






论文标题
KV-Distill: Nearly Lossless Learnable Context Compression for LLMs
论文地址
https://arxiv.org/pdf/2503.10337
代码地址
官方仓库:https://github.com/vnchari/kv-distill
AI复现:https://github.com/guoqixin1/kv-distill
作者背景
约翰斯·霍普金斯大学,微软
同话题文章回顾
前言
KV-Cache是当前常用的推理加速手段,通过空间换时间的方式提高大模型推理速度。然而这一置换也导致了严重的显存开销,尤其是在长上下文场景下,部署成本极大。于是作者想要舍弃掉部分token的kv缓存,然后通过蒸馏的方式让模型保持原本性能
相关工作:H2O kv驱逐算法
有一篇类似的前置工作:https://arxiv.org/pdf/2306.14048
它先是证明了:即使是稠密模型,在推理时也仅由少数重要token贡献大部分价值(这些token被称为Heavy Hitter, H2),并提出了kv驱逐算法,简单来说有以下实现方式:
- H2I (H2 question-Independent)
在不知道未来问题的情况下,对上下文KV-Cache进行压缩:当超过缓存预算时,舍弃(驱逐)累积注意力最低的token - H2A (H2 question-Aware)
在知道未来问题的情况下,对上下文KV-Cache进行压缩:当超过缓存预算时,舍弃(驱逐)问题token对上下文token的注意力最低的token
除了通过上述两种方法保存重要token外,还需要保留一部分最近产生的token,相当于引入“邻近的信息也很重要”这一先验知识

本文方法
相对于上述kv驱逐算法,主要有以下改动:
- 使用一个可学习的FFN层计算每个token被保留下来的概率
- 在Attention Block中的Q和O矩阵旁添加Lora分支,这些新参数用于帮助模型适应:【基于部分token得到最终结果】
说明:在某些实现中,注意力计算完成后,多头的结果拼接在一起,然后会乘以一个矩阵,此矩阵被称为O

- 模型需要计算两个输出分布:一是所有token经过原始主干模块的输出(相当于教师模型输出),二是被FFN选中的token经过带Lora模块的输出(相当于学生模型输出),如下图所示
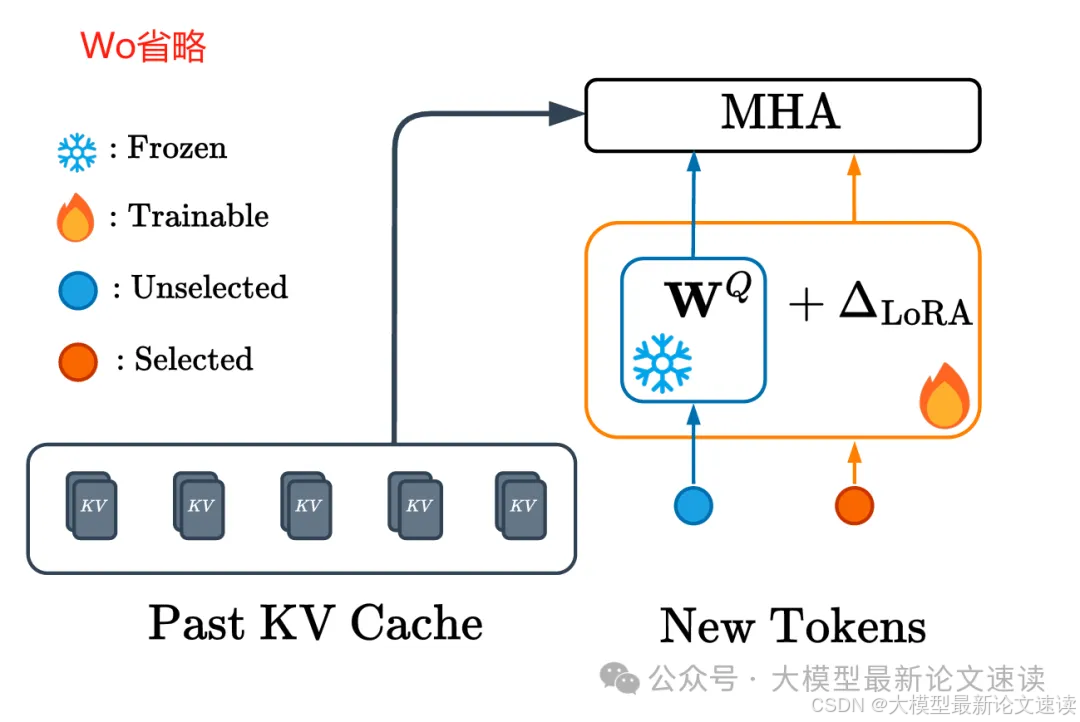
- 模型训练的目标为:最小化上述两个分布差异;整个过程中只有FFN和Lora模块需要更新,其他部分都冻结参数

