






论文标题
Beyond Semantics: Rediscovering Spatial Awareness in Vision-Language Models
论文地址
https://arxiv.org/pdf/2503.17349
代码地址
https://user074.github.io/respatialaware/
作者背景
纽约市立大学
动机
视觉-语言模型(VLMs)近年来在处理多模态任务(如图像描述和视觉问答)方面取得了显著进展,但它们在空间推理任务中的表现却一直很差。尽管VLMs能够成功识别物体(例如通过图像分类或描述),但它们在理解物体之间的空间关系时却经常出错,比如无法区分物体的相对位置(例如“左”与“右”)。即VLMs存在“语义处理”能力强,而“空间处理”能力弱的问题
于是作者探索了为什么VLMs会在空间推理方面失败,并提出了能够增强空间感知能力的改进方法
现象
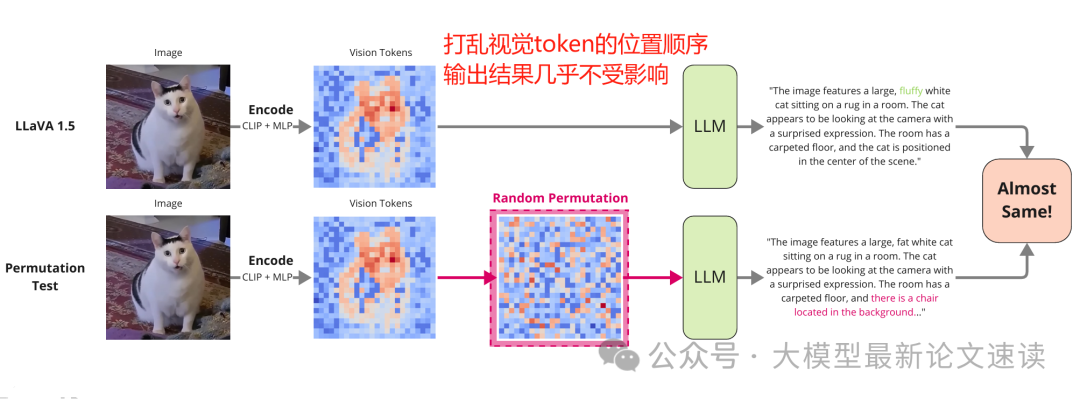
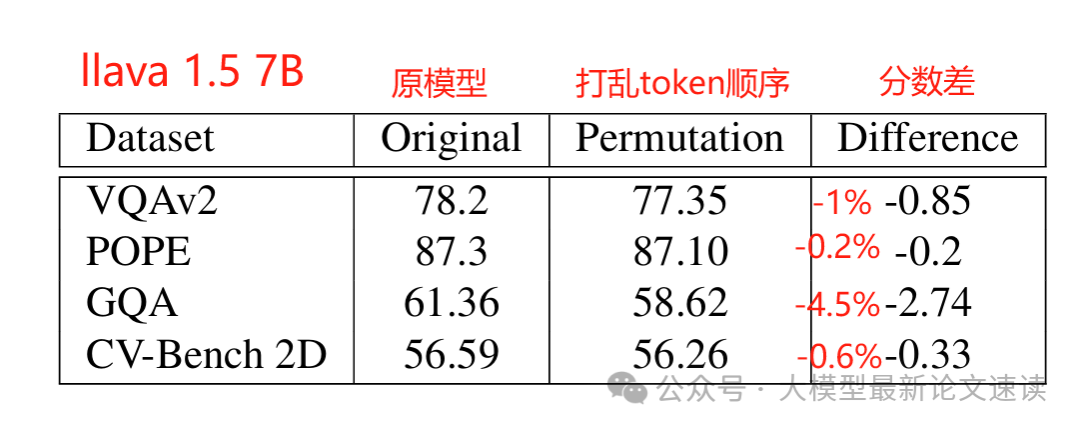
一、token乱序测试
如果位置顺序对空间推理很重要,那么随机打乱视觉token的顺序应该会显著降低模型性能。但实验结果表明,这样的操作对模型的影响非常小,表明VLMs对token顺序不敏感,呈现出“词袋模型”倾向
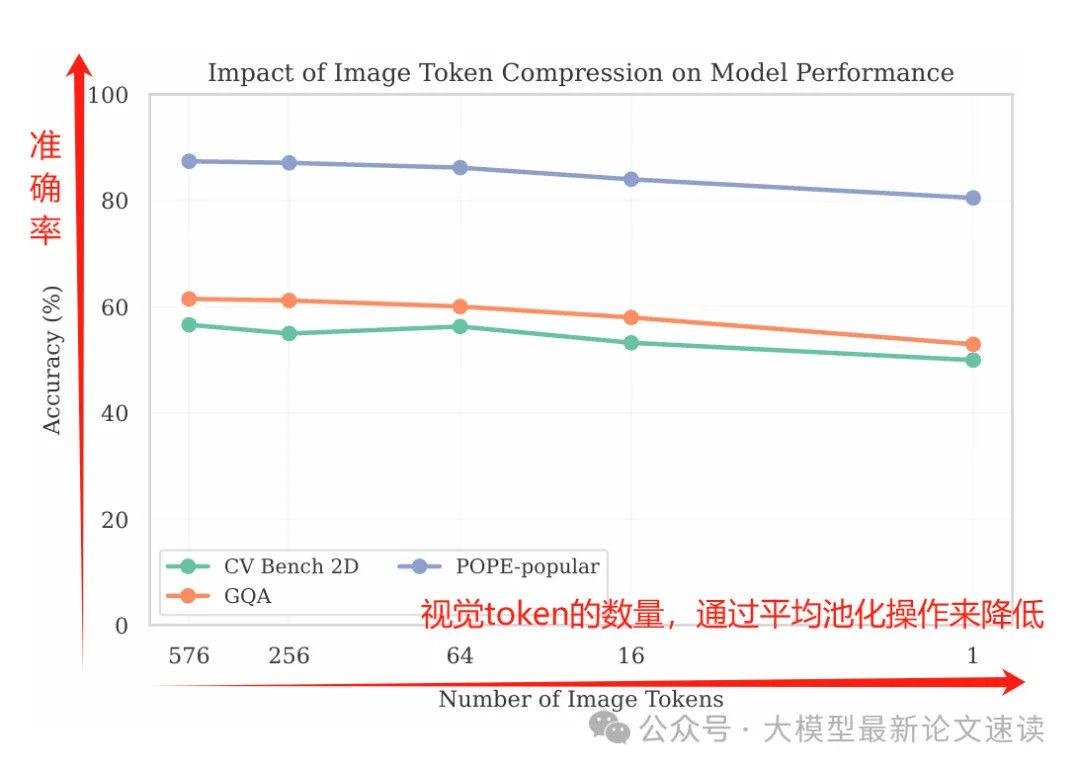
