



前言
前面已经学习和了解了Pytorch框架,已经神经网络的结构概念,本次我们通过实战案例来学习如何编写神经网络代码,本次实战是基于Minist数据集来识别手写数字,手写数字识别也被称为神经网络学习的一个 “Hello World”项目,这个项目比较经典。
提示:如果没有学习过神经网络相关概念的,请看我前面文章。
一、什么是手写数字识别
手写数字识别的目的是通过给予模型一个输入手写的数字图像,模型通过学习过的数据集,得到的相关参数预测这个数字然后输出,本次涉及的学习数据集通过在线下载即可。
什么是数据集?从字面上理解当然是我们的学习需要的素材,其实就是如此,它可以是一大堆图像,也可以是一大堆历史数据。输入到神经网络模型,然后完成前向传播和反向传播,建立神经网络第一步就是加载数据集和预处理相关操作。我们把数据集分为:
- 训练集:用了训练的数据,一般占数据集的90%
- 测试集:用来测试的数据,一般占数据集的10%
二、如何实现数字识别
手写数字识别可以看成一个分类问题,首先看输出,一共有0~9种输出,也就是十维的数组,将输出转化为概率,也就是有十个概率,且加起来等于100%,通过对十个概率判断大小,概率最大的就是推理值。再看输入,由于本次使用的是全连接层,由于其特性,输入必须为1维向量,加入本次输入尺寸为 [1, 28, 28] (此处的1为维度,灰度图1维,28x28对应的尺寸),则需要将图像展开,展开方式见下图(每一列像素向下叠加)。
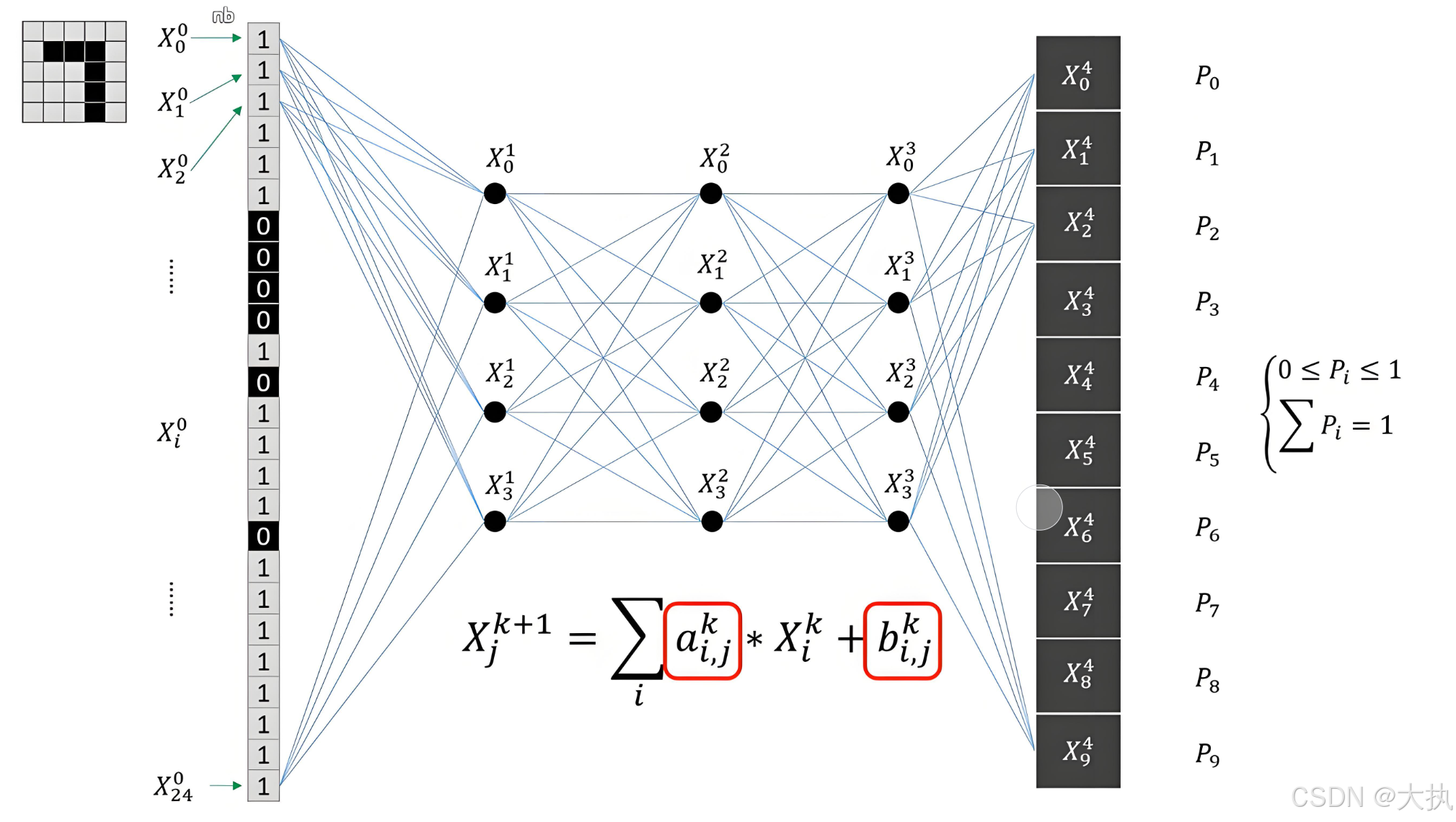
这样输入就变成了28x28=784x1的一维向量。对输入图像增加隐藏层配合参数给予不同的权重,再配合激活层函数,就得到了我们的模型。
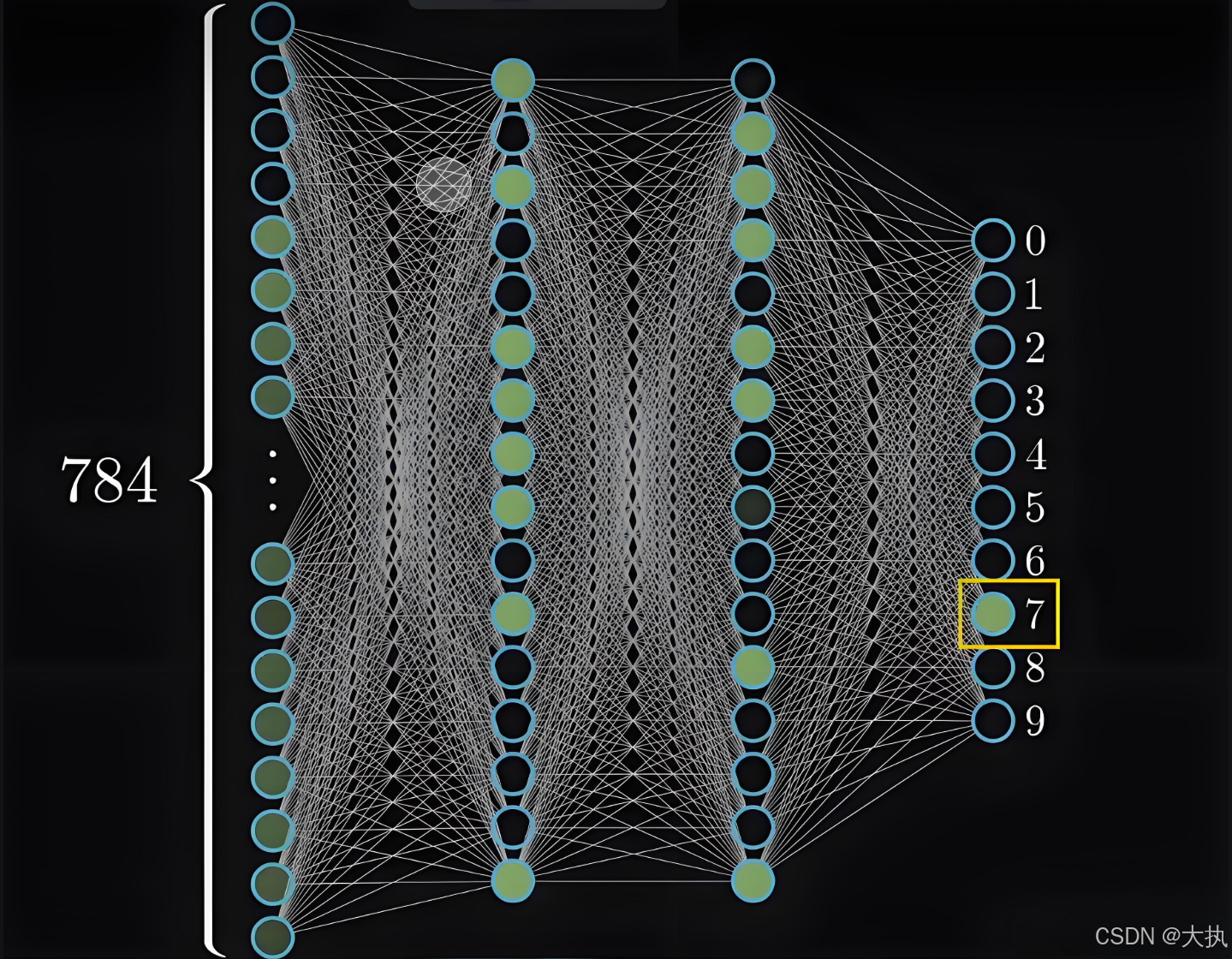
三、FC层模型
几乎所有的搭建网络流程都是统一的,通过pytorch框架,搭建流程如下:
- Dataset:导入数据集和预处理
- Network: 建立网络模型,定义前向传播函数
- Loss: 定义损失函数
- Train: 训练
- Test: 测试
- 保存模型
1. 导入数据和定义网络
import torch
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn
import torch.nn.functional as func
from torch import optim
import matplotlib.pyplot as plt
TestFlag = True
# data
_transform = transforms.ToTensor()
train_data = datasets.MNIST(root='./', download=True, train=True, transform=_transform)
test_data = datasets.MNIST(root='./', download=True, train=False, transform=_transform)
train_loader = DataLoader(dataset=train_data, batch_size=32, shuffle=True)
test_loader = DataLoader(dataset=test_data, batch_size=32, shuffle=True)
# net
class NewNet(nn.Module):
def __init__(self):
super(NewNet, self).__init__()
self.model = nn.Sequential(
nn.Linear(28 * 28, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 10)
