



文章目录
前言
提示:本篇分享卷积神经网络结构以及在Pytorch里面的用法
前面在作者的神经网络概念篇提到了神经网络的结构,层的概念,一般简单的人工网络我们说隐藏层只有一层,而且是简单的线性全连接层(FC层)。但是针对复杂一点的网络,比如输入是图像,做图像识别,图像分类,需要进行图像特征提取,我们就要用的卷积层,接下来我们开始学习卷积神经网络。
一、卷积神经网络是什么?
卷积神经网络(CNN)是一种深度学习模型,主要用于处理具有网格结构的数据,如图像、视频和音频。CNN 的核心思想是通过卷积操作提取局部特征,另一句话说就是,以卷积层为主的神经网络就是卷积神经网络,记下来只要学习神经网络里的卷积层结构和其他辅助层(池化层,激活层,FC层)就行了。
二、认识卷积神经网络
卷积神经网络(CNN)包含一些常见的网络层结构,他们在整个模型中扮演不同的角色。
1. 卷积层作用
卷积层的作用是提取图像特征,它的数学运算是定义一个卷积核(滤波矩阵)和图像做内积(对应元素相乘再相加)。卷积核是在图像上滑动的,通过定义参数,卷积核在图像上滑动一个步长,和图像做内积,最后一个卷积核就得到一个新的特征图。
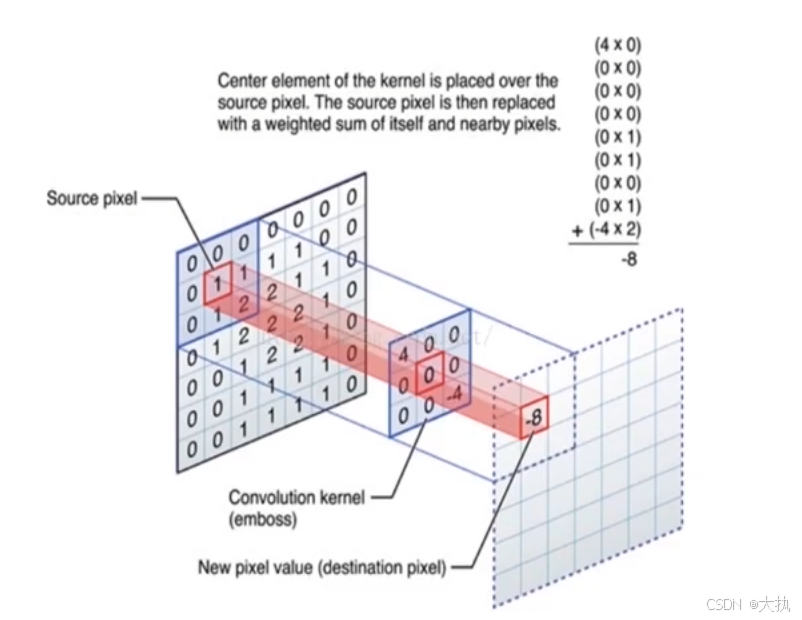
如上图,定义了一个3 x 3的卷积核,输入图像是单通道的7 x 7 图像, 卷积核在输入图像从左向右滑动1格(假如此时定义的滑动参数是1),通过内积运算就会得到一个新的数,填充到特征图上。按顺序滑动就会得到5 x 5的新的特征图,此时的特征图就记录了输入图像的某一个特征(比如是横向的一横),通过多个卷积核(比如32个)就会得到输入图像的多个特征。这就是卷积层的运行流程。
注意:卷积层得到的原始图像都是局部的特征,比较适合一些图像的分类,识别的场景。
2. Pytorch卷积层函数
在pytorch里面的卷积层函数是 nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias)
| 参数名 | 含义 | 示例值或选项 |
|---|---|---|
in_channels | 输入数据的通道数 | - 对于 RGB 图像,in_channels=3- 对于灰度图像, in_channels=1 |
out_channels | 卷积核的数量,输出特征图的通道数 | out_channels=32 表示使用 32 个卷积核,生成 32 个特征图 |
kernel_size | 卷积核的高度和宽度 | - kernel_size=3 表示 3×3 的卷积核- kernel_size=(5, 5) 表示 5×5 的卷积核 |