二、空间压缩测试
如果细粒度的空间信息很重要,那么通过池化大幅压缩token length维度,会导致模型性能显著降低。但实验结果表明,即使将视觉embedding的维度从576减少到1,性能下降也非常有限,这表明在当前的VLMs中,空间信息对结果并没有多大贡献
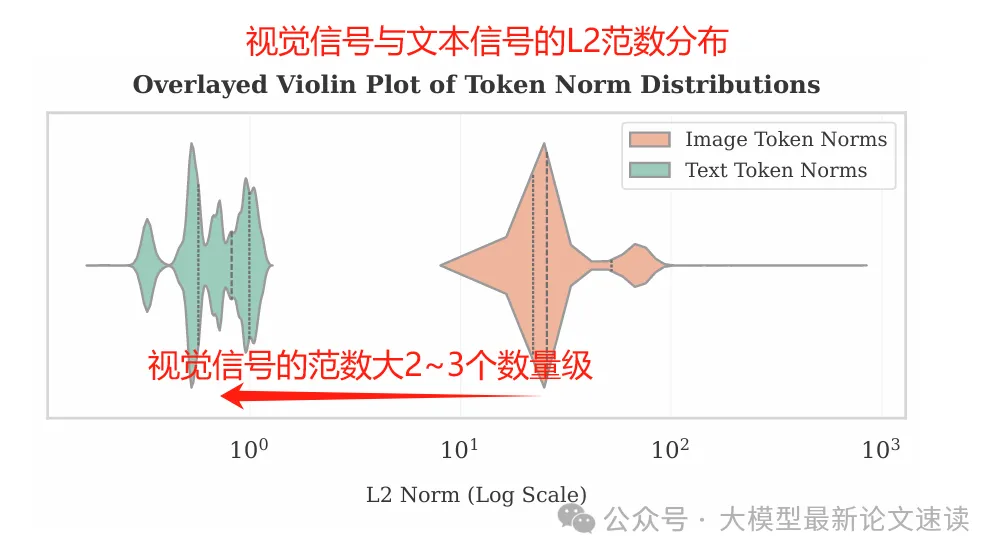
原因分析
实验发现,视觉embedding的范数通常比文本embedding的范数大1到3个数量级,此外作者也通过数学推导证明了此现象的普遍性:
这种巨大的范数差异导致位置编码在注意力机制中被掩盖。回顾llava架构,图像信号与文字信号在对齐之后一并送入语言模型:
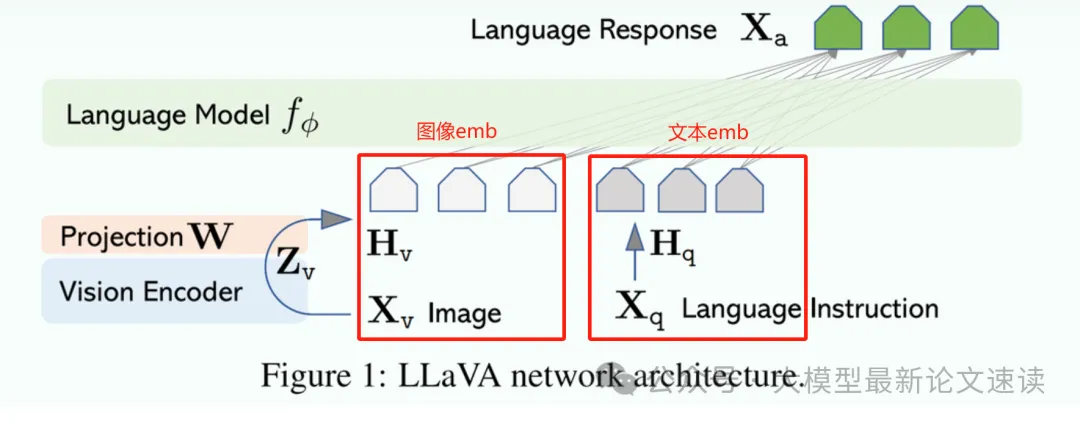
此时由于图像emb的范数更大,计算自注意力的计算结果便会有显著差异:

而在正常的模型训练过程中,模型会学着去适应两种信息的差异,即把视觉key生成的注意分数缩放到文本key对应的分数水平。在另一项研究中也发现,放缩比例约为1:4
为了考察这样的缩放如何影响位置编码的独特性,我现在开始推导注意力对位置信息的偏导数:
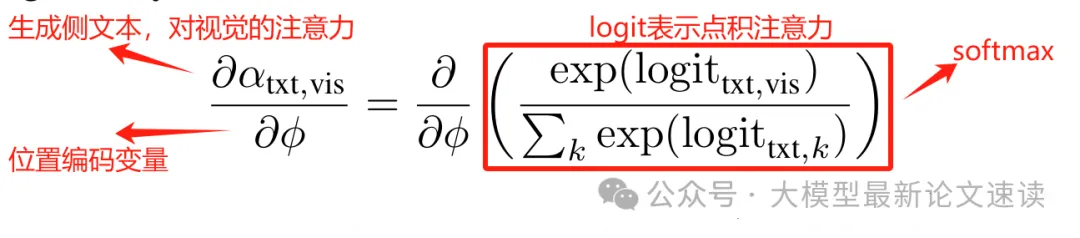
令上面红框中分母为U,分子为V,U和V都是关于Φ的函数:
