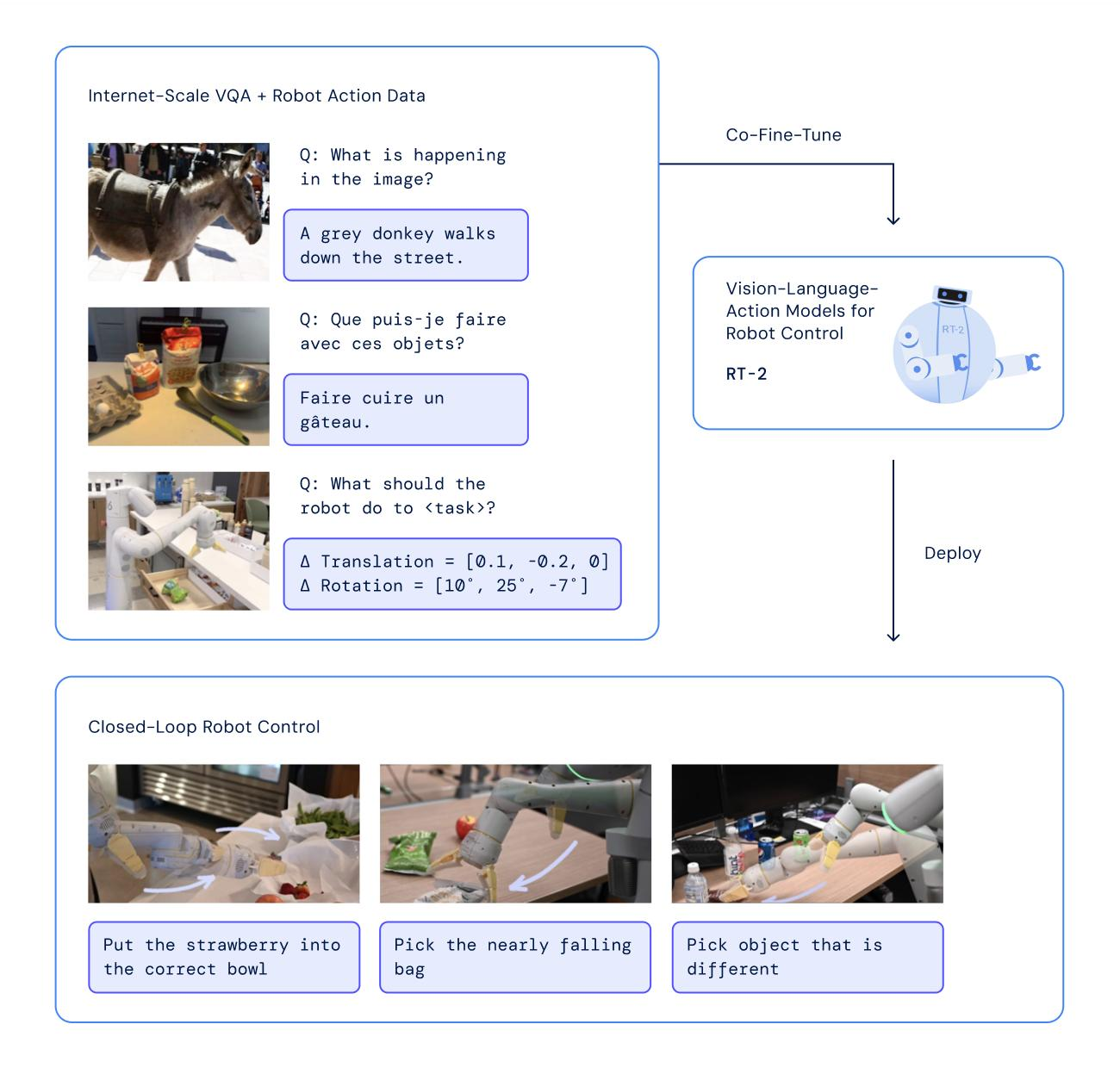
自动驾驶中的应用
在自动驾驶领域,VLA模型通过鸟瞰图(BEV)视觉表示和多任务学习来处理检测、跟踪、映射、预测和规划等任务。输出规划的轨迹,并在动态和多样化的环境中与交通参与者进行交互。
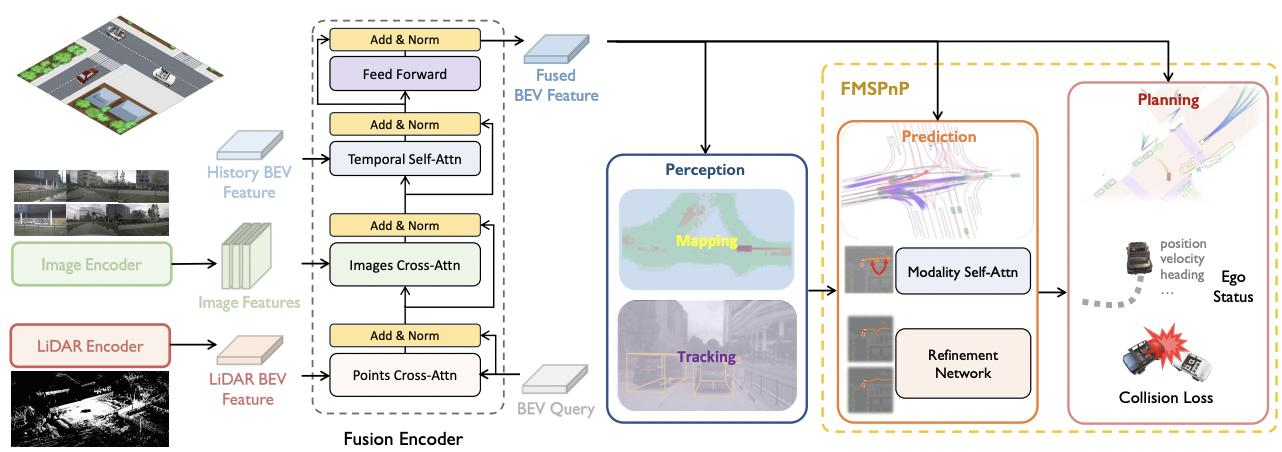
2. Transformers and Generative Model
Transformer 模型概述
T: 是一种基于自注意力机制的神经网络架构.
