







 本文介绍了卷积神经网络(CNN)的基本原理,包括其生物灵感和在图像处理中的作用。然后详细讲解了PyTorch中的torch.nn库,用于构建和训练神经网络,特别是卷积层的关键参数。接着,通过一个手写数字分类的案例,演示了如何使用torch.nn加载MNIST数据集,创建模型,设置损失函数和优化器,以及进行训练和测试。最后,讨论了结果的可视化方法。
本文介绍了卷积神经网络(CNN)的基本原理,包括其生物灵感和在图像处理中的作用。然后详细讲解了PyTorch中的torch.nn库,用于构建和训练神经网络,特别是卷积层的关键参数。接着,通过一个手写数字分类的案例,演示了如何使用torch.nn加载MNIST数据集,创建模型,设置损失函数和优化器,以及进行训练和测试。最后,讨论了结果的可视化方法。
目录
4.1 卷积神经网络
1.为什叫卷积神经网络?
CNN的确是从视觉皮层的生物学上获得启发的。简单来说:视觉皮层有小部分细胞对特定部分的视觉区域敏感。例如:一些神经元只对垂直边缘兴奋,另一些对水平或对角边缘兴奋。CNN工作概述指的是你挑一张图像,让它历经一系列卷积层、非线性层、池化(下采(downsampling))层和全连接层,最终得到输出。正如之前所说,输出可以是最好地描述了图像内容的一个单独分类或一组分类的概率。
2.什么是卷积?
i.卷积是指将卷积核应用到某个张量的所有点上,通过将卷积核在输入的张量上滑动而生成经过滤波处理的张量。
ii.总结起来一句话:卷积完成的是对图像特征的提取或者说信息匹配,当一个包含某些特征的图像经过一个卷积核的时候,一些卷积核被激活,输出特定信号。
iii.我们训练区分猫狗的图像的时候,卷积核会被训练,训练的结果就是,卷积核会对猫和狗不同特征敏感,输出不同的结果,从而达到了图像识别的目的。
4.2 torch.nn库
torch.nn是专门为神经网络设计的模块化接口。nn构建于autograd之上,可以用来定义和运行神经网络。主要模块包含 nn.Parameter nn.Linear nn.functional nn.Module nn.Sequential以及常用的卷积层和损失函数。
卷积层 conv2d
非线性变换层 relu/sigmiod/tanh
池化层 pooling2d
全连接层 w*x + b
如果没有这些层,模型很难与复杂模式匹配,因为网络将有过多的信息填充,也就是其他那些层作用就是突出重要信息,降低噪声。将最后的输出与全部特征连接,我们要使用全部的特征,为最后的分类的做出决策。最后配合softmax进行分类。
nn.conv2d解析
in_channels
这个很好理解,就是输入的四维张量[N, C, H, W]中的C了,即输入张量的channels数。这个形参是确定权重等可学习参数的shape所必需的。
out_channels
也很好理解,即期望的四维输出张量的channels数,不再多说。
kernel_size
卷积核的大小,一般我们会使用5x5、3x3这种左右两个数相同的卷积核,因此这种情况只需要写kernel_size = 5这样的就行了。如果左右两个数不同,比如3x5的卷积核,那么写作kernel_size = (3, 5),注意需要写一个tuple,而不能写一个列表(list)。
stride = 1
卷积核在图像窗口上每次平移的间隔,即所谓的步长。这个概念和Tensorflow等其他框架没什么区别,不再多言。
padding = 0
Pytorch与Tensorflow在卷积层实现上最大的差别就在于padding上。Padding即所谓的图像填充,后面的int型常数代表填充的多少(行数、列数),默认为0。需要注意的是这里的填充包括图像的上下左右,以padding = 1为例,若原始图像大小为32x32,那么padding后的图像大小就变成了34x34,而不是33x33。
dilation = 1
这个参数决定了是否采用空洞卷积,默认为1(不采用)。从中文上来讲,这个参数的意义从卷积核上的一个参数到另一个参数需要走过的距离,那当然默认是1了,毕竟不可能两个不同的参数占同一个地方吧(为0)。更形象和直观的图示可以观察Github上的Dilated convolution animations,展示了dilation=2的情况。
groups = 1
决定了是否采用分组卷积,groups参数可以参考groups参数详解
bias = True
即是否要添加偏置参数作为可学习参数的一个,默认为True。
padding_mode = ‘zeros’
即padding的模式,默认采用零填充。
Pytorch不同于Tensorflow的地方在于,Tensorflow提供的是padding的模式,比如same、valid,且不同模式对应了不同的输出图像尺寸计算公式。而Pytorch则需要手动输入padding的数量,当然,大多数情况下的kernel_size、padding左右两数均相同,且不采用空洞卷积(dilation默认为1),因此只需要记 O = (I - K + 2P)/ S +1这种在深度学习课程里学过的公式就好了。
4.3 案例:手写数字分类
导包
import torchvision
from torchvision.transforms import ToTensor
import torch
from torch import nn
import torch.nn.functional as F4.3.1 数据加载
#导入数据集
train_ds = torchvision.datasets.MNIST('dataset',
train=True,
transform=ToTensor(),