U 视觉 = e x p ( l o g i t 文本 _ 视觉 ) U k = e x p ( l o g i t 文本 _ k ) V = Σ k e x p ( l o g i t 文本 _ k ) = Σ k U k \begin{array}{l} U_{视觉}=exp(logit_{文本\_视觉}) \\ U_{k}=exp(logit_{文本\_k}) \\ V=\Sigma_k{exp(logit_{文本\_k})} =\Sigma_k{U_k}\\ \end{array} U视觉=exp(logit文本_视觉)Uk=exp(logit文本_k)V=Σkexp(logit文本_k)=ΣkUk
根据指数函数求导的性质,有:
U 视觉 ′ = U 视觉 ⋅ l o g i t 文本 _ 视觉 ′ U k ′ = U k ⋅ l o g i t 文本 _ k ′ V ′ = ( Σ k U k ) ′ = Σ k ( U k ⋅ l o g i t 文本 _ k ′ ) \begin{array}{l} U_{视觉}' = U_{视觉}·logit_{文本\_视觉}' \\ U_{k}' = U_{k}·logit_{文本\_k}' \\ V' = (\Sigma_k{U_k})'= \Sigma_k({U_k·logit_{文本\_k}'}) \\ \end{array} U视觉′=U视觉⋅logit文本_视觉′Uk′=Uk⋅logit文本_k′V′=(ΣkUk)′=Σk(Uk⋅logit文本_k′)