stride | 卷积核在输入数据上滑动的步长 | - stride=1 表示每次滑动 1 个像素- stride=2 表示每次滑动 2 个像素 |
padding | 在输入数据的边缘填充 0 的数量 | - padding=1 表示在每一边填充 1 行/列的 0- padding=(1, 2) 表示高度方向填充 1 行,宽度方向填充 2 列 |
padding_mode | 填充的方式 | - 'zeros':用 0 填充(默认)- 'reflect':镜像填充- 'replicate':复制边缘值- 'circular':循环填充 |
dilation | 卷积核中元素之间的间距 | - dilation=1 表示普通卷积- dilation=2 表示卷积核的元素之间间隔 1 个像素 |
groups | 将输入通道和输出通道分组,每组单独卷积 | - groups=1 表示普通卷积(默认)- groups=in_channels 表示深度可分离卷积 |
bias | 是否在卷积操作中添加偏置项 | - bias=True 表示添加偏置(默认)- bias=False 表示不添加偏置 |
解释下
padding参数:如上面图所示,padding参数是1,所以扩充了一行一列0向量。为什么扩充呢,假如没有扩充,那边缘图像的特征就会丢失了,假如输入图像的边缘有特征信息,就应该扩充padding,反之就不用。对于dilation参数:就是对卷积核膨胀,扩充卷积核的感受野(神经网络看到的图像区域,多层卷积层最后的卷积核对原图的感受野会逐步增加),增加卷积核的感受范围。
3. 卷积层的参数量和计算量
参数量(Parameters)和计算量(FLOPs)是为了体现当前模型卷积层的复杂层度,也是对当前模型,需要的算力的评价。这在实际的交流中是有一定的意义的,可以体现模型的负杂性质。计算公式如下。
参数量: 在卷积神经网络中参数,卷积层占有主要的参数,这里的参数也就是卷积核矩阵(卷积核权重)加上偏置,卷积核权重是初始化的一个 3 x 3或 5 x 5的小矩阵, 通过反向传播的方式按梯度下降的方式被更新。

计算量: 计算量体现着卷积神经网络模型的复杂程度。

4. 池化层(Pooling)
池化层(Pooling Layer) 是卷积神经网络(CNN)中的重要组成部分,主要用于降维和特征提取。它的核心作用是通过对输入特征图进行下采样,减少数据的空间尺寸(高度和宽度),从而降低计算量,同时增强模型的鲁棒性。池化层的操作如下(图中显示的是平均池化层):对某个参数单位(2)在特征图上滑动,在此单位矩阵上取平均或最大值,得到新的矩阵,从而达到降维的目的。