)
def forward(self, x):
x = x.view(-1, 28*28)
x = self.model(x)
return func.log_softmax(x, dim=1)
如上代码通过datasets下载了训练集和测试集数据,再通过Dataloader将数据打包成多个batch, 这里的batch_size=32意为着每个批次里面有32个训练数据。然后在训练的时候对train_loader遍历,此时每个train_loader里面的元素尺寸应该是[32, 1, 28, 28], 32对应的是输入个数的维度。
定义网络后继承nn.Module,这里nn.Sequential 是 PyTorch 中的一个容器模块(container),用于按顺序组合多个神经网络层,添加的网络层按顺序执行,self.model接收一个输入,经过模型后输出,也就是在前向传播函数forward() 执行。由于本次模型用的全都是全连接层,所以连接层相对简单只有线性连接函数(nn.Linear),为了增加非线性,输出嵌套激活函数(nn.ReLU)。
nn.Sequential模块只是为了让模型写起来更方便,也可以用最原始的方式替换,如下:
self.model1 = nn.Linear(28*28, 64)
self.model2 = nn.ReLu()
前向传播函数需要嵌套输入输出,如下:
x = self.model1(x)
x = self.model2(x)
这种方法更加繁琐。
x.view():PyTorch 中调整张量形状的方法(类似于 NumPy 的 reshape)。
- -1:自动计算该维度的大小,确保总元素数不变。
- 28*28:将张量展平成 [batch_size, 784] 的形状(假设原始图像是 28x28 像素)。
2. Loss函数和优化函数
if __name__ == '__main__':
net = NewNet()
# loss
loss_func = nn.NLLLoss()
# optimization
optimization = optim.Adam(net.parameters(), 0.001)
# Initial yield
def calculate_test(test_data):
num_correct = 0
num_total = 0
with torch.no_grad():
for (image, label) in test_data:
outputs = net.forward(image)
for i, output in enumerate(outputs):
print(f"output: {torch.argmax(output)}")
if torch.argmax(output) == label[i]:
num_correct += 1
num_total += 1
return round((num_correct / num_total) * 100, 3)
实例化网络,定义损失函数,本次使用的损失函数nn.NLLLoss()(Negative Log Likelihood Loss,负对数似然损失)是 PyTorch 中用于分类任务的损失函数,通常与 LogSoftmax 或 nn.LogSoftmax() 结合使用。它直接对对数概率(log probabilities)进行计算,适用于多分类问题。
此处 calculate_test()函数是为了计算没有训练时候,计算前向传播,测试集的准确率应该是10%,也就是1/10分之一的概率会正确,是符合十个输出的。
3. 训练模型