然后便可以从分式函数的求导性质出发,推导视觉注意力对位置信息的偏导(变化趋势):
V U 视觉 ′ − U 视觉 V ′ V 2 = V ⋅ U 视觉 ⋅ l o g i t 文本 _ 视觉 ′ − U 视觉 ⋅ Σ k ( U k ⋅ l o g i t 文本 _ k ′ ) V 2 = U 视觉 V ⋅ l o g i t 文本 _ 视觉 ′ − U 视觉 V ⋅ Σ k ( U k ⋅ l o g i t 文本 _ k ′ ) V = U 视觉 V ⋅ l o g i t 文本 _ 视觉 ′ − U 视觉 V ⋅ Σ k ( U k V ⋅ l o g i t 文本 _ k ′ ) = U 视觉 V ( l o g i t 文本 _ 视觉 ′ − Σ k ( U k V ⋅ l o g i t 文本 _ k ′ ) ) = A t t e n t i o n 文本 _ 视觉 ⋅ ( l o g i t 文本 _ 视觉 ′ − 某个全局信息 ) \begin{array}{l} \frac{VU_{视觉}'-U_{视觉}V'}{V^2} \\ =\frac{V· U_{视觉}·logit_{文本\_视觉}'-U_{视觉}·\Sigma_k({U_k·logit_{文本\_k}'})}{V^2} \\ =\frac{U_{视觉}}{V}·logit_{文本\_视觉}'-\frac{U_{视觉}}{V}·\frac{\Sigma_k{(U_k·logit_{文本\_k}')}}{V} \\ =\frac{U_{视觉}}{V}·logit_{文本\_视觉}'-\frac{U_{视觉}}{V}·\Sigma_k{(\frac{U_k}{V}·logit_{文本\_k}')} \\ =\frac{U_{视觉}}{V}(logit_{文本\_视觉}'-\Sigma_k{(\frac{U_k}{V}·logit_{文本\_k}')}) \\ =Attention_{文本\_视觉} ·(logit_{文本\_视觉}' - 某个全局信息) \end{array} V2VU视觉′−U视觉V′=V2V⋅U视觉⋅logit文本_视觉′−U视觉⋅Σk(Uk⋅logit文本_k′)=VU视觉⋅logit文本_视觉′−VU视觉⋅VΣk(Uk⋅logit文本_k′)=VU视觉⋅logit文本_视觉′−VU视觉⋅Σk(VUk⋅logit文本_k′)=VU视觉(logit文本_视觉′−Σk(VUk⋅logit文本_k′))=Attention文本_视觉⋅(logit文本_视觉′−某个全局信息)
也就是说:位置信息的变化趋势,正比于视觉注意力本身的数值。当模型在训练过程中学会对视觉信号进行缩小时,视觉信号中的位置信息以二次函数的形式减弱
改进方法
一、embedding范数归一化
作者利用RMS归一化将视觉embedding的范数调整到与文本嵌入相近的范围,从而避免模型在训练过程中去缩放视觉信号,使得位置编码始终保持清晰
