






前言
本文提出了一种大模型模态扩展方法,核心优势在于:几乎不降低原本模态的性能、只增加少量新参数
论文标题
Exploiting Mixture-of-Experts Redundancy Unlocks Multimodal Generative Abilities
论文地址
https://arxiv.org/pdf/2503.22517
作者背景
爱丁堡大学,帝国理工学院,华为诺亚方舟实验室,微软研究院
动机
LLMs在文本模态上展现出了卓越性能,将其扩展到多模态生成领域是当下一个研究的热点,但现有方法主要存在两方面缺陷:
- 在多模态微调过程中,原本的文本生成能力往往会显著退化。
- 为适应新模态而添加专门的模块(如新的视觉专家),导致模型参数规模迅速膨胀,提高了计算与部署成本。
对此,研究者迫切需要一种方法,在不影响原有语言能力的情况下,实现高效多模态扩展。
解决方案
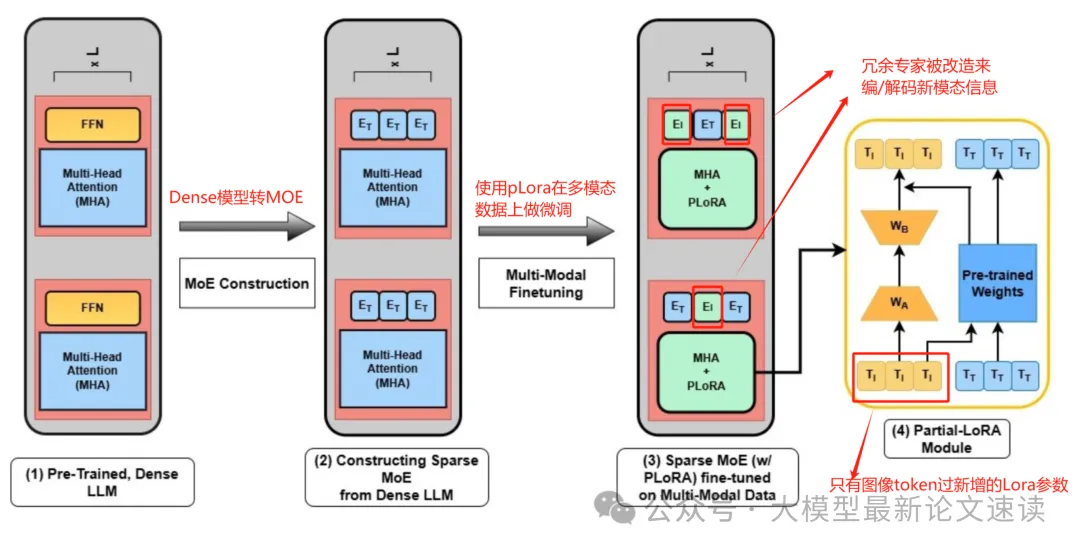
一、利用MoE中的专家冗余
“专家冗余”指的是,在MOE架构大模型中,存在多个专家执行类似功能。这是一个常见的现象,有很多模型压缩工作便旨在丢弃冗余专家以降低计算成本。当然,也有一些工作反过来复制高负载专家主动构造这种冗余,(DeepSeek-V3的EPLB算法),不过这是为了解决分布式训练时的GPU负载均衡问题,是另一个话题
作者首先把一个密集语言模型(LLaMA)的FFN层做非重叠的随机切分,转化成为MOE结构(参考之前的一个LLaMA转MOE的工作:https://github.com/pjlab-sys4nlp/llama-moe),此时模型便出现了上述专家冗余性(注:这里的冗余并非是凭空产生的,而是大模型固有的参数空间冗余的显现),这些冗余可以更好地利用于新模态信息的学习,因为可以轻松地隔离不同类型的知识