加载训练集数据,训练模型,如下代码是将训练集数据重复5次训练,训练过程中计算LOSS,反向传播执行优化函数更新模型参数,可以看到每一个epoch,准确率会逐渐变高,训练完后保存模型。
# 3. 训练网络
def train_and_save():
loss_func = nn.NLLLoss()
_model = NetWork() if not CNN_NETWORK else CNN()
train_loader, _ = download_mnist()
epochs = 5
for epoch in range(epochs):
total_number = 0
ture_number = 0
for batch, (images, labels) in enumerate(train_loader):
_model.zero_grad()
out_puts = _model(images)
loss = loss_func(out_puts, labels)
loss.backward()
optimization = optim.Adam(_model.parameters(), 0.001)
optimization.step()
# 统计良率
for index, output in enumerate(out_puts):
if torch.argmax(output).item() == labels[index]:
ture_number += 1
total_number += 1
print(f"epoch{(epoch + 1)}/{epochs}: {round(ture_number / total_number * 100, 3)}%")
torch.save(_model.state_dict(), 'mnist.pth')
return _model
四、卷积层模型
我们还可以在代码里面定义多个模型,比如定一个卷积层神经网络(CNN),添加到代码中,比较准确率,项目代码如下。
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from matplotlib.widgets import Button, Slider
from PIL import Image
import cv2
import os
CNN_NETWORK = True
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"当前设备: {device}")
_transform = transforms.Compose([
transforms.Grayscale(),
transforms.ToTensor(),
transforms.Resize((28, 28)),
transforms.Lambda(lambda x: (x > 0.7).float()),
transforms.Normalize((0.1307,), (0.3081,))
]) # 预处理器
# 1. 下载数据
def download_mnist():
train_data = datasets.MNIST(root='./', download=True, train=True, transform=_transform)
test_data = datasets.MNIST(root='./', download=True, train=False, transform=_transform)
train_loader = DataLoader(dataset=train_data, batch_size=32, shuffle=True)
test_loader = DataLoader(dataset=test_data, batch_size=32, shuffle=True)
