






 本文介绍使用Python的requests库配合BeautifulSoup和lxml解析虎扑网站上的GIF图片及标题,并实现自动下载功能。
本文介绍使用Python的requests库配合BeautifulSoup和lxml解析虎扑网站上的GIF图片及标题,并实现自动下载功能。
工具:python3
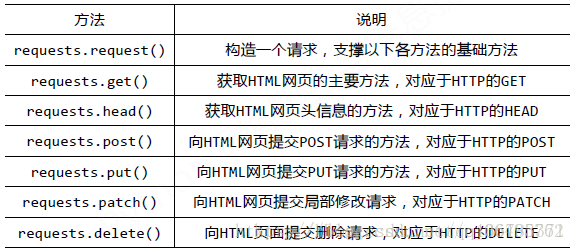
本文主要介绍requests第三方库,这个库可不是Python3内置的urllib.request库,而是一个强大的基于urllib3的第三方库。
实战虎扑gif封面
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
from urllib.request import urlretrieve
from lxml import etree
import os
import time
if __name__ == '__main__':
url = 'http://photo.hupu.com/tag/gif'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
req = requests.get(url = url,headers = headers)
req.encoding = 'gb2312'
html = req.text
html1=etree.HTML(html)
selector1=html1.xpath("//div[@class='piclist3']/table/tr/td/a/img/@src")
selector2=html1.xpath("//div[@class='piclist3']/table/tr/td/dl/dt/a/text()")
for se in range(0,len(selector1)):
print('标题:',selector2[se],' gif:',selector1[se])
filename = selector2[se] + '.'+selector1[se].split('.')[len(selector1[se].split('.'))-1]
print('下载:' + filename)
if 'images' not in os.listdir():
os.makedirs('images')
img_url='http:'+selector1[se]
urlretrieve(url =img_url ,filename = 'images/' + filename)
time.sleep(1)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









