







一、正则表达式
1、正则表达式基本知识
1、概念:正则表达式(Regular Expression,简称regex或regexp)是一种文本模式描述的工具,它使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。正则表达式的应用非常广泛,包括但不限于文本编辑器查找和替换、编程语言中的字符串处理、日志分析、数据验证等
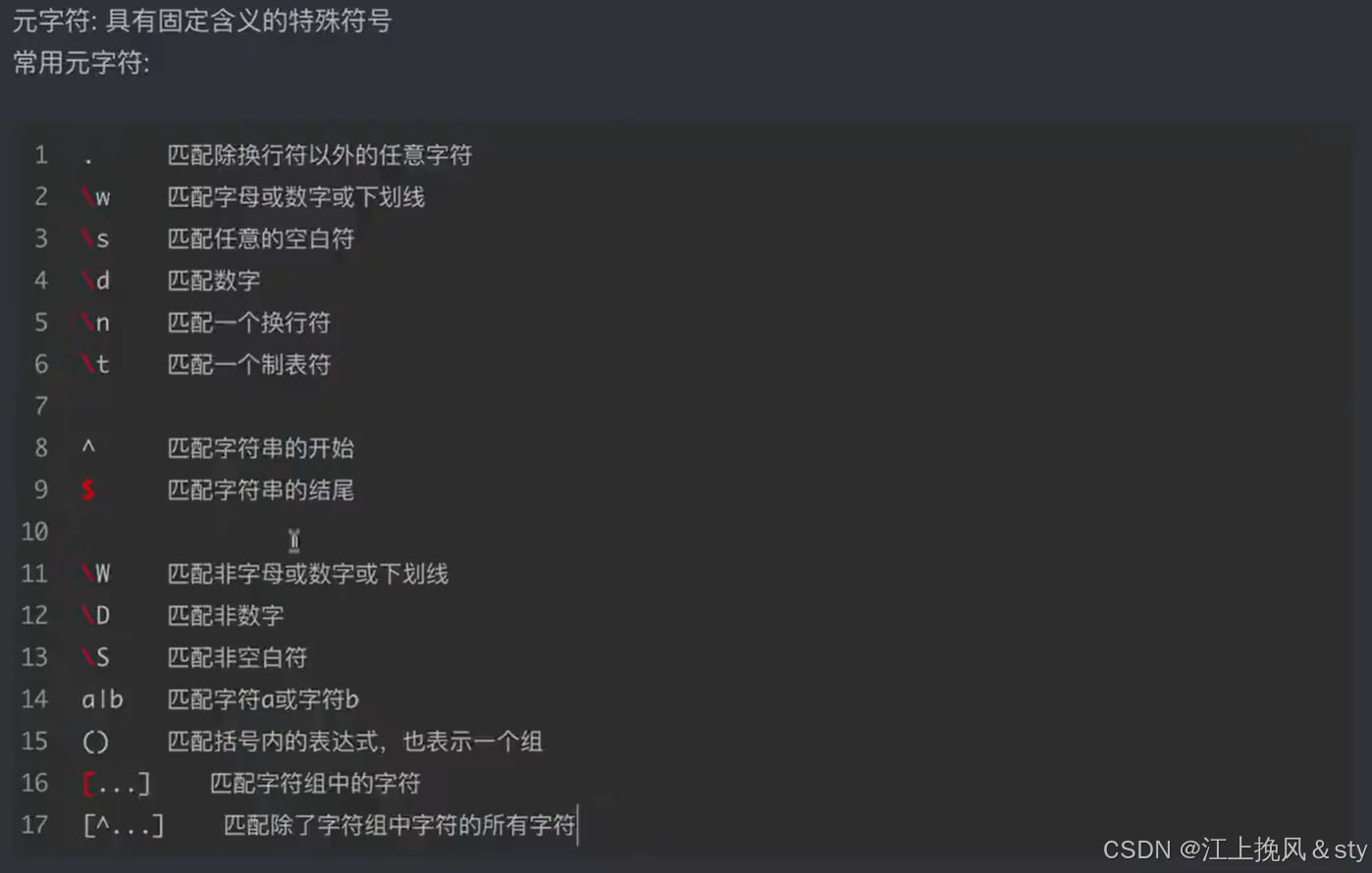
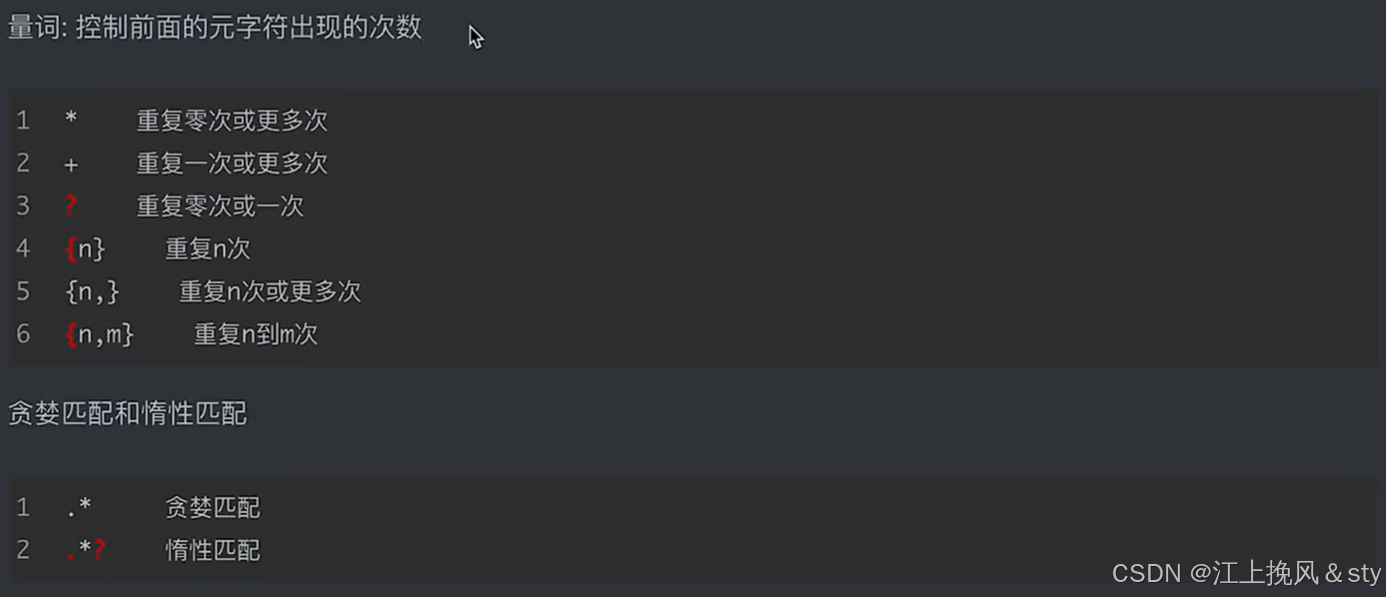
2、规则:
2、基于re的方法练习
2.1、re的基本方法(findall、finditer、match、search、compile)
import re
# findall是匹配字符串中所有符合正则的内容,正则表达式 \d+ 用于匹配一个或多个数字字符,并封装为一个list
ls = re.findall(r"\d+", "我的电话号码是:17385859669,我正在拨打10086")
# 在Python中,正则表达式前面添加r前缀表示这是一个原始字符串(raw string)。原始字符串的特点是,其中的反斜杠\不会被当作转义字符处理。
print(ls)
print("---------")
# finditer是匹配字符串中所有的内容,返回的是迭代器,从迭代器中拿到内容需要.group
iters = re.finditer(r"\d+", "我的电话号码是:17385859669,我正在拨打10086")
for i in iters:
#print(i)
# <re.Match object; span=(8, 19), match='17385859669'>
# <re.Match object; span=(25, 30), match='10086'>
print(i.group())
# 17385859669
# 10086
print("---------")
# search找到一个结果立即返回,返回的结果是match对象,拿数据同样需要.group
s = re.search(r"\d+", "我的电话号码是:17385859669,我正在拨打10086")
print(s)
print(s.group())
print("---------")
# match是从头开始进行匹配,返回的是match对象,拿数据也需要.group
# t = re.match(r"\d+", "我的电话号码是:17385859669,我正在拨打10086")
t = re.match(r"\d+", "17385859669,我正在拨打10086")
print(t)
print(t.group())
print("---------")
# 预加载正则表达式,提高工作效率,可以在多处使用,但是基本方法和前面的讲述一样
obj = re.compile(r"\d+")
ret = obj.finditer("我的电话号码是:17385859669,我正在拨打10086")
for i in ret:
print(i.group())
print("---------")
ret1 = obj.findall("20260601我一定会按时毕业的!!!")