W: 广泛应用于自然语言处理(NLP)和其他序列到序列的任务中。
以下是 Transformer 模型的关键组成部分和工作原理的总结:
1. 自注意力机制(Self-Attention)
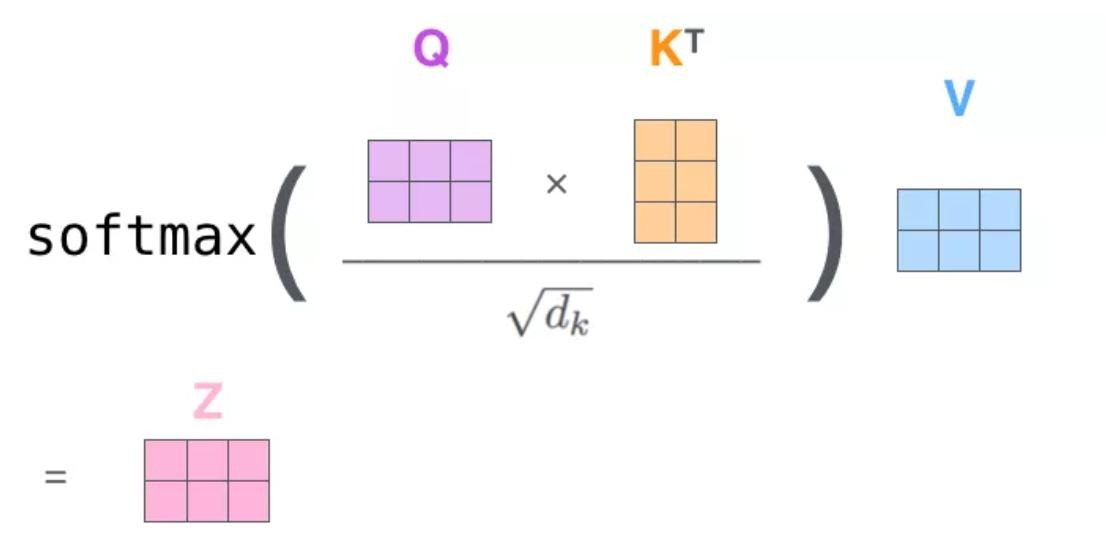
- 缩放点积注意力(Scaled Dot-Product Attention):计算输入序列中每个元素与其他元素的相关性。通过点积计算注意力分数,然后进行缩放和 softmax 归一化,得到注意力权重。
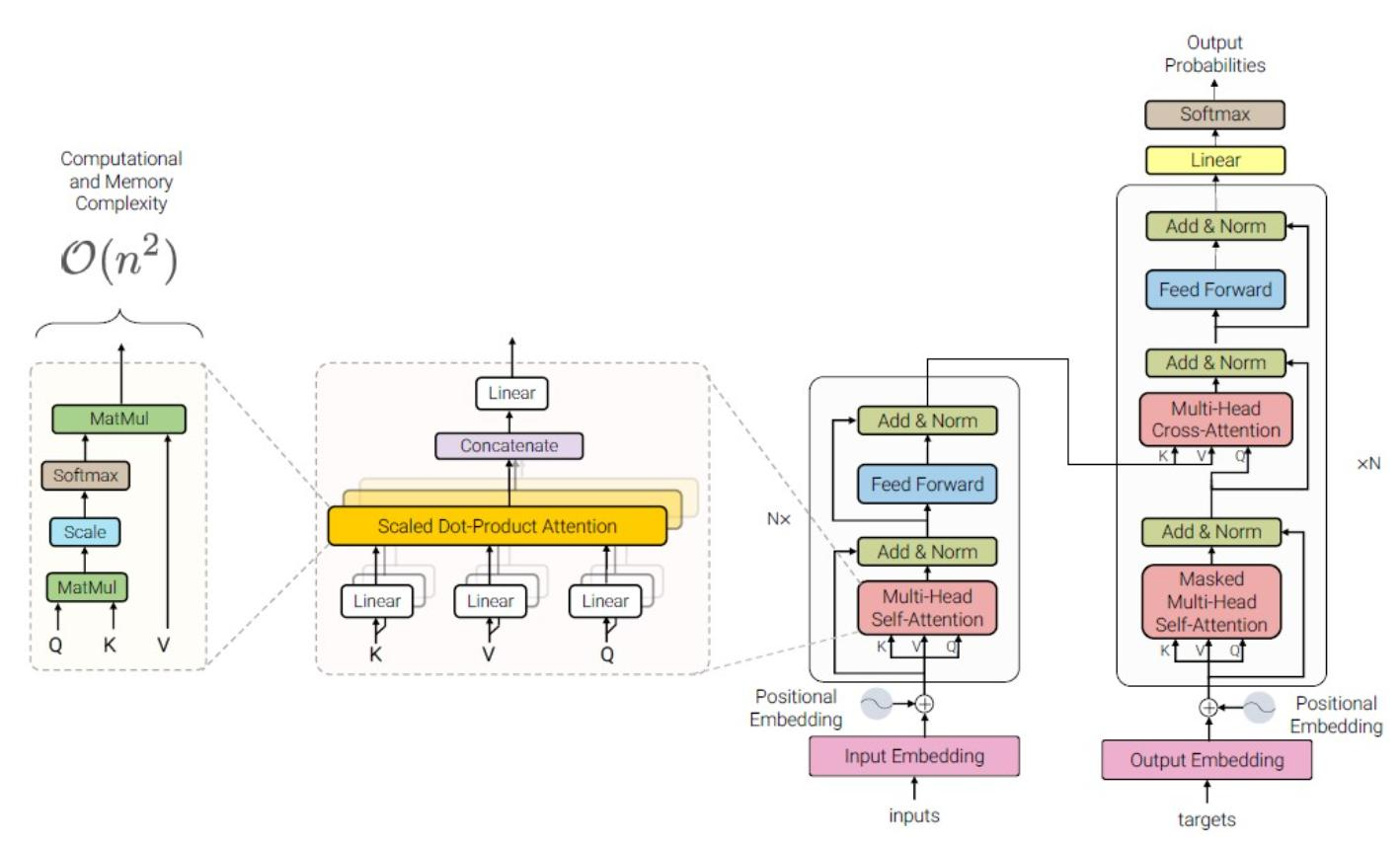
- 多头注意力(Multi-Head Attention):将输入序列分成多个头,每个头独立计算注意力,最后将结果拼接起来。这允许模型同时关注不同位置的信息。
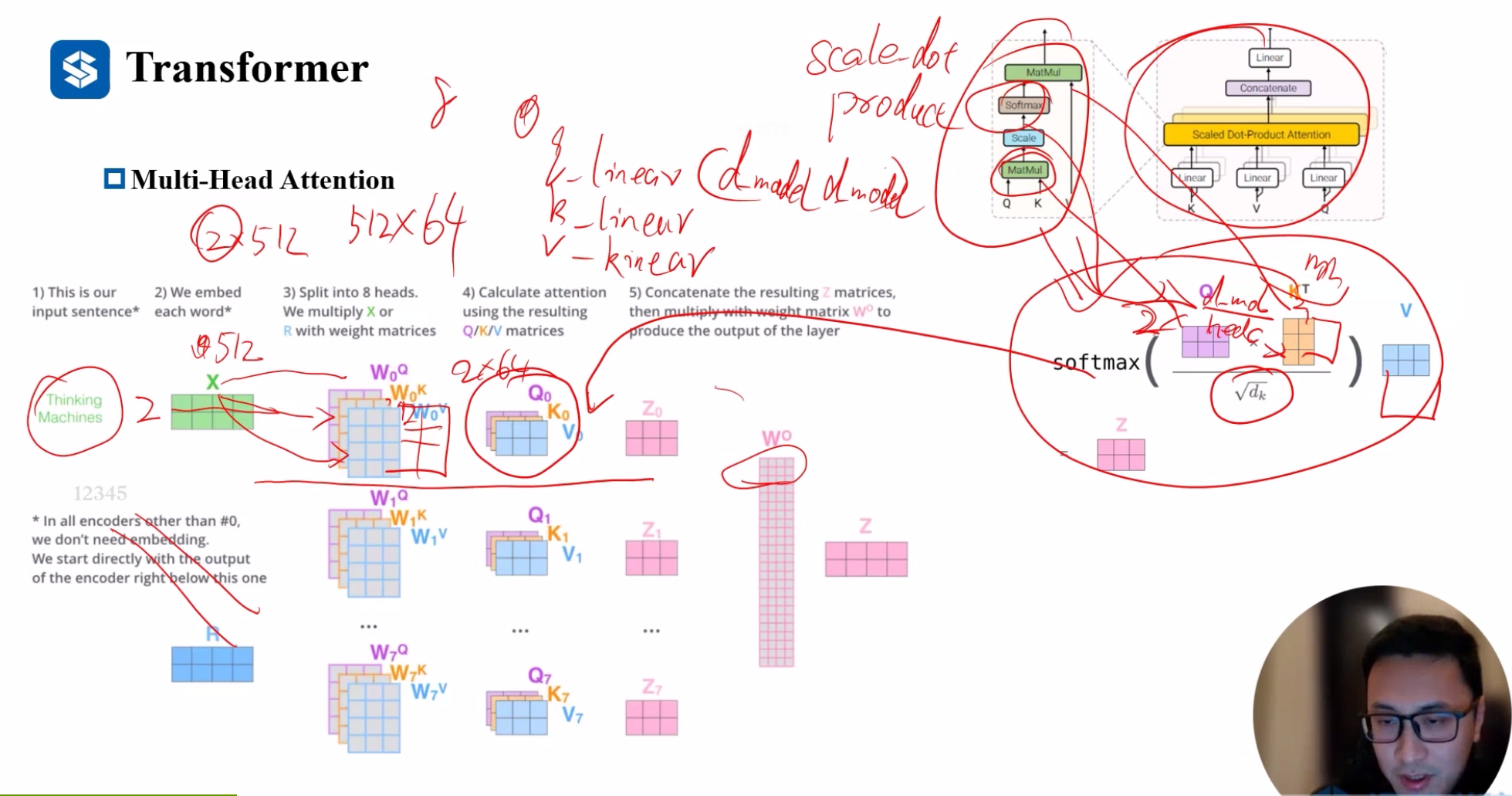

2. 编码器和解码器(Encoder and Decoder)