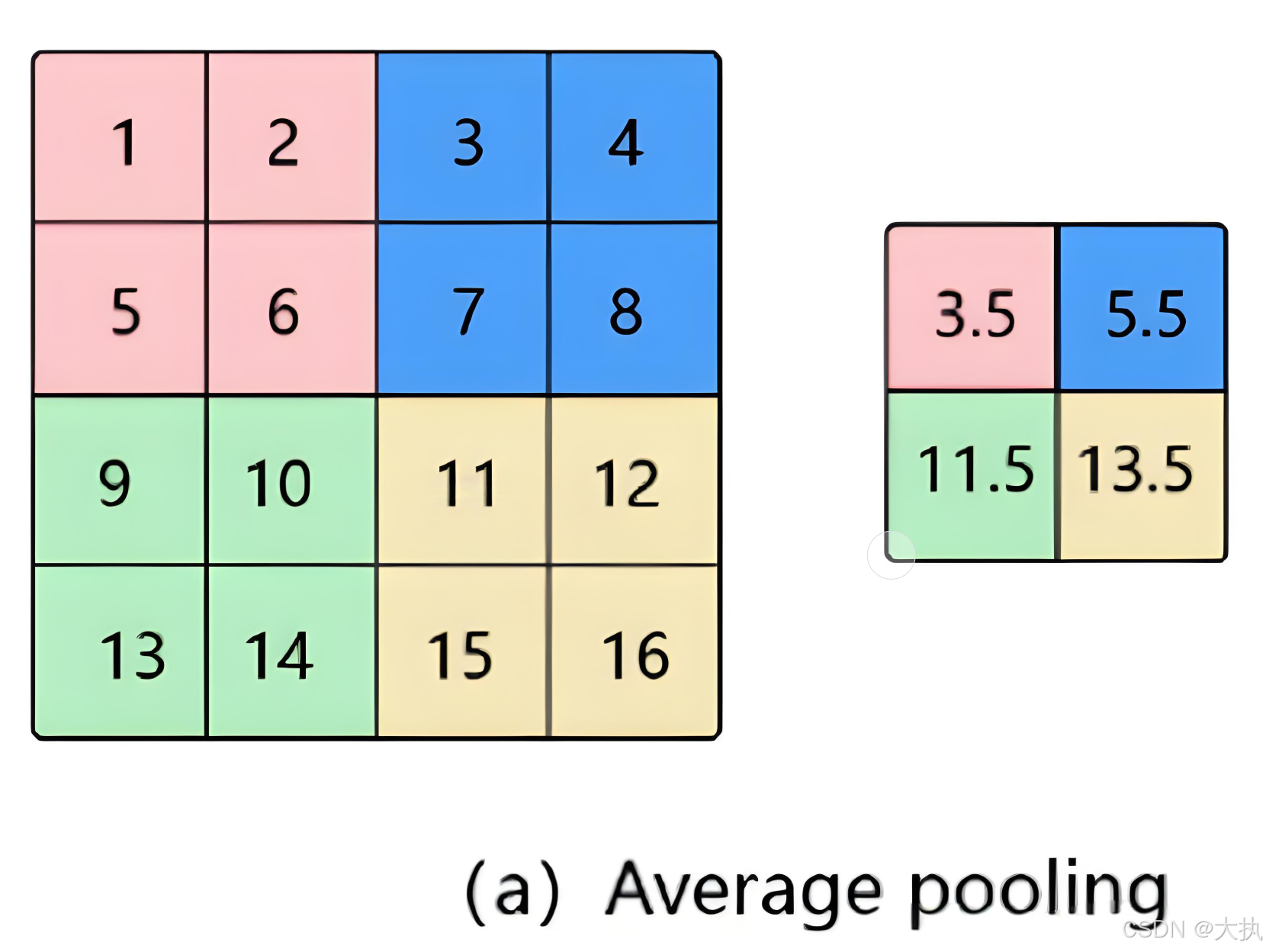
池化层带来的功能主要是:
- 降维,降低特征图的尺寸,降低计算复杂度。
- 防止过拟合。
- 提取主要特征,是的模型对输入变化更加鲁棒。
4.1 最大池化层(Max Pooling)
最大池化层的操作是对单位矩阵取最大值,它的好处是最大的保留原图的显著特征。在pytorch里面调用 torch.nn.MaxPool2d
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
参数说明:
-
kernel_size(int 或 tuple):池化窗口的大小。可以是单个整数(表示正方形窗口)或元组(如(2, 2))。
-
stride(int 或 tuple,可选):池化窗口的步长。默认值为kernel_size。
-
padding(int 或 tuple,可选):输入数据的边缘填充大小。默认值为0。
-
dilation(int 或 tuple,可选):控制窗口内元素的间距。默认值为1。
-
return_indices(bool,可选):是否返回最大值的位置索引。默认值为False。
-
ceil_mode(bool,可选):如果为True,则使用向上取整计算输出尺寸;否则使用向下取整。默认值为False。
4.2 平均池化层(Mean Pooling)
平均池化层的操作是对单位矩阵取平均值,它的好处是最大保留原图的整体信息。在pytorch里面调用 torch.nn.AvgPool2d
torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None)
参数说明:
-
kernel_size(int 或 tuple):池化窗口的大小。可以是单个整数(表示正方形窗口)或元组(如(2, 2))。
-
stride(int 或 tuple,可选):池化窗口的步长。默认值为kernel_size。
-
padding(int 或 tuple,可选):输入数据的边缘填充大小。默认值为0。
-
ceil_mode(bool,可选):如果为True,则使用向上取整计算输出尺寸;否则使用向下取整。默认值为False。
-
count_include_pad(bool,可选):如果为True,则在计算平均值时包括填充值;否则不包括。默认值为True。
-
divisor_override(int,可选):如果指定,则使用该值作为除数,而不是窗口内元素的数量。