download=True)
test_ds = torchvision.datasets.MNIST('dataset',
train=False,
transform=ToTensor(),
download=True)
train_dl = torch.utils.data.DataLoader(train_ds,
batch_size=64,
shuffle=True)
test_dl = torch.utils.data.DataLoader(test_ds,
batch_size=64)在GPU上训练
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 在GPU上.训练只需两步:
# 1,将模型转移到GPU
# 2.将每一个批次的训练数据转移到GPU
# to 方法4.3.2 自定义模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 4 * 4, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
# x = x.view(-1, 16*4*4)
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x4.3.3 创建模型、损失函数和优化器
model = Net()
model.to(device) #放到GPU上
loss_fn = torch.nn.CrossEntropyLoss() #损失函数
opt = torch.optim.Adam(model.parameters(),lr=0.001) #优化器4.3.4 训练与测试
#训练函数
def train(train_dl,model,loss_fn,opt):
#累计所有批次的准确率,损失,累计累加样本数
total_acc, total_count, total_loss, = 0., 0, 0.
batch_num = len(train_dl)
#训练模式
model.train()
for x,y in train_dl:#dataload 是一个一个的批次的数据
x,y = x.to(device),y.to(device)
y_pred = model(x)
loss = loss_fn(y_pred,y)
opt.zero_grad()
loss.backward() # Backpropagation
opt.step()
with torch.no_grad(): #开启上下文管理器
total_acc += (y_pred.argmax(1) == y).type(torch.float).sum().item()
total_loss += loss.item() #item转成标量
total_count += y.size(0)
return total_loss/batch_num, total_acc/total_count
#注意:这里的损失是一个batch的损失#测试函数,模板 test不需要优化器
def test(test_dl,model,loss_fn):
#1. 获取当前数据集大小,累计所有批次的损失,累计累加预测正确的样本数
total_acc, total_count, total_loss, = 0., 0., 0.
batch_num = len(test_dl)
model.eval() #测试模式
# 测试函数不需要加入梯度跟踪
with torch.no_grad():
#上下文管理器,梯度不会跟踪
for x, y in test_dl: #dataload 是一个一个的批次的数据
x, y = x.to(device), y.to(device)
y_pred = model(x)
loss = loss_fn(y_pred,y) #批次的损失
total_loss += loss.item() #item转成标量
total_acc += (y_pred.argmax(1) == y).type(torch.float).sum().item() #计算正确率
total_count+=y.size(0)
#计算平均正确率和损失
return total_loss/batch_num, total_acc/total_count#调用训练函数和测试函数
def fit(epochs,train_dl,test_dl,model,loss_fn,opt):
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_loss,epoch_acc = train(train_dl,model,loss_fn,opt)
epoch_test_loss,epoch_test_acc = test(test_dl,model,loss_fn)
train_acc.append(epoch_acc)
train_loss.append(epoch_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 打印数据
template = ("epoch:{:2d}, train_Loss:{:.5f},train_Acc:{:.2f},test_Loss:{:.5f},test_Acc:{:.2f}")
print(template.format(epoch,epoch_loss,epoch_acc*100,epoch_test_loss,epoch_test_acc*100))
print('Done')