- 编码器:由多个相同的层组成,每层包含多头注意力机制和前馈神经网络。编码器将输入序列转换为一系列隐藏表示。

- 解码器:也由多个相同的层组成,每层包含多头注意力机制、编码器-解码器注意力机制和前馈神经网络。解码器根据编码器的输出和之前的输出生成目标序列。

3. 位置编码(Positional Encoding)
- 由于 Transformer 模型不使用循环神经网络(RNN)或卷积神经网络(CNN),因此需要位置编码来注入序列中元素的位置信息。位置编码通常使用正弦和余弦函数生成。
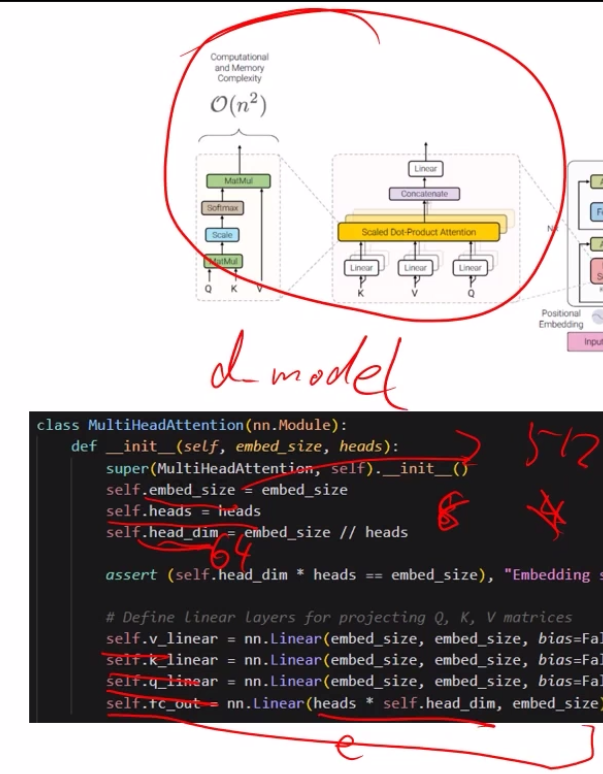
4. 计算和内存复杂度
- Transformer 模型的计算和内存复杂度为
(
O
(
n
2
)
)
(O(n^2))
(O(n2)),其中 (n) 是序列长度。这是因为自注意力机制需要计算所有元素对之间的相关性。
https://pytorch.org/docs/stable/generated/torch.nn.MultiheadAttention.html