ceil_mode: 在池化操作中,输入特征图的尺寸可能无法被步长整除,ceil_mode为False, 则忽视这部分,True则保留边缘区域。
5. 上采样层(Upsampling Layer)
上采样层(Upsampling Layer)是卷积神经网络(CNN)中用于增大特征图空间尺寸(如高度和宽度)的层,常见于图像分割(如U-Net)、超分辨率、生成对抗网络(GAN)等任务。其核心目的是恢复或扩展低分辨率特征图的细节信息,以下是实现方法。
5.1 插值上采样
插值上采样是基于算法将特征图放大(resize), 无学习参数,由于插值上采样简单,不会带来复杂的参数和计算量,相对使用较多。
- 最近领插值:复制相邻像素值,速度快,但是锯齿明显
- 双线性插值:线性加权平均,平滑但是模糊细节
- 双三次插值:高阶插值,效果更加平滑,计算稍大
在pytorch中,插值上采样通过torch.nn.functional.interpolate()方法实现。
import torch.nn.functional as F
# 输入张量 (batch_size, channels, height, width)
output = F.interpolate(
input,
size=None, # 目标尺寸 (h, w),或单个标量(等比缩放)
scale_factor=None, # 缩放倍数(如2.0表示放大2倍)
mode='nearest', # 插值模式:'nearest', 'bilinear', 'bicubic', 'area'
align_corners=None # 对齐像素中心(对双线性/双三次重要)
)
5.2 转置卷积(反卷积)
转置卷积层(Transposed Convolution Layer),是卷积神经网络中用于上采样的核心操作之一。它通过可学习的参数将低分辨率特征图放大到高分辨率,广泛应用于图像分割(如U-Net)、生成对抗网络(GAN)、超分辨率等任务。
转置卷积是普通卷积的“逆向过程”,通过插入零值(或插值)扩展输入尺寸,再执行常规卷积运算,实现尺寸放大,所以,反卷积函数参数和卷积参数很像,并且会有卷积参数。
import torch.nn as nn
trans_conv = nn.ConvTranspose2d(
in_channels=64, # 输入通道数, 前置输出特征图个数
out_channels=32, # 输出通道数
kernel_size=4, # 卷积核大小(如3, 4, 5)
stride=2, # 步长(通常≥1)
padding=1, # 输入填充(控制输出尺寸)