二、利用中间层特征
考虑到视觉编码器中间层的特征,一般会保留了更多的局部空间信息,作者尝试了将这些特征融入模型,以期望提升空间推理能力
实验结果
一、基准测试
测试各策略在多项公开数据集上的表现,衡量视觉任务上的综合能力

结果表明本文提出的两种方法都能提高模型视觉理解任务的表现
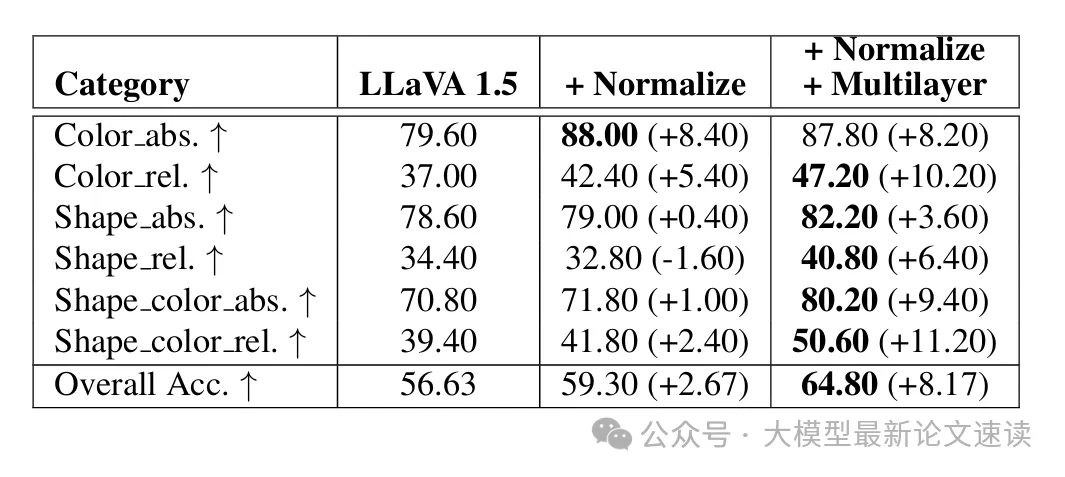
二、空间感知专项测试
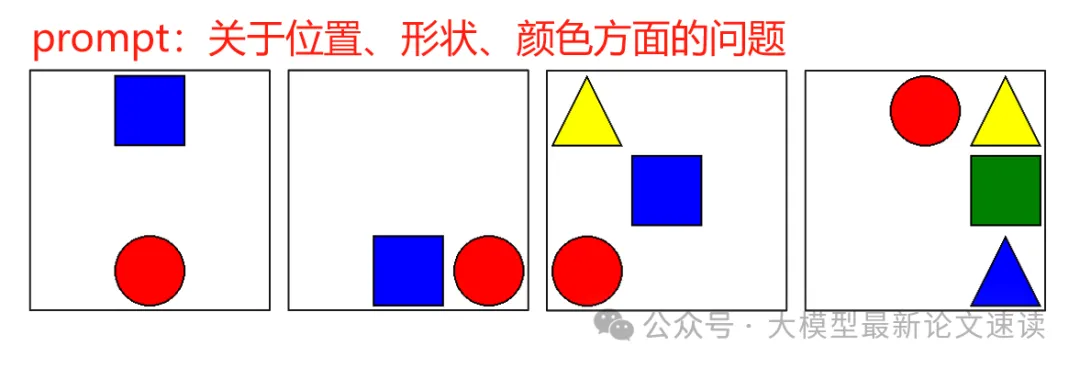
合成了专门用于测试VLMs空间能力的测试集,包含不同数量的对象(2到6个),并针对每张图像系统地提出了结合语义(颜色、形状)和空间(绝对位置、相对位置)属性的问题,如下图所示:
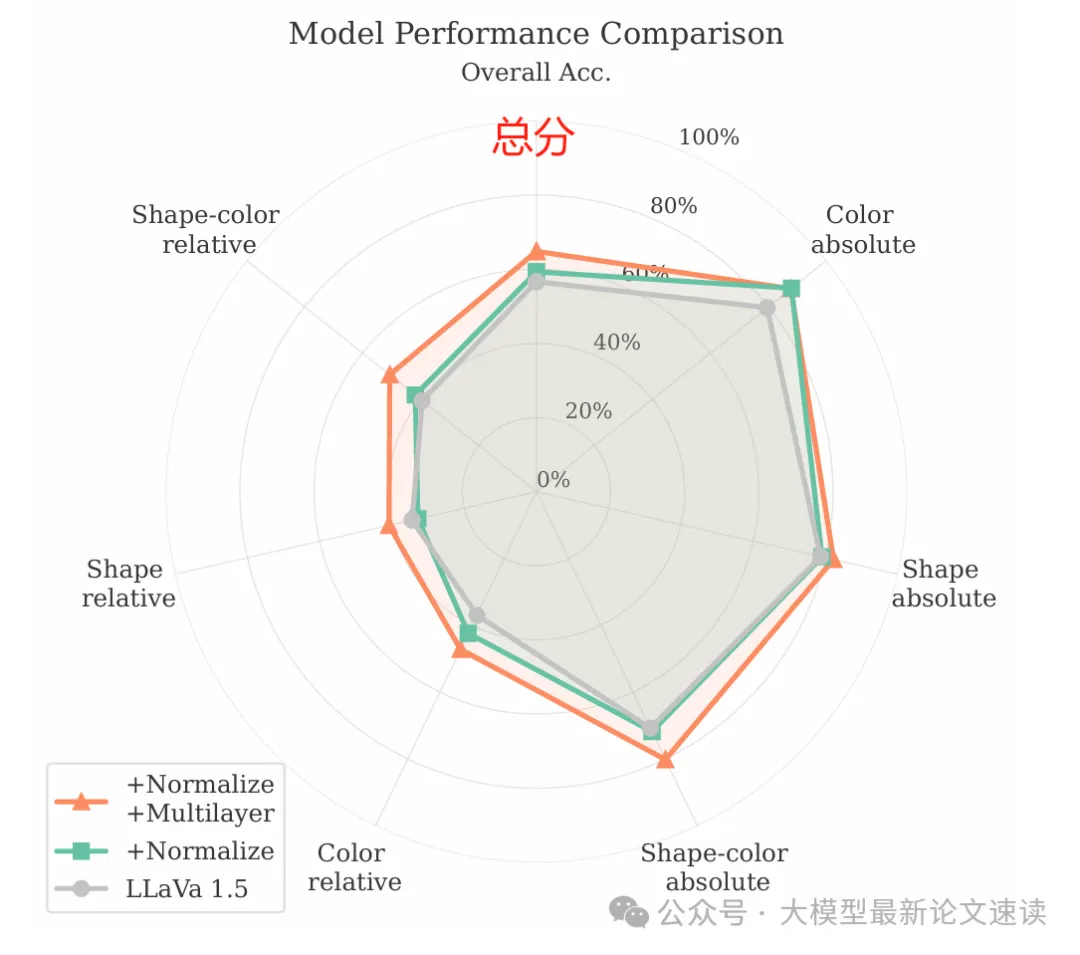
测试结果如下所示,可见本文提出来的两种方法都全面地提升了模型在空间感知方面的能力
三、注意力可视化

归一化模型的注意力图更加集中,显示出对相关位置token的明确关注。而归一化加中间层特征模型的注意力图则更加稀疏,显示出对特定位置区域的高选择性关注。
归一化模型的注意力熵高于原始模型,表明其在空间区域的探索上更加广泛和均匀。而归一化加中间层特征模型的注意力熵最低,表明其对特定空间区域的关注更加集中。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