https://github.com/pytorch/pytorch/blob/v2.5.0/torch/nn/modules/activation.py#L973
5. 输出概率
- 模型的输出是通过 softmax 函数计算的概率分布,表示每个位置可能的下一个元素。
6. 输入和目标
- 输入是源序列,目标是模型需要生成的序列。在训练过程中,模型通过最小化预测和目标之间的差异来学习。

总结
Transformer 模型通过自注意力机制和多头注意力机制有效地捕捉序列中的长距离依赖关系,成为许多 NLP 任务的基础架构。其编码器-解码器结构和位置编码机制使其在处理序列数据时表现出色。尽管计算复杂度较高,但其强大的表现力和灵活性使其成为现代深度学习中的重要工具。
transformer arch
编码器与解码器协同工作
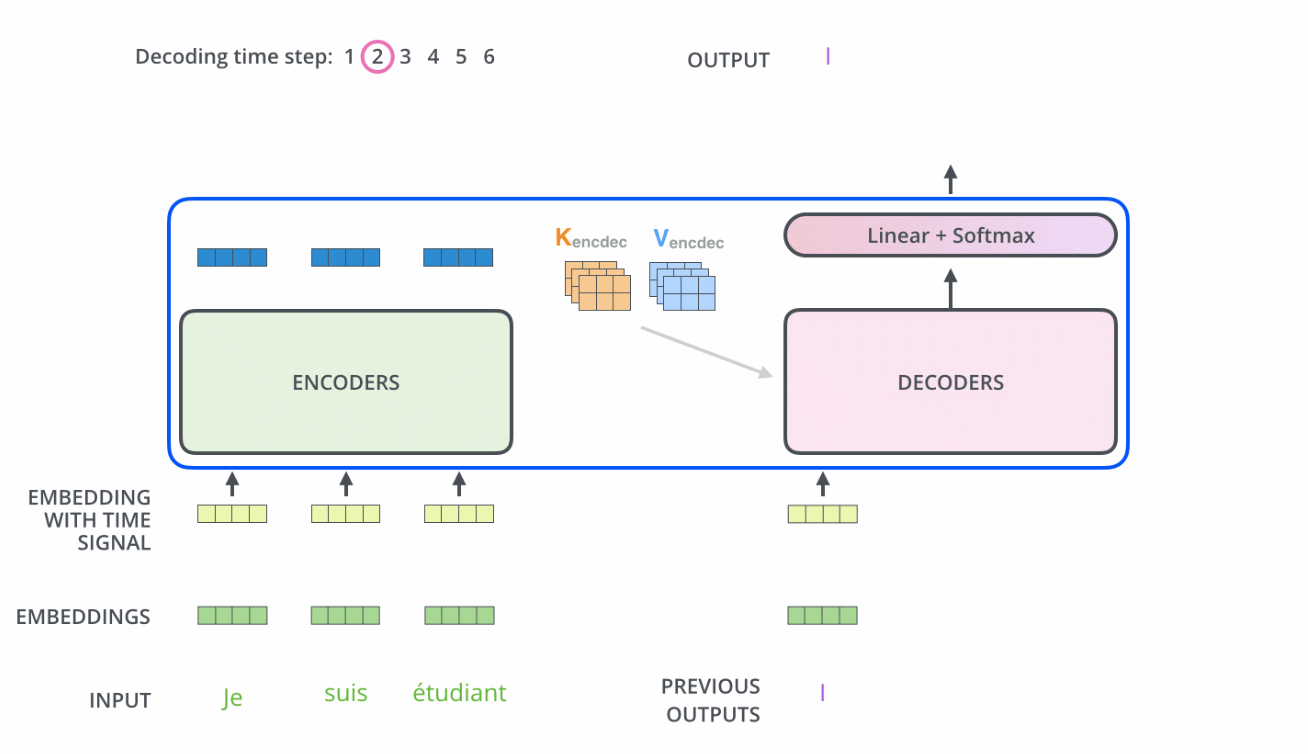
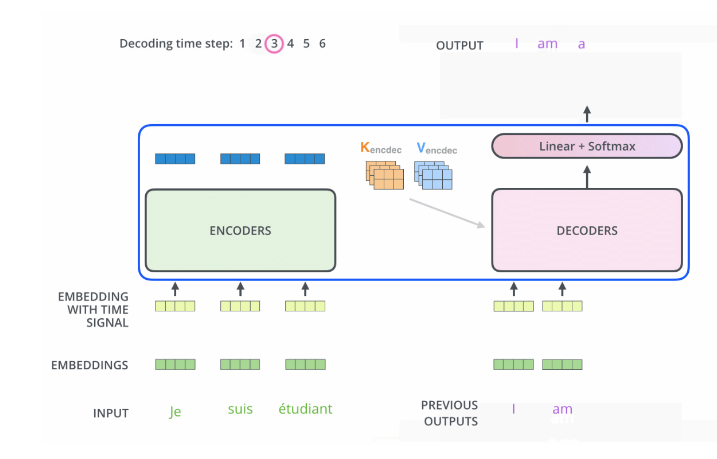