output_padding=0, # 额外填充调整尺寸
bias=True # 是否使用偏置项
)
输出尺寸 = (输入尺寸−1)×stride+kernel_size−2×padding+output_padding
6. 激活层
在卷积神经网络也需要激活层,带入激活层是为了提升模型的非线性能力,卷积层从理论上是线性的(内积运算),所以有必要增强网络的非线性能力。
如下为常见的激活函数图:
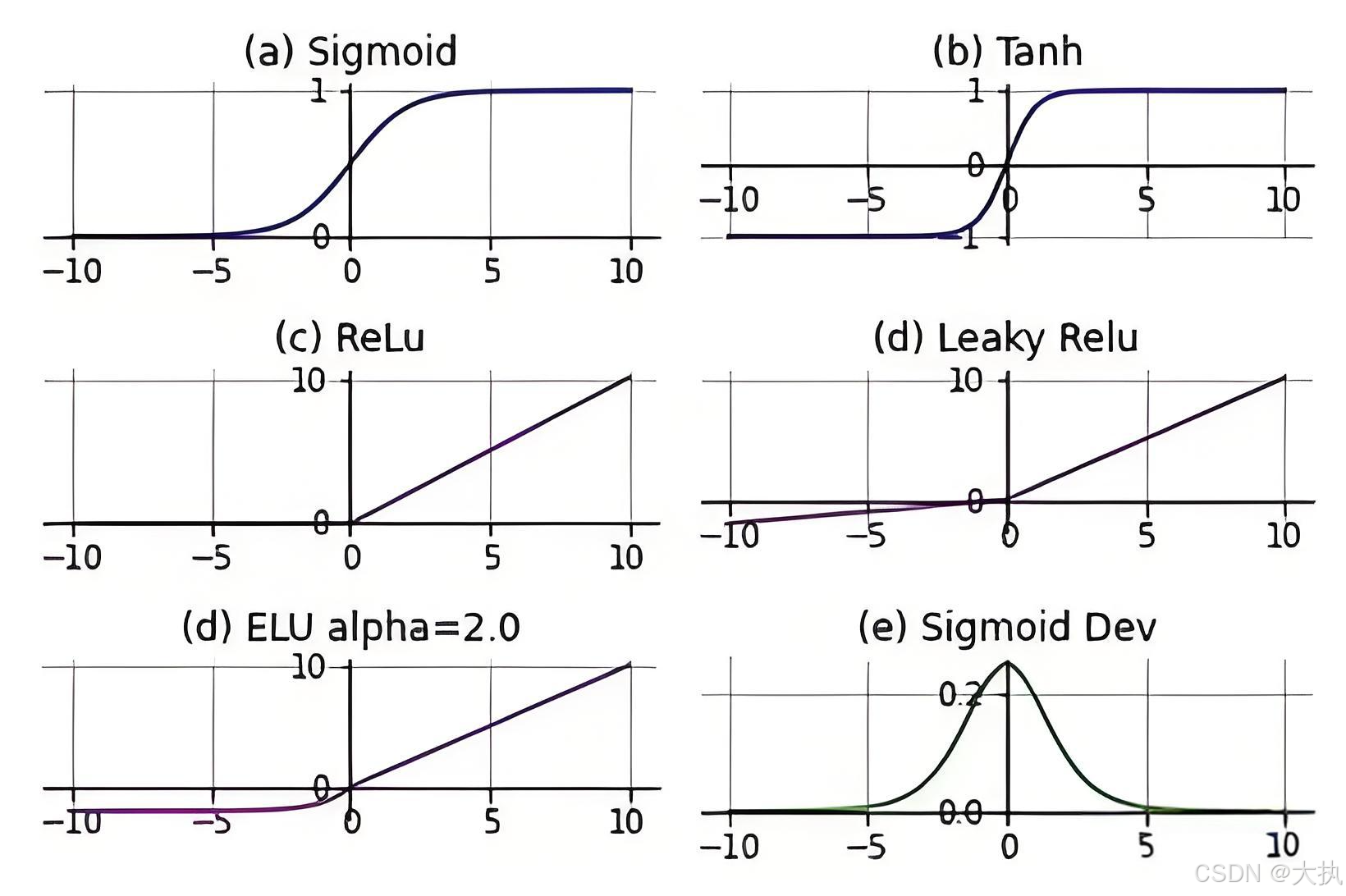
import torch.nn.functional as F
# ReLU
output = F.relu(input)
# LeakyReLU (需指定negative_slope,如0.01)
output = F.leaky_relu(input, negative_slope=0.01)
# Sigmoid
output = F.sigmoid(input)
# Tanh
output = F.tanh(input)
# Softmax (需指定dim,通常dim=1对通道维度归一化)
output = F.softmax(input, dim=1)
# GELU (高斯误差线性单元)
output = F.gelu(input)
7. Batch Normalization(BN)层
BN层是一种归一化操作,假如现在的特征图矩阵信息有太分散,可以通过BN层进行归一化操作,它的作用是加速训练并提升模型稳定性。
它的计算方式如下:
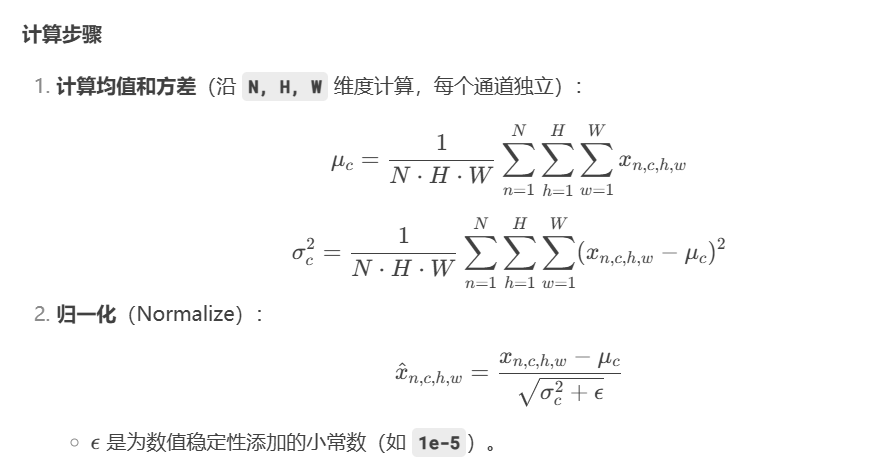
注意: 计算均值和方差都是各个维度(例如 BGR 或多个特征图之间)独立的,各个维度的均值和方差计算出来后,进行归一化计算公式,这就意味着输入的维度和输出维度是一样的(包括特征图尺寸)。
输入信息如下:

计算的 x (n, c, h, w) 就会替代原始的值,达到图像归一化的作用,在此之后再增加缩放和平移操纵,用于增加线性关系,用于恢复数据的表达能力,计算公式如下 (y 和 B 为训练参数,通过反向传播被更新):
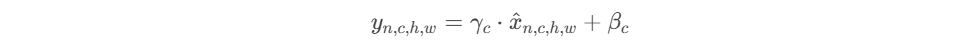
在Pytorch里面的实现方式如下:
import torch
import torch.nn as nn
# 定义 BN 层(以 2D 卷积为例)
batch_norm = nn.BatchNorm2d(
num_features=64, # 输入通道数 C
eps=1e-5, # ϵ
momentum=0.1, # EMA 的动量