print(ret1)
2.2、从re表达式中提取具体内容方式(爬虫重要的手段)
import re
s = """
<div class='a'><span id='1'>宋莹</span></div>
<div class='b'><span id='2'>黄玲</span></div>
<div class='c'><span id='3'>图南</span></div>
<div class='d'><span id='4'>栋哲</span></div>
<div class='e'><span id='5'>晓婷</span></div>
"""
#在正则表达式中继续提取具体内容,具体方式添加(?P<分组名称>正则)
obj = re.compile(r"<div class='(?P<classname>.*?)'><span id='(?P<id>\d+)'>(?P<name>.*?)</span></div>")
res = obj.finditer(s)
for it in res:
print(it.group("classname"))
print(it.group("id"))
print(it.group("name"))3、基于re的实践案例练习
3.1、爬取豆瓣电影top50电影数据
import requests,re
import csv
url = "https://movie.douban.com/top250"
header = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0"
}
resp = requests.get(url,headers=header)
# print(resp.text)
page_content = resp.text
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>'
r'.*?<p class="">.*?<br>(?P<year>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>.*?'
r'<span>(?P<num>.*?)人评价',re.S)
result = obj.finditer(page_content)
file = open("data.csv",mode="w",encoding="utf-8")
write = csv.writer(file)
for it in result:
# print(it.group("name"))
#strip() 是一个字符串方法,用于移除字符串开头和结尾的指定字符(默认为空白符,包括空格、换行符\n、制表符\t等)。这个方法不会改变原始字符串,而是返回一个新的字符串,该字符串已经去除了指定的前导和尾随字符。
# print(it.group("year").strip())
# print(it.group("score").strip())
# print(it.group("num").strip())
dic = it.groupdict()
dic['year'] = dic['year'].strip()
write.writerow(dic.values())
file.close()
print("write over")
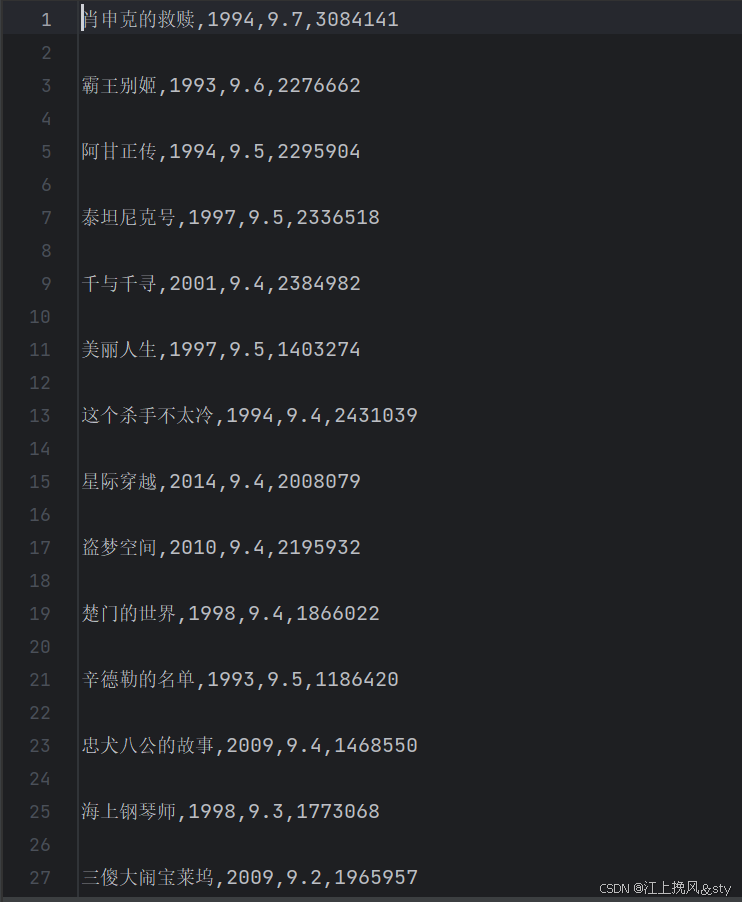