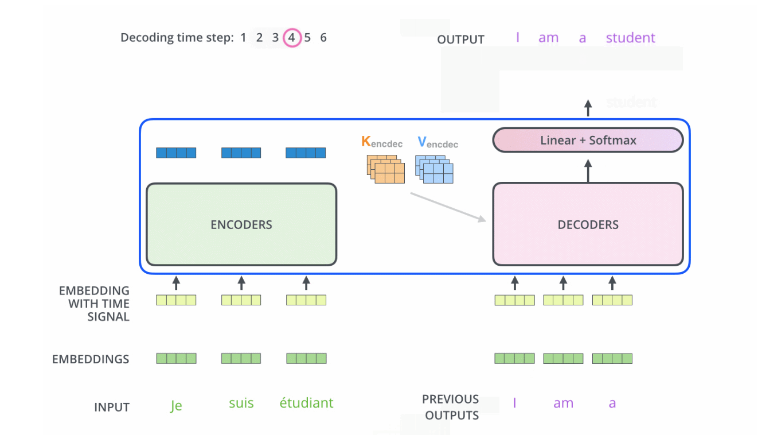
- Encoder中的Q、K、V全部来自于上一层单元的输出,而Decoder只有Q来自于上一个Decoder的输出,K,V来自Encoder最后一层的输出.
比如当我们要把“Hello Word”翻译为“你好,世界”时
Decoder会计算“你好”这个query分别与“Hello”、“Word”这两个key的相似度
很明显,“你好”与“Hello”更相似,从而给“Hello”更大的权重,从而把“你好”对应到“Hello”,达到的效果就是“Hello”翻译为“你好”
- 自注意力模块只关注已输出的位置的信息, 因为在解码器中加入了masked机制.实现方法是在自注意力层前的softmax操作之前,将未输出位置的权重设置为一个非常大的负数,从而使其经过softmax后接近于0,相当于屏蔽输出
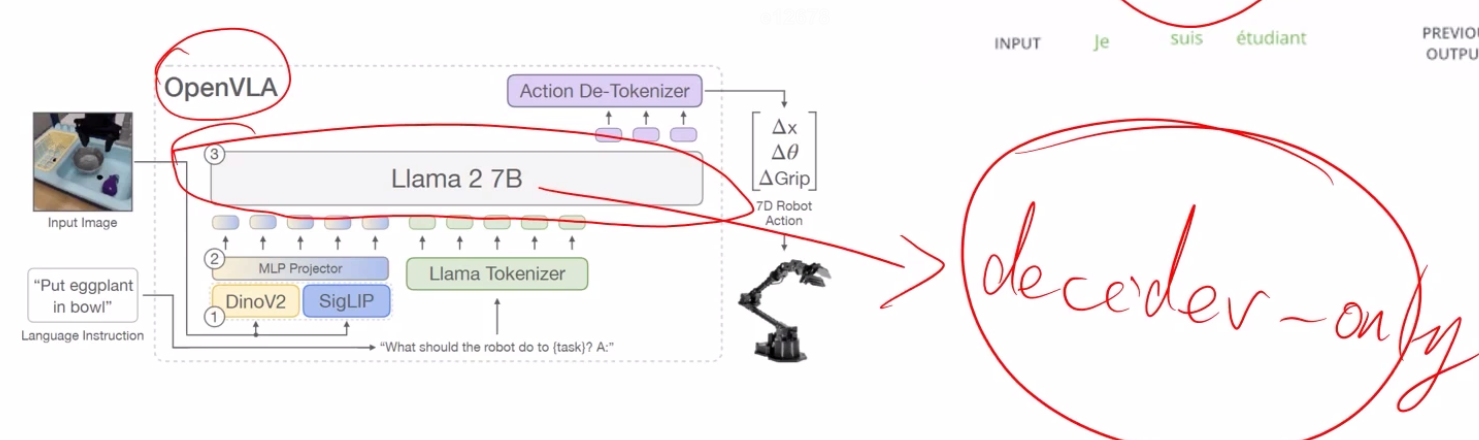
仅仅解码器
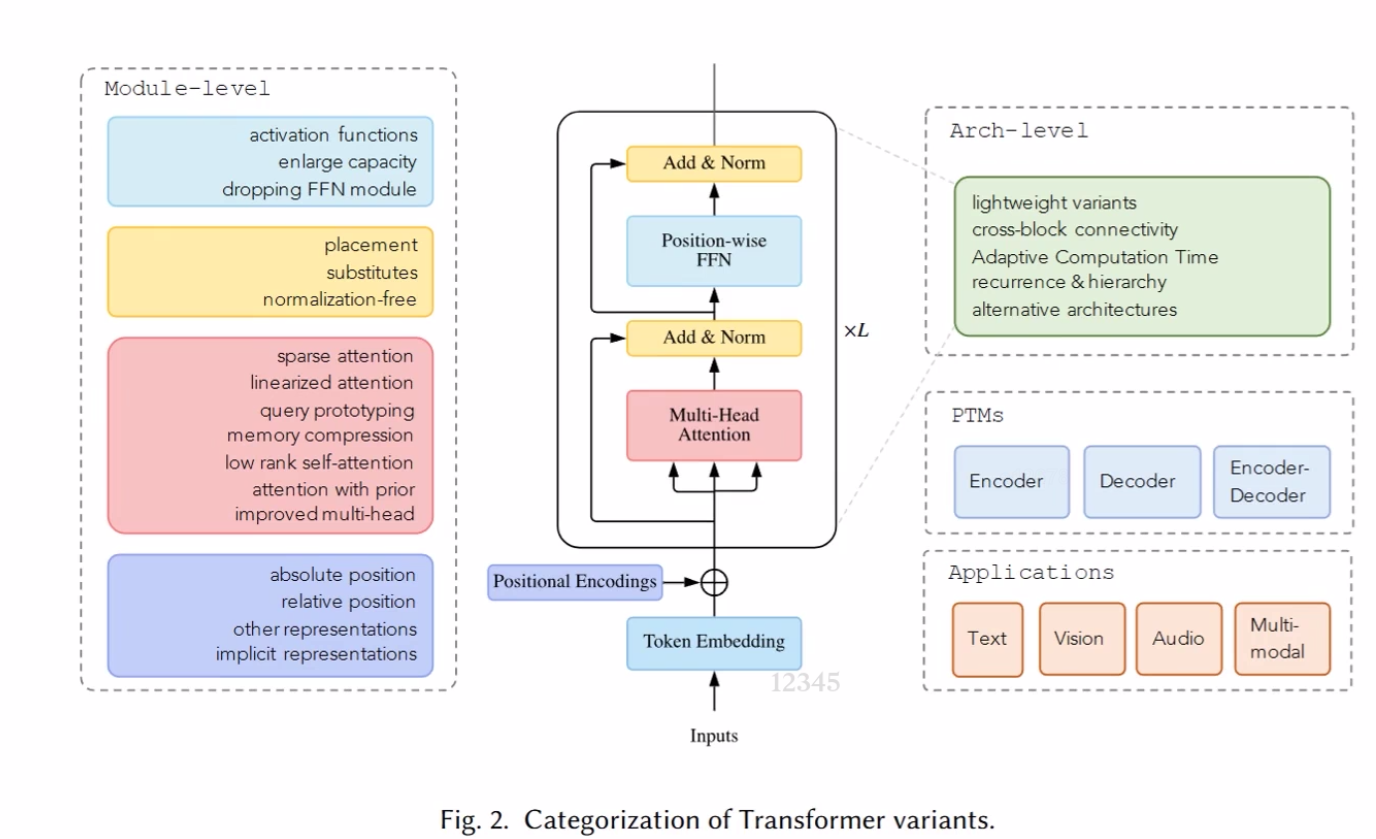