return train_loader, test_loader
# 2. 定义神经网络模型
class NetWork(nn.Module):
def __init__(self):
super(NetWork, self).__init__()
self.model = nn.Sequential(
nn.Linear(28 * 28, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 10),
nn.LogSoftmax(dim=1)
)
def forward(self, x):
x = x.view(-1, 28 * 28)
return self.model(x)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1, 32, 3, 1, 1), # 输入1通道,输出32通道,3x3卷积核,padding=1
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2)) # 池化层 2x2
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, 3, 1, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc = nn.Sequential(
nn.Linear(64 * 7 * 7, 128), # 两次池化后28x28→14x14→7x7
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(128, 10),
nn.LogSoftmax(dim=1))
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # 展平多维卷积特征图
x = self.fc(x)
return x
# 3. 训练网络
def train_and_save():
loss_func = nn.NLLLoss()
_model = NetWork() if not CNN_NETWORK else CNN()
train_loader, _ = download_mnist()
epochs = 5
for epoch in range(epochs):
total_number = 0
ture_number = 0
for batch, (images, labels) in enumerate(train_loader):
_model.zero_grad()
out_puts = _model(images)
loss = loss_func(out_puts, labels)
loss.backward()
optimization = optim.Adam(_model.parameters(), 0.001)
optimization.step()
# 统计良率
for index, output in enumerate(out_puts):
if torch.argmax(output).item() == labels[index]:
ture_number += 1
total_number += 1
print(f"epoch{(epoch + 1)}/{epochs}: {round(ture_number / total_number * 100, 3)}%")
torch.save(_model.state_dict(), 'mnist.pth')
return _model
# 4. 模型加载函数
def load_saved_model():
print("Loading pre-trained model...")