消融实验结论:
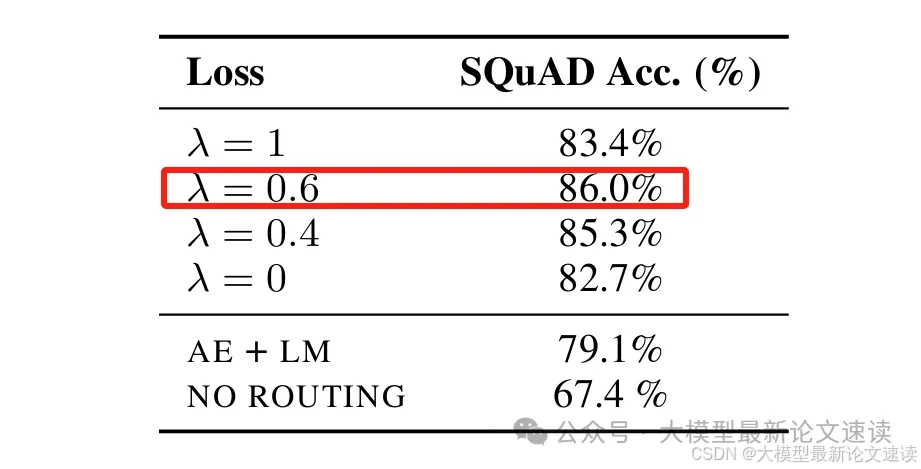
同时使用正向和反向 KL 散度的组合目标函数能够获得最佳性能。仅使用正向或反向 KL 散度的模型性能显著下降,而使用自编码和语言建模目标(如 ICAE 和 DODO)的模型性能则更差
实验效果
一、大海捞针测试
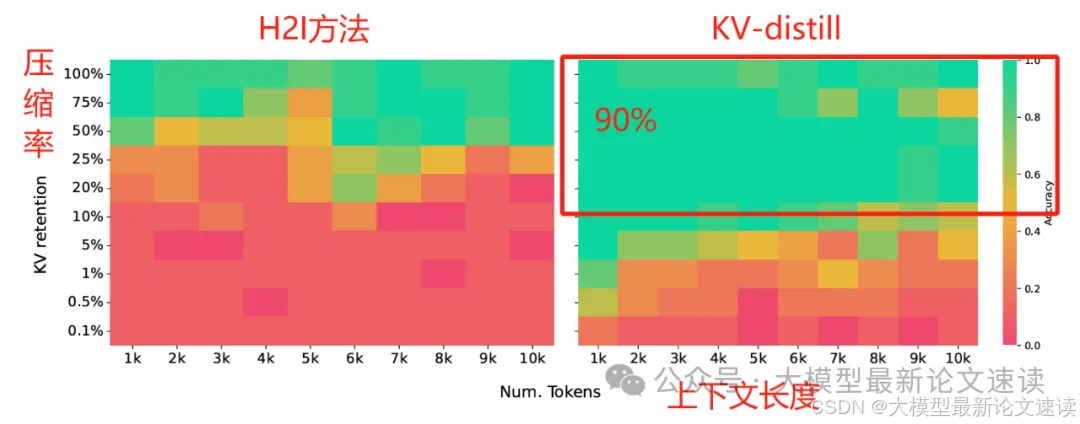
与H2I方法相比,KV-distill保持了较好的长上下文检索能力,即使是在压缩率90%时也能保持较好的准确性
二、抽取式问答测试
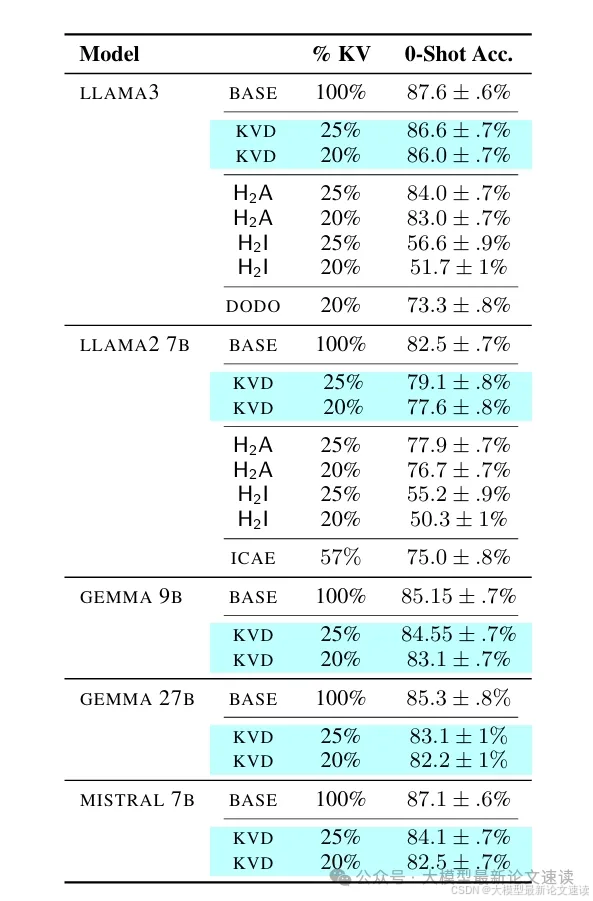