二、多模态微调&部分低秩适配
使用多模态数据进行微调时,使用标准的VAE模型,图像token化后与文本并列输入
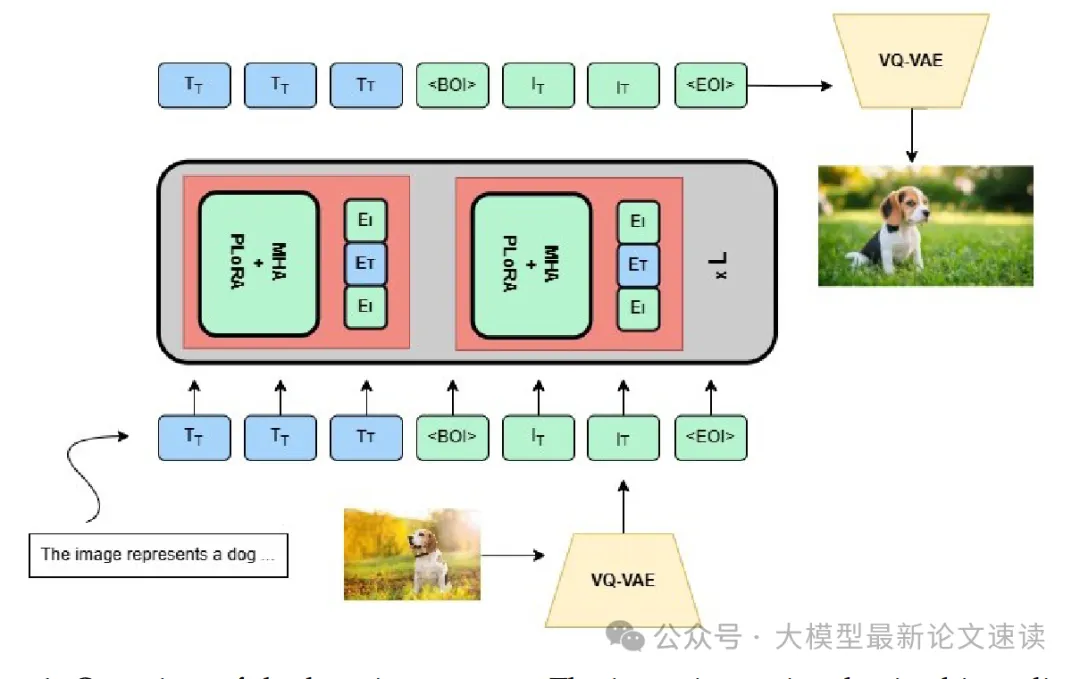
然后采用了Partial LoRA的策略,仅对新增的图像模态的token进行低秩适配(LoRA),而不影响原有文本token的参数。此方法完整地保留了模型原有的语言生成能力。
三、基于GW距离的参数初始化
Gromov-Wasserstein距离是一种用于比较不同度量空间之间概率分布的距离度量,定义如下:

现在我已知文本参数分布(X空间),想要初始化图像参数(Y空间),按照作者提出的GW距离最小化的init策略,上述公式的直观理解为:不要求Y与X重叠,但要求Y内分布的形状尽可能与X相同
这样的初始化方法能充分利用已知的文本信息,使模型快速收敛(如果是直接复制文本参数,也许会因为模型参数完全一致而造成性能退化)