return train_loss, train_acc, test_loss, test_acc调用函数
train_loss, train_acc, test_loss, test_acc = fit(10,test_dl,test_dl,model,loss_fn,opt)训练输出
epoch: 0, train_Loss:0.77679,train_Acc:76.96,test_Loss:0.40579,test_Acc:87.94 epoch: 1, train_Loss:0.21806,train_Acc:93.26,test_Loss:0.20246,test_Acc:93.37 epoch: 2, train_Loss:0.13560,train_Acc:95.78,test_Loss:0.16307,test_Acc:94.74 epoch: 3, train_Loss:0.10075,train_Acc:96.66,test_Loss:0.12524,test_Acc:95.87 epoch: 4, train_Loss:0.07817,train_Acc:97.46,test_Loss:0.08356,test_Acc:97.14 epoch: 5, train_Loss:0.06031,train_Acc:98.09,test_Loss:0.07052,test_Acc:97.45 epoch: 6, train_Loss:0.04951,train_Acc:98.46,test_Loss:0.04557,test_Acc:98.40 epoch: 7, train_Loss:0.04025,train_Acc:98.81,test_Loss:0.03536,test_Acc:98.72 epoch: 8, train_Loss:0.03328,train_Acc:99.02,test_Loss:0.02869,test_Acc:99.02 epoch: 9, train_Loss:0.02743,train_Acc:99.17,test_Loss:0.02648,test_Acc:99.10 epoch:10, train_Loss:0.02233,train_Acc:99.34,test_Loss:0.02848,test_Acc:99.00 epoch:11, train_Loss:0.01910,train_Acc:99.50,test_Loss:0.02767,test_Acc:98.91 epoch:12, train_Loss:0.01681,train_Acc:99.56,test_Loss:0.01737,test_Acc:99.43 epoch:13, train_Loss:0.01414,train_Acc:99.60,test_Loss:0.01614,test_Acc:99.36 epoch:14, train_Loss:0.01112,train_Acc:99.71,test_Loss:0.01033,test_Acc:99.62 epoch:15, train_Loss:0.01628,train_Acc:99.48,test_Loss:0.01367,test_Acc:99.52 epoch:16, train_Loss:0.01053,train_Acc:99.70,test_Loss:0.00876,test_Acc:99.74 epoch:17, train_Loss:0.00634,train_Acc:99.85,test_Loss:0.00376,test_Acc:99.91 epoch:18, train_Loss:0.00364,train_Acc:99.93,test_Loss:0.00242,test_Acc:99.95 epoch:19, train_Loss:0.00657,train_Acc:99.83,test_Loss:0.09257,test_Acc:97.70 epoch:20, train_Loss:0.01714,train_Acc:99.50,test_Loss:0.00821,test_Acc:99.73 epoch:21, train_Loss:0.00564,train_Acc:99.82,test_Loss:0.00304,test_Acc:99.92 epoch:22, train_Loss:0.00285,train_Acc:99.94,test_Loss:0.00161,test_Acc:99.99 ... epoch:49, train_Loss:0.00002,train_Acc:100.00,test_Loss:0.00002,test_Acc:100.00 Done
4.4 结果可视化
import matplotlib.pyplot as plt
epochs = 50
plt.plot(range(epochs),train_loss,label="train_loss")
plt.plot(range(epochs),test_loss,label='test_loss')
plt.legend()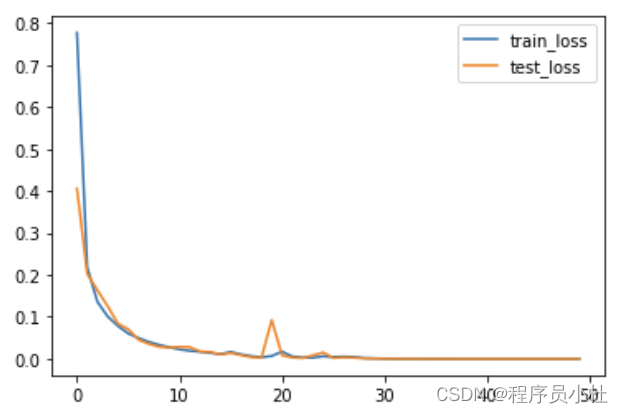
plt.plot(range(epochs),train_acc,label="train_acc")
plt.plot(range(epochs),test_acc,label='test_acc')
plt.legend()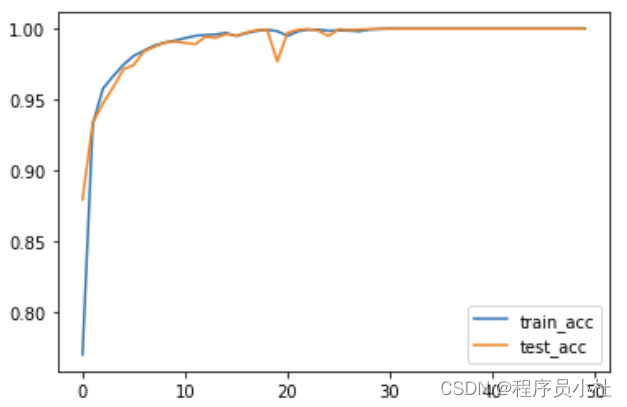

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