Transformer Variant
Generative Model
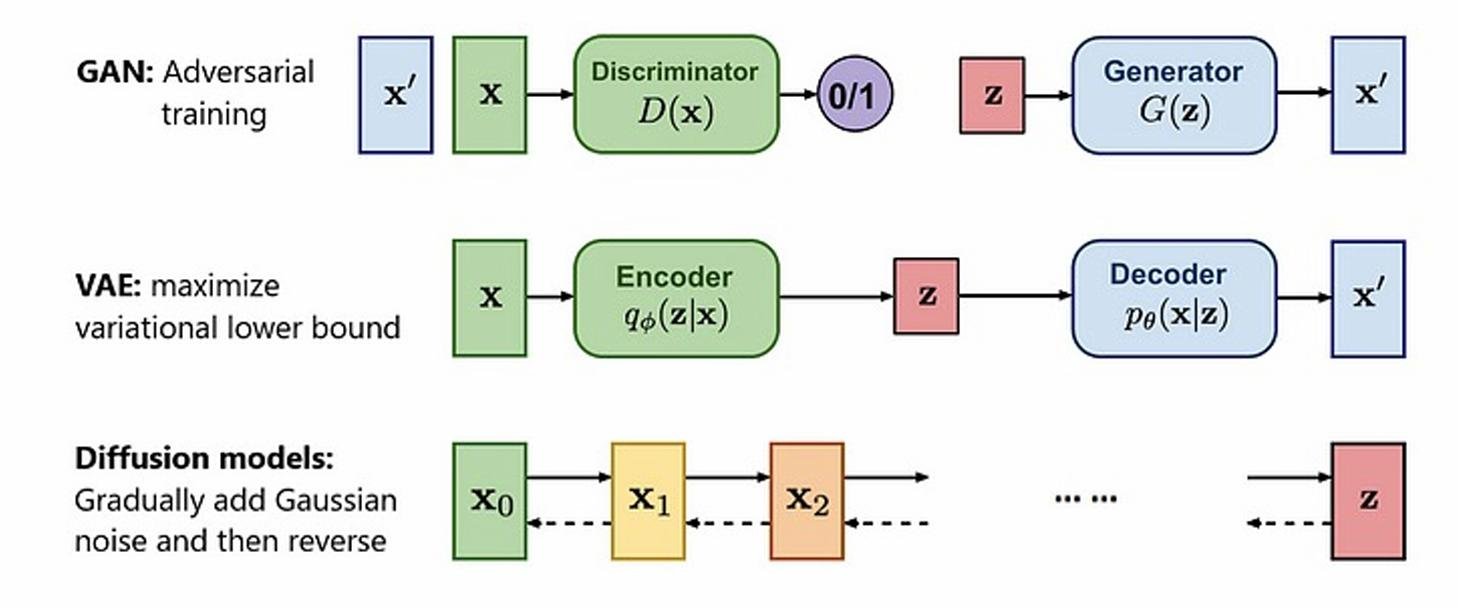
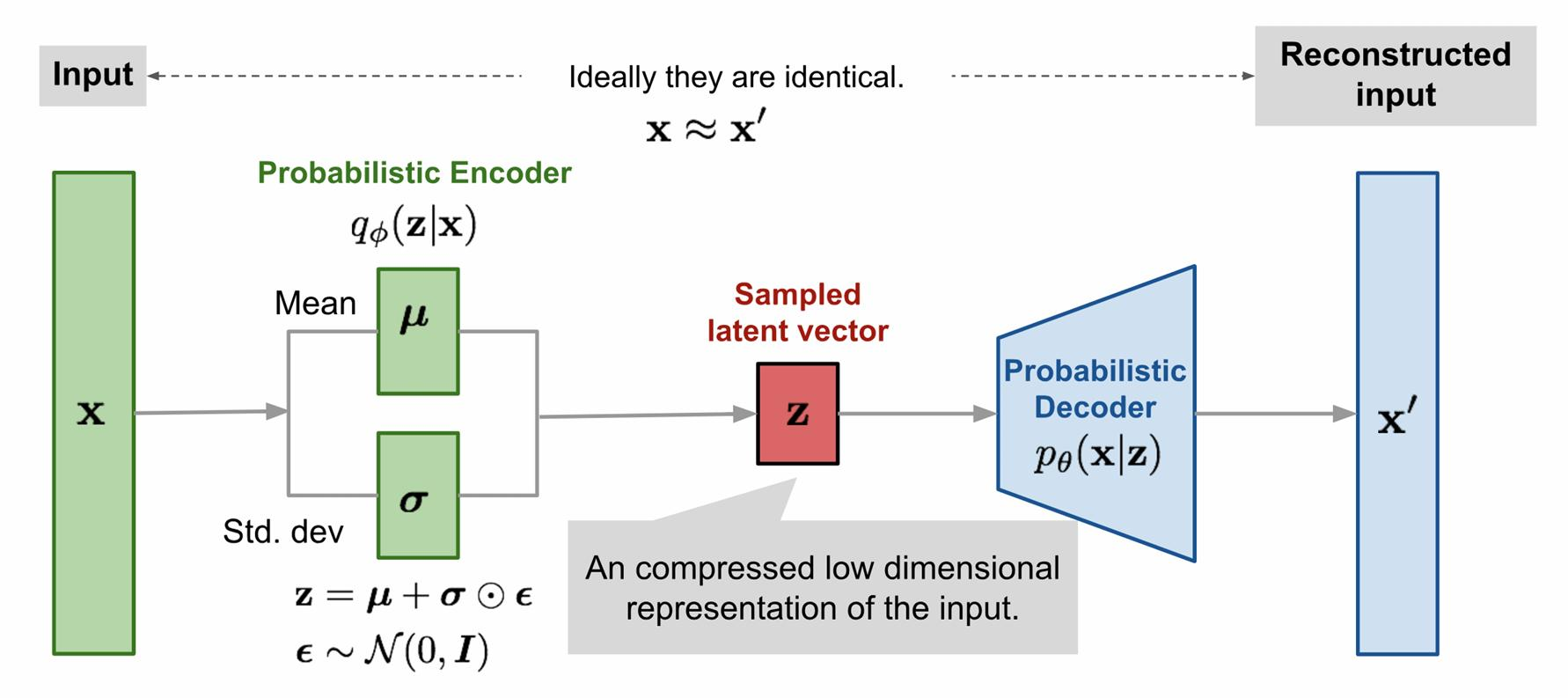
Variational Auto Encoder
• An encoder to learn the latent distribution
• A decoder to reconstruct the original input
• Similar to Auto Encoder, but used differently
Sampling
• Sampling z from learnt distribution, and then use decoder to generate
Diffusion Model
• Could be treated as a special VAE
• Add noise process to generate the distribution