四、两阶段持续微调
这里是一个常规操作:先在低分辨率(256×256)图像上做训练,帮助模型初步对齐文本和图像模态;然后在高分辨率(512×512)图像上继续训练,进一步提升生成图像的质量。这种分阶段训练方法不仅提高了生成图像的保真度,还确保了模型在不同分辨率下的适应性
实验效果
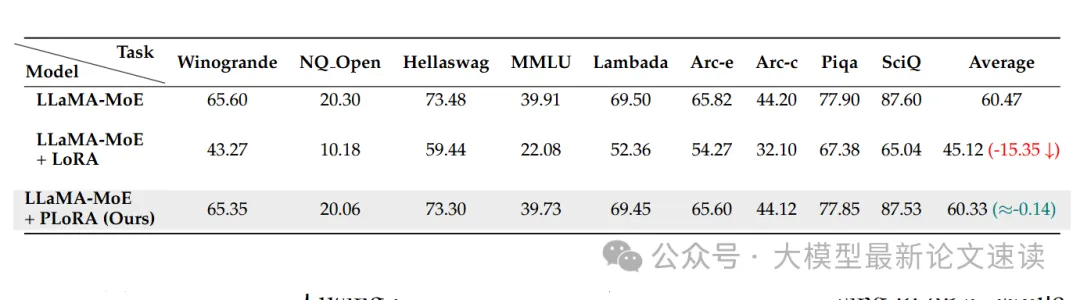
一、语言能力保留
常规的LoRA训练会让模型文本能力降低25%,而使用PLoRA的实验只下降了0.2%
二、图像生成质量
实验组在MSCOCO等基准上实现了与传统LoRA方法相当的高质量图像生成效果,甚至以750万训练样本实现了与4亿图像训练的潜在扩散模型相媲美的表现

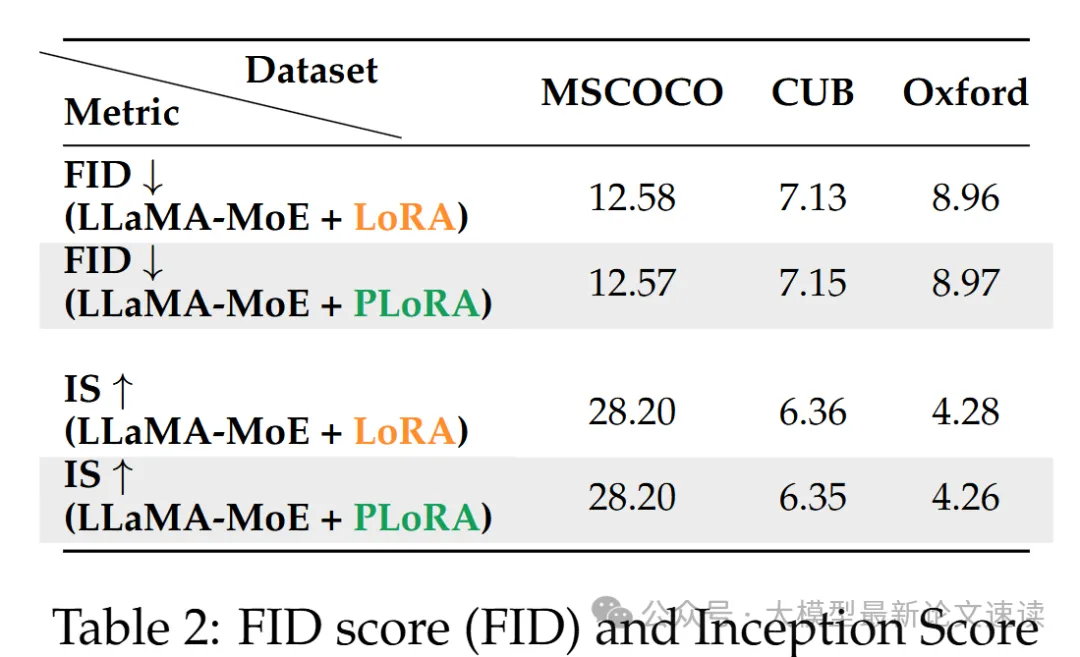
三、计算成本