affine=True # 是否学习 γ 和 β
)
说明:
- 为什么引入y, b 参数进行缩放平移:
归一化操作会破坏原始数据分布(线性能力被削弱),y 和 B 参数允许网络学习恢复最优的分布。- BN对Batch Size敏感:
Batch Size 不宜太小(如1, 2),可能导致性能下降。
momentum参数用于控制全局统计量的更新方式,通过指数移动平均实现,对应的均值和方差的更新如下:
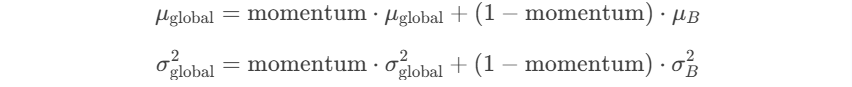
参数值越大,全局统计量更新越缓慢,训练更稳定,对近期的batch变化不敏感。
参数值越小,全局统计量更新越快,更依赖当前batch,适合数据分布动态变化的场景(如小Batch训练)。
8. Dropout层(丢弃层)
Dropout是神经网络中一种常用的正则化技术,根据某个概率 p (通常设置为0.2-0.5之间), 将输入元素随机置0,Dropout层的输出维度与输入维度完全相同。Dropout只是随机将输入张量中的某些元素置为0(按照设定的丢弃率 p),而不会改变张量的形状(shape)。
以下为Dropout层的作用:
- 防止过拟合,防止训练过程中模型太依赖数据。
- 增强泛化能力,使得网络学习更鲁棒。
注意: Dropout常常和FC层结合使用,因为FC层将会有大量的学习参数,为了减少计算复杂度,常常使用Dropout。Dropout 通常不会出现在输出层,常常分布在输入层和隐藏层。
在Pytorch中Dropout网络按如下方式实现:
import torch
import torch.nn as nn
dropout = nn.Dropout(p=0.5) # 定义Dropout层
三、经典卷积神经网络
1. 卷积神经网络结构
经过多个世纪的迭代,已经积累了多个经典卷积神经网络,
| 网络名称 | 提出年份 | 主要贡献 | 输入尺寸 | 层结构组成 | 参数量 | 特点 |
|---|---|---|---|---|---|---|
| LeNet-5 | 1998 | 首个成功CNN | 32×32×1 | 输入 → Conv1 (6@28×28) → Pool1 → Conv2 (16@10×10) → Pool2 → FC1 (120) → FC2 (84) → 输出 | ~60K | 手写数字识别,平均池化 |
| AlexNet | 2012 | ImageNet夺冠 | 227×227×3 | 输入 → Conv1 (96@55×55) → Pool1 → Conv2 (256@27×27) → Pool2 → Conv3-5 (384,384,256) → FC1-2 (4096) → 输出 | ~60M | ReLU激活,Dropout,数据增强 |