• Model is used to predict the noise (remove noise) and reconstruct the original input
- Usually use gaussian noise and use network to reconstruct denoise process


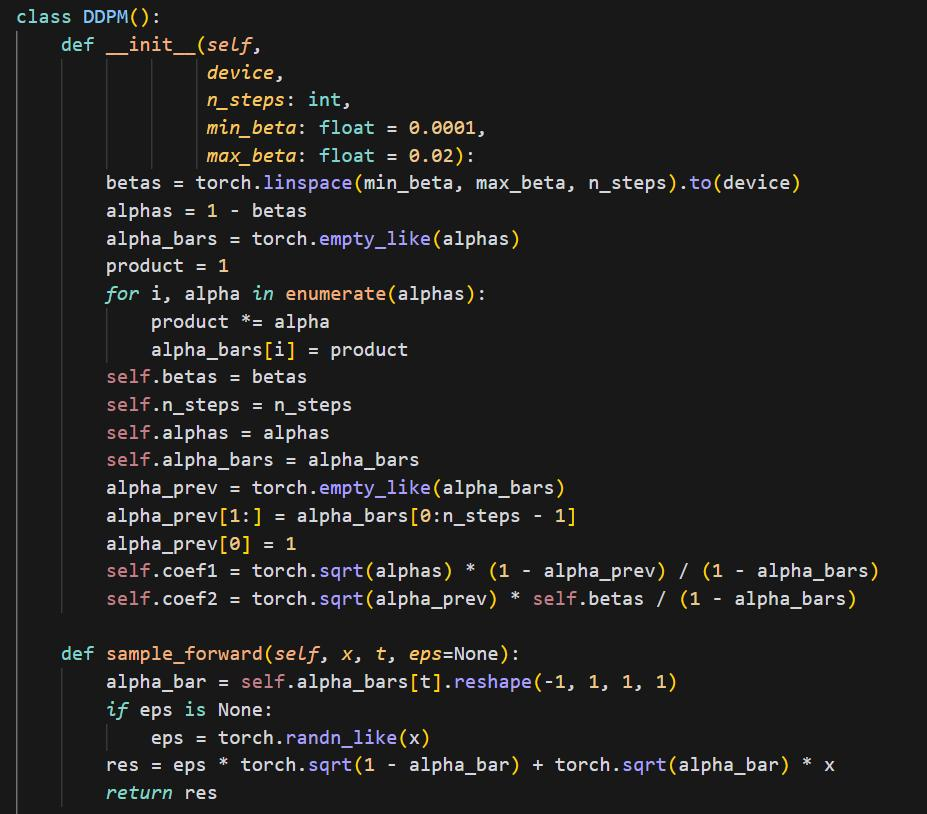
DDPM (Denoising Diffusion Probabilistic Models)
Predict the noise based on the noisy image and step t
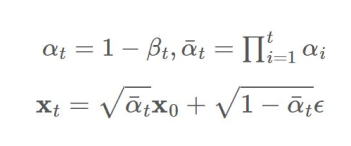
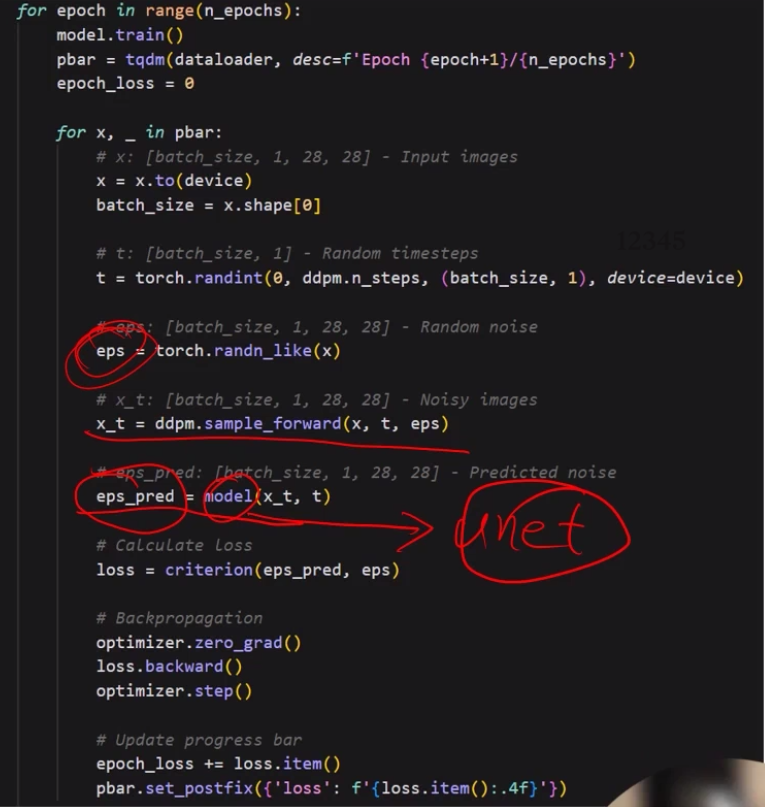
Training
• Only use DDPM forward step
• Add noise and predict the noise (using noisy image
and time step t)
• MSE Loss

其他方法
- 替代结构:
- 注意力机制:可以将 Transformer 的注意力机制引入 U-Net 结构,提升模型的特征处理能力。
- DenseNet:可以使用DenseNet结构在U-Net中,逐层连接,每一层都可以接收来自前面所有层的信息,从而提高特征复用能力。
- 预处理与后处理:在输入图像时进行增强光照、噪声去除等处理,可以帮助提高模型性能。
- 多尺度特征融合:在上采样过程中,可以尝试使用不同层的特征而不仅仅是上一层的特征,从而获得更细致的特征融合。
ref
Transformer代码实现
https://www.shenlanxueyuan.com/course/727/task/29946/show


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