爬取数据后的结果展示:
3.2、爬取电影天堂的电影数据信息(恐怖片推荐里面的电影名称和下载链接保存到csv):
import requests,re,csv
domain = "https://www.dyttcn.com/"
header = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0"
}
resp = requests.get(domain, headers=header)
# resp = requests.get(url, verify=False) # 如果出现安全性错误,可以通过verify=False去掉安全验证
resp.encoding = "gb2312" # 指定字符编码集
# print(resp.text)
# 拿到ul里面的li
obj1 = re.compile(r"恐怖片推荐.*?<ul>(?P<ul>.*?)</ul>", re.S)
obj2 = re.compile(r"<a href='(?P<href>.*?)'", re.S)
obj3 = re.compile(r"◎片 名(?P<movie>.*?)</p>.*?<p>.*?◎IMDb链接 (?P<download>.*?)</p>", re.S)
result1 = obj1.finditer(resp.text)
child_href_list = []
file = open("movie.csv",mode="w",encoding="utf-8")
write = csv.writer(file)
for it1 in result1:
ul = it1.group('ul')
# print(ul)
# 提取子页面链接
result2 = obj2.finditer(ul)
for it2 in result2:
# 拼接子页面的url地址
child_href = domain + it2.group('href').strip("/")
child_href_list.append(child_href)
# 提取子页面内容
for href in child_href_list:
# print(href)#https://www.dyttcn.com/kongbupian/38907.html
child_resp = requests.get(href,headers=header)
child_resp.encoding = 'gb2312'
# print(child_resp.text)
# break # 测试用
# result3 = obj3.search(child_resp.text)
result3 = obj3.finditer(child_resp.text)
# print(result3.group("movie"))
for it3 in result3:
dic = it3.groupdict()
write.writerow(dic.values())
# print(it3.group('movie'))
# print(it3.group("download"))
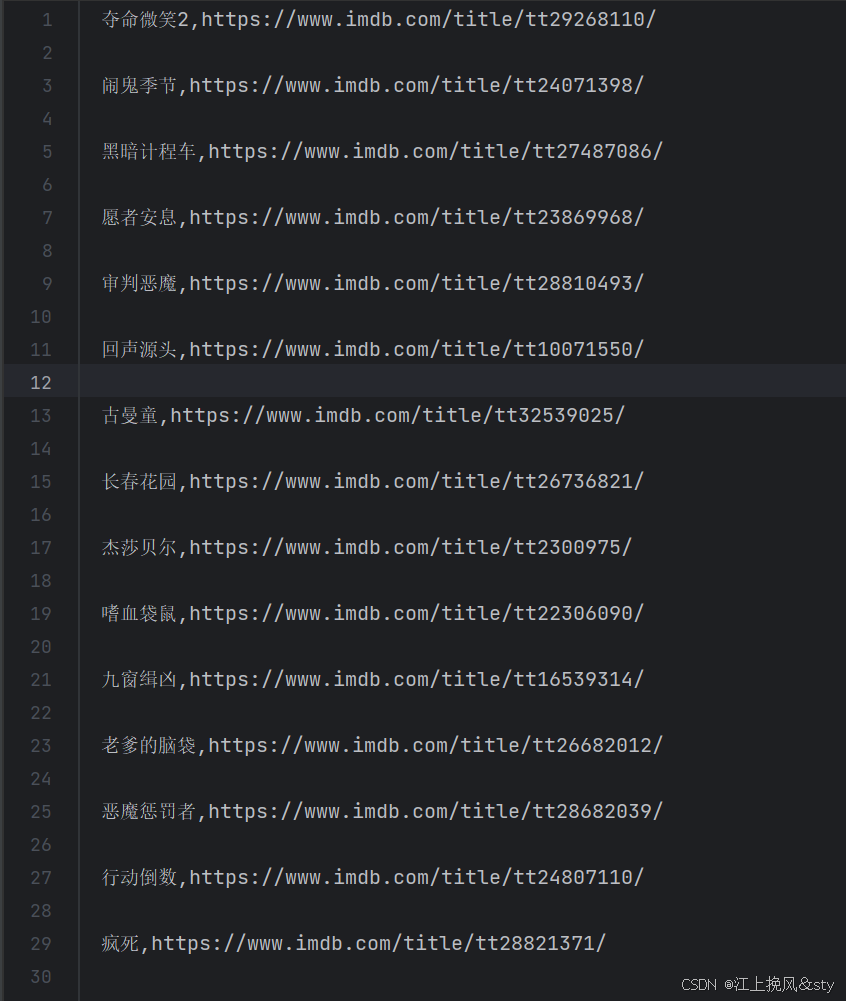
file.close()爬取数据后的结果展示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