_model = NetWork() if not CNN_NETWORK else CNN()
if os.path.exists('mnist.pth'):
_model.load_state_dict(torch.load('mnist.pth', weights_only=True))
_model.eval()
print("Model loaded successfully!")
return _model
else:
print("No saved model found. Training new model...")
return train_and_save()
# 5. 测试模型精度
def test_model(model):
total_number = 0
ture_number = 0
_, test_loader = download_mnist()
for _, (images, labels) in enumerate(test_loader):
outputs = model(images)
for index, _ouput in enumerate(outputs):
result = torch.argmax(_ouput).item()
label = labels[index]
ture_number = ture_number + 1 if result == label else ture_number
total_number += 1
print(f"Yield: {round(ture_number / total_number * 100, 3)}%")
# 6. 测试自定义的图片
def test_img(img_path):
img = Image.open(img_path)
img = _transform(img)
print("img shape: ", img.shape)
img = img.expand(1, -1, -1, -1)
print("img shape: ", img.shape)
_model = load_saved_model()
outputs = _model(img)
output = outputs[0]
result = torch.argmax(output).item()
print(f"Image result: {result}")
if __name__ == '__main__':
download_mnist()
model = load_saved_model()
test_model(model)
test_img("handwritten_digit.png")
五、 执行结果
通过训练和加载模型,测试良率和识别图片结果如下:
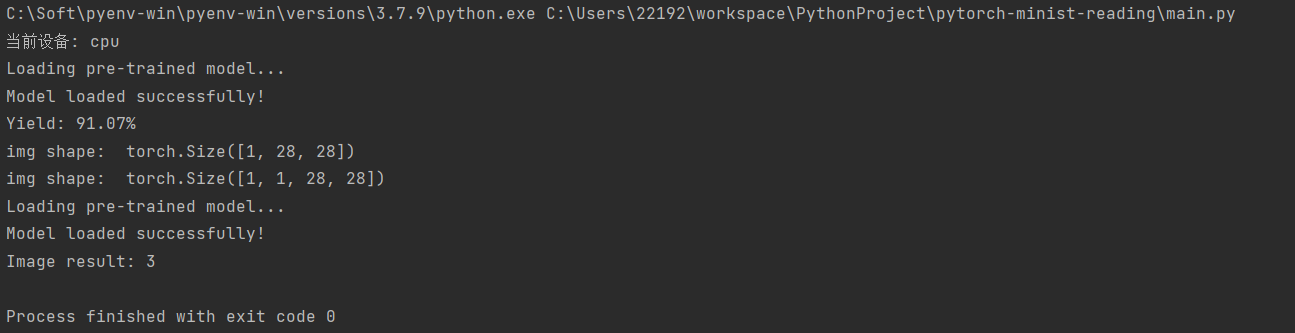
进一步创建画图面板,通过加载训练模型,实时识别手写数字,执行如下:
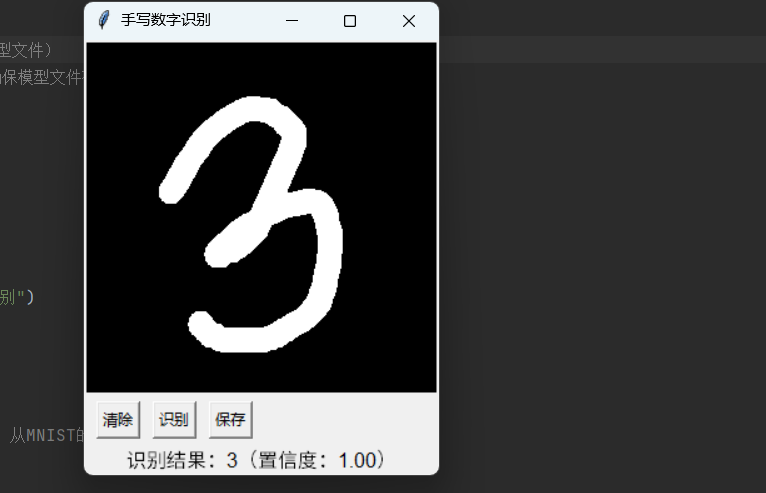
总结
以上为训练Mnist数据集,然后识别面板的数字流程,为了更好的准确率需要更多的投入,本次准确率只是一个演示作用,为了更好的进行下一步学习,应该多了解神经网络数据的结构,以及各个方法的计算目的。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