| VGG-16 | 2014 | 小卷积核堆叠 | 224×224×3 | 输入 → 2×(Conv64) → Pool → 2×(Conv128) → Pool → 3×(Conv256) → Pool → 3×(Conv512) → Pool → 3×(Conv512) → Pool → FC(4096×2) → 输出 | ~138M | 全部使用3×3卷积,深度增加 |
| GoogLeNet | 2014 | Inception模块 | 224×224×3 | 输入 → Conv → Pool → Conv → Inception×9 → AvgPool → Dropout → 输出 | ~5M | 1×1卷积降维,并行结构 |
| ResNet-50 | 2015 | 残差连接 | 224×224×3 | 输入 → Conv1 → MaxPool → Conv2_x (×3) → Conv3_x (×4) → Conv4_x (×6) → Conv5_x (×3) → AvgPool → 输出 | ~25M | 跳跃连接,解决梯度消失 |
| MobileNetV1 | 2017 | 轻量级设计 | 224×224×3 | 输入 → Conv → DepthwiseConv×13 → AvgPool → FC → 输出 | ~4.2M | 深度可分离卷积,α宽度因子 |
| EfficientNet-B0 | 2019 | 复合缩放 | 224×224×3 | MBConv模块×7 (带SE注意力) → Conv → Pool → FC | ~5.3M | 统一缩放深度/宽度/分辨率 |
2. 关键符号说明
- Conv:卷积层(数字表示通道数,如Conv64表示64个滤波器)
- Pool:池化层(默认2×2,步长2)
- FC:全连接层
- @:特征图尺寸(如96@55×55表示96个55×55的特征图)
- ×N:重复N次的模块
- MBConv:Mobile Inverted Bottleneck模块
- SE:Squeeze-and-Excitation注意力模块
总结
总的来说CNN是以特征提取为主,也就是以卷积层为主的神经网络,CNN通过其强大的特征提取能力,已成为计算机视觉领域的基石技术,并不断与其他深度学习技术融合创新。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