应用到各个模型中,长文本抽取式问答的zero-shot准确率均好于对照组
三、理解性问答测试
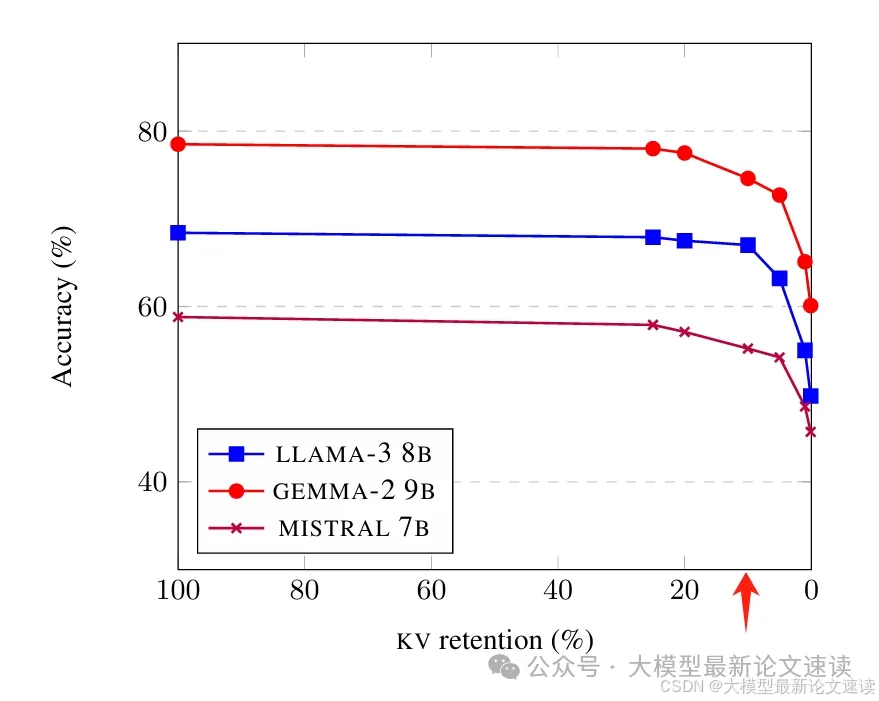
在长文本理解性问答测试中(需要深入理解上下文才能回答问题),KV-Distill方法即使是在90%的压缩率下,也保持了和原始模型相当的性能
四、摘要生成测试
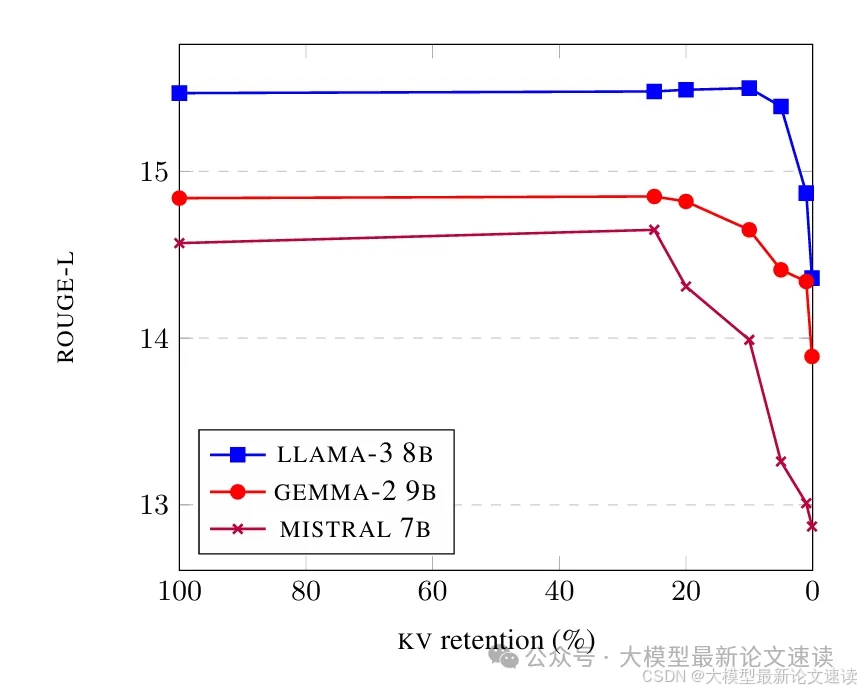
在长文本生成摘要的任务中,表现依然良好


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