由于利用了专家冗余,并且使用了PLoRA高效微调方法,相较于主流的增加图像编解码器,本文方法新增参数仅为原始方法的1/875,训练时间显著减少
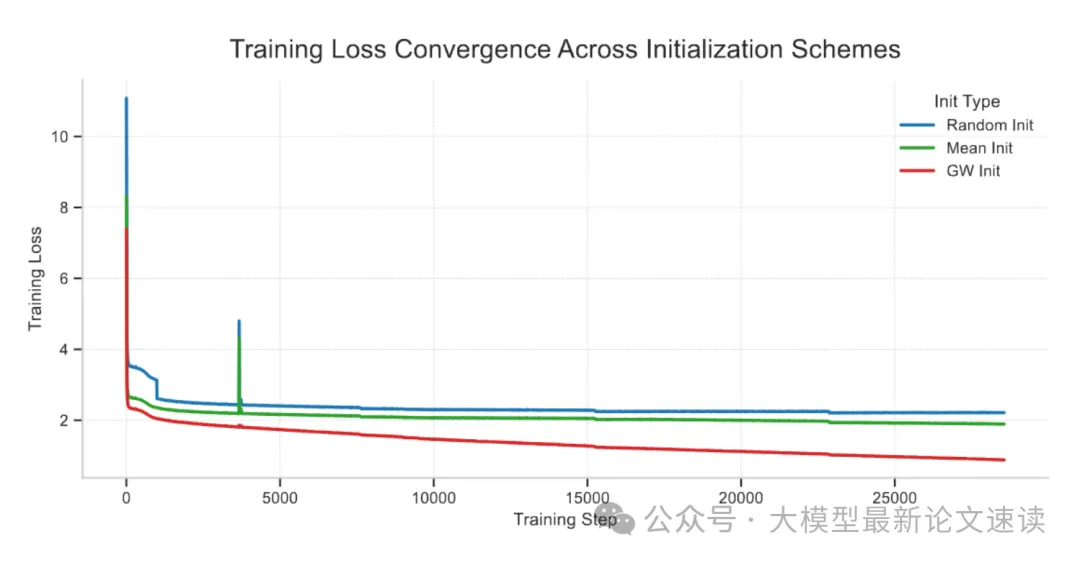
四、GW初始化消融
训练过程中的loss曲线明显优于其他初始化方法
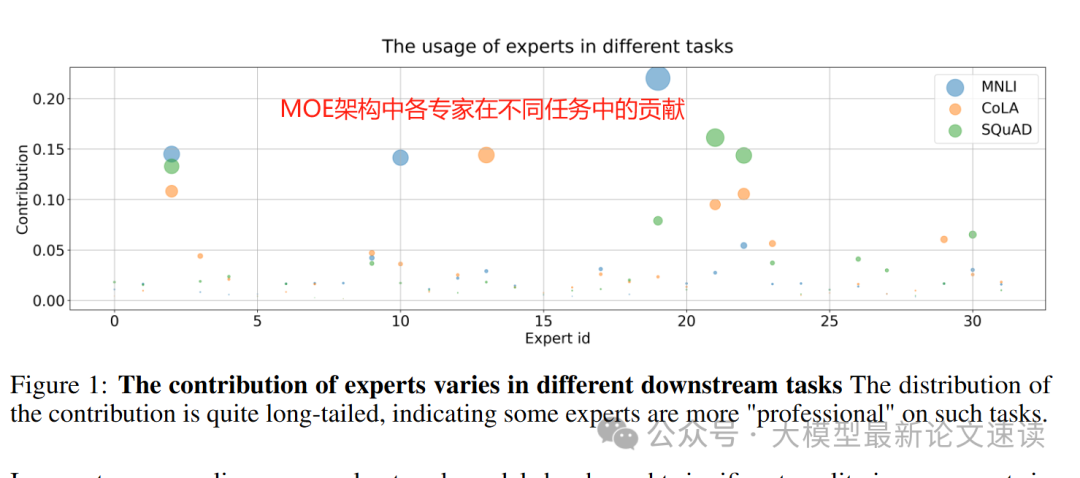
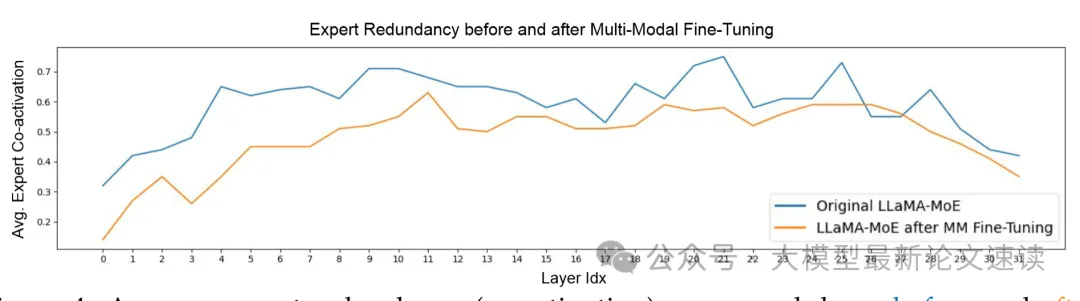
五、专家冗余变化
各层的专家冗余明显减少,表明对冗余的参数空间做了有效利用
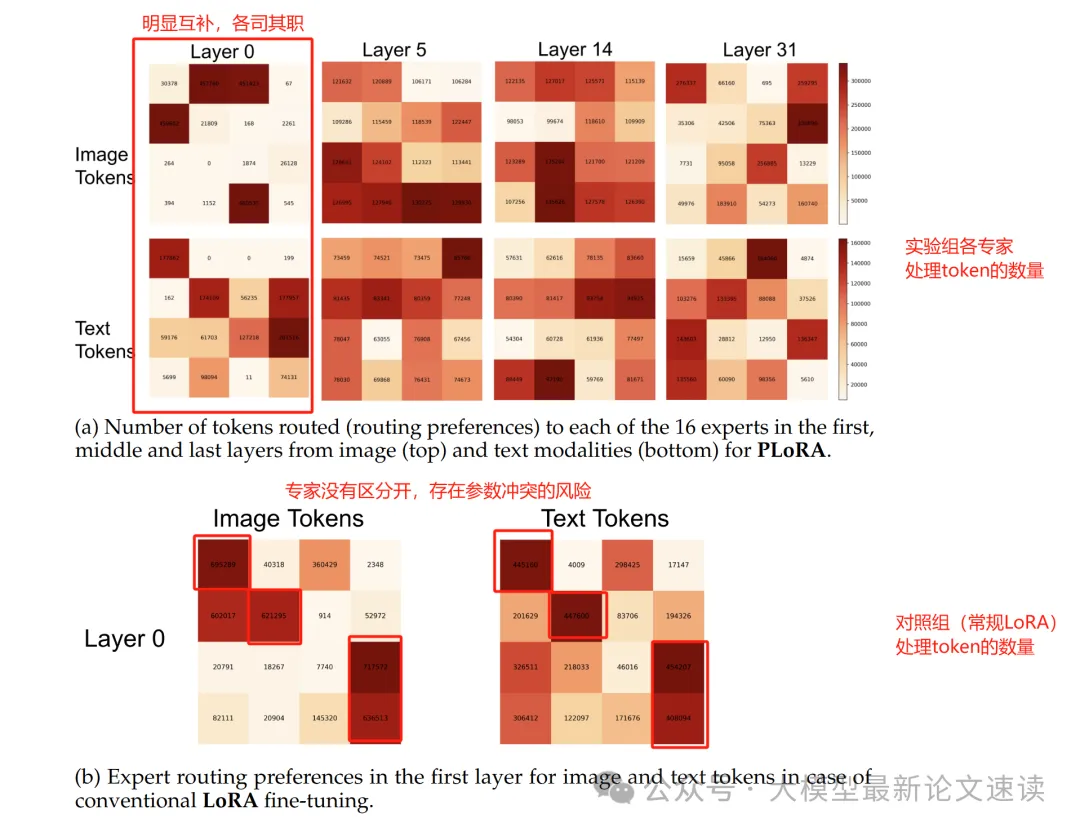
分析MOE各专家激活后处理token的数量,发现实验组更能做到“各司其职”,这也说明了对冗余专家的利用,这对于持续训练大有裨益


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









